 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Evaluation of Multi-Agent Reinforcement Learning with Melting Pot
Jul 14, 2021
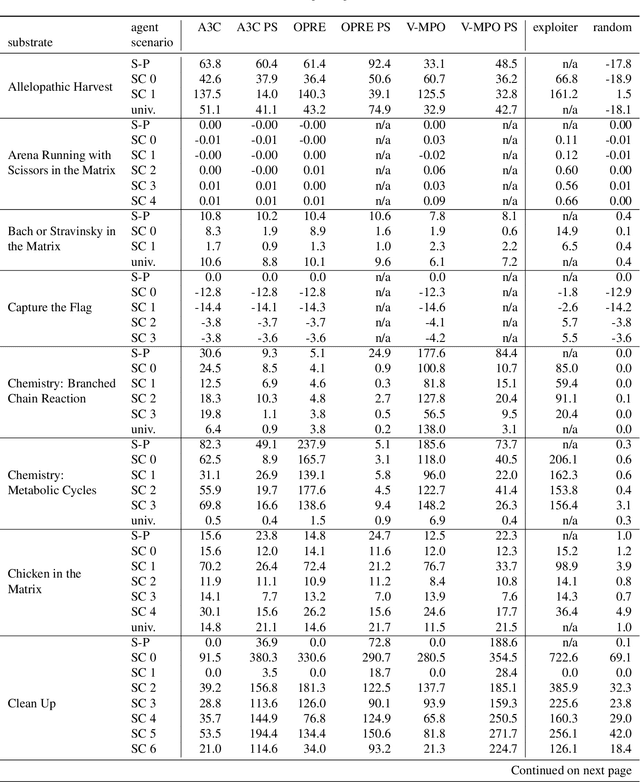
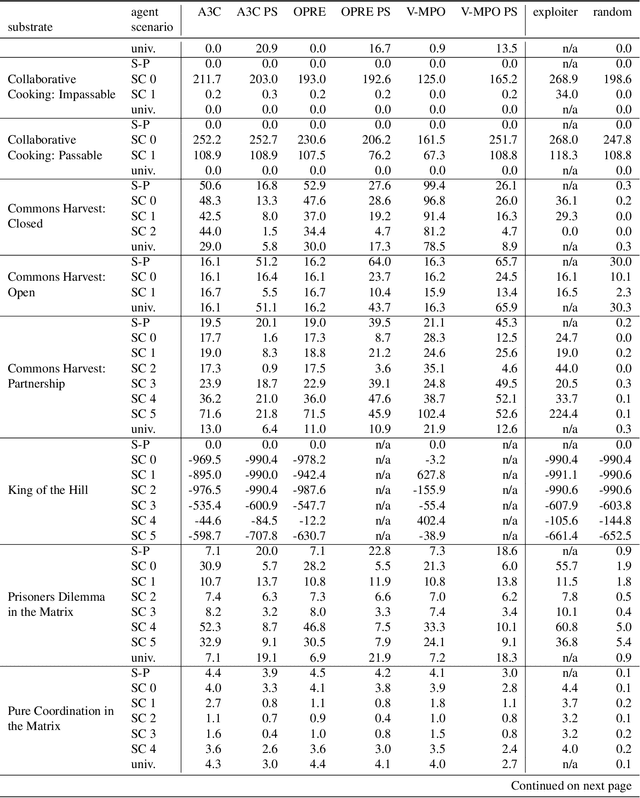
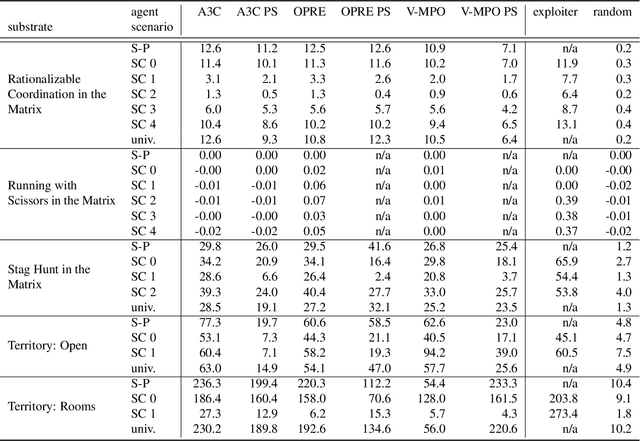
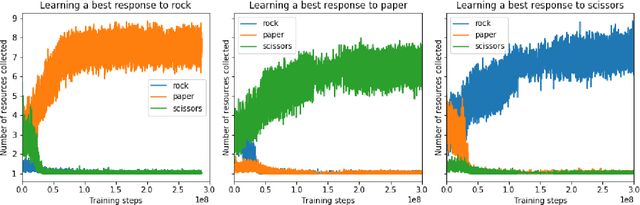
Existing evaluation suites for multi-agent reinforcement learning (MARL) do not assess generalization to novel situations as their primary objective (unlike supervised-learning benchmarks). Our contribution, Melting Pot, is a MARL evaluation suite that fills this gap, and uses reinforcement learning to reduce the human labor required to create novel test scenarios. This works because one agent's behavior constitutes (part of) another agent's environment. To demonstrate scalability, we have created over 80 unique test scenarios covering a broad range of research topics such as social dilemmas, reciprocity, resource sharing, and task partitioning. We apply these test scenarios to standard MARL training algorithms, and demonstrate how Melting Pot reveals weaknesses not apparent from training performance alone.
* Accepted to ICML 2021 and presented as a long talk; 33 pages; 9 figures
DeepMind Lab2D
Dec 12, 2020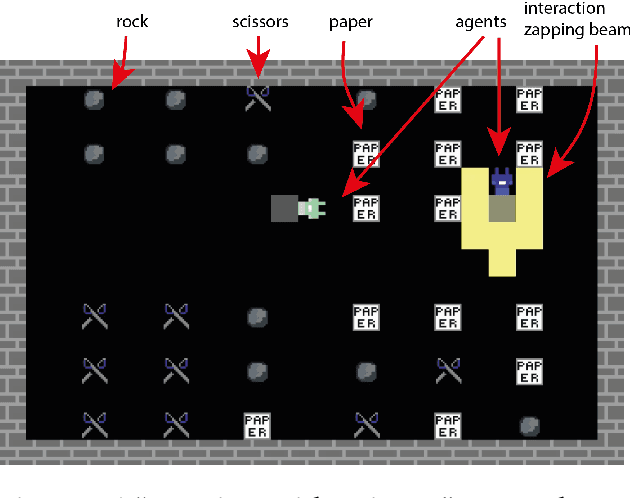
We present DeepMind Lab2D, a scalable environment simulator for artificial intelligence research that facilitates researcher-led experimentation with environment design. DeepMind Lab2D was built with the specific needs of multi-agent deep reinforcement learning researchers in mind, but it may also be useful beyond that particular subfield.
Human-level performance in first-person multiplayer games with population-based deep reinforcement learning
Jul 03, 2018Recent progress in artificial intelligence through reinforcement learning (RL) has shown great success on increasingly complex single-agent environments and two-player turn-based games. However, the real-world contains multiple agents, each learning and acting independently to cooperate and compete with other agents, and environments reflecting this degree of complexity remain an open challenge. In this work, we demonstrate for the first time that an agent can achieve human-level in a popular 3D multiplayer first-person video game, Quake III Arena Capture the Flag, using only pixels and game points as input. These results were achieved by a novel two-tier optimisation process in which a population of independent RL agents are trained concurrently from thousands of parallel matches with agents playing in teams together and against each other on randomly generated environments. Each agent in the population learns its own internal reward signal to complement the sparse delayed reward from winning, and selects actions using a novel temporally hierarchical representation that enables the agent to reason at multiple timescales. During game-play, these agents display human-like behaviours such as navigating, following, and defending based on a rich learned representation that is shown to encode high-level game knowledge. In an extensive tournament-style evaluation the trained agents exceeded the win-rate of strong human players both as teammates and opponents, and proved far stronger than existing state-of-the-art agents. These results demonstrate a significant jump in the capabilities of artificial agents, bringing us closer to the goal of human-level intelligence.
Psychlab: A Psychology Laboratory for Deep Reinforcement Learning Agents
Feb 04, 2018


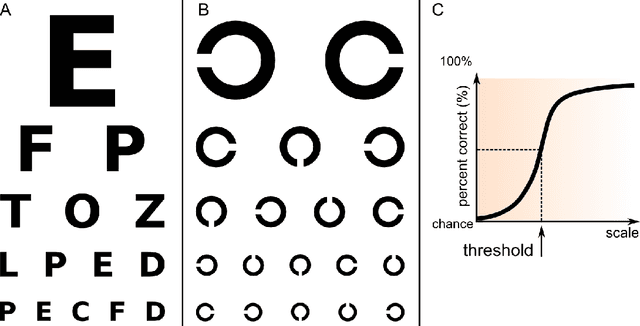
Psychlab is a simulated psychology laboratory inside the first-person 3D game world of DeepMind Lab (Beattie et al. 2016). Psychlab enables implementations of classical laboratory psychological experiments so that they work with both human and artificial agents. Psychlab has a simple and flexible API that enables users to easily create their own tasks. As examples, we are releasing Psychlab implementations of several classical experimental paradigms including visual search, change detection, random dot motion discrimination, and multiple object tracking. We also contribute a study of the visual psychophysics of a specific state-of-the-art deep reinforcement learning agent: UNREAL (Jaderberg et al. 2016). This study leads to the surprising conclusion that UNREAL learns more quickly about larger target stimuli than it does about smaller stimuli. In turn, this insight motivates a specific improvement in the form of a simple model of foveal vision that turns out to significantly boost UNREAL's performance, both on Psychlab tasks, and on standard DeepMind Lab tasks. By open-sourcing Psychlab we hope to facilitate a range of future such studies that simultaneously advance deep reinforcement learning and improve its links with cognitive science.
A multi-agent reinforcement learning model of common-pool resource appropriation
Sep 06, 2017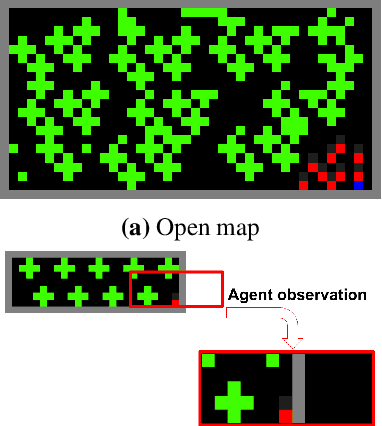
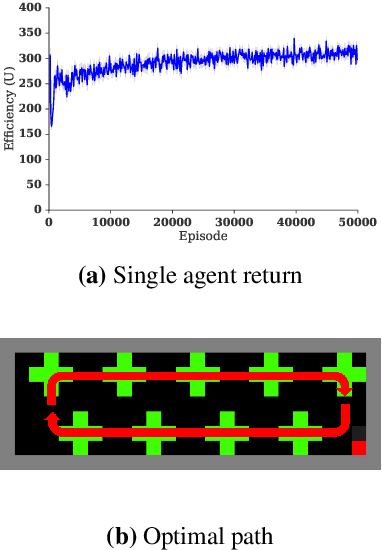
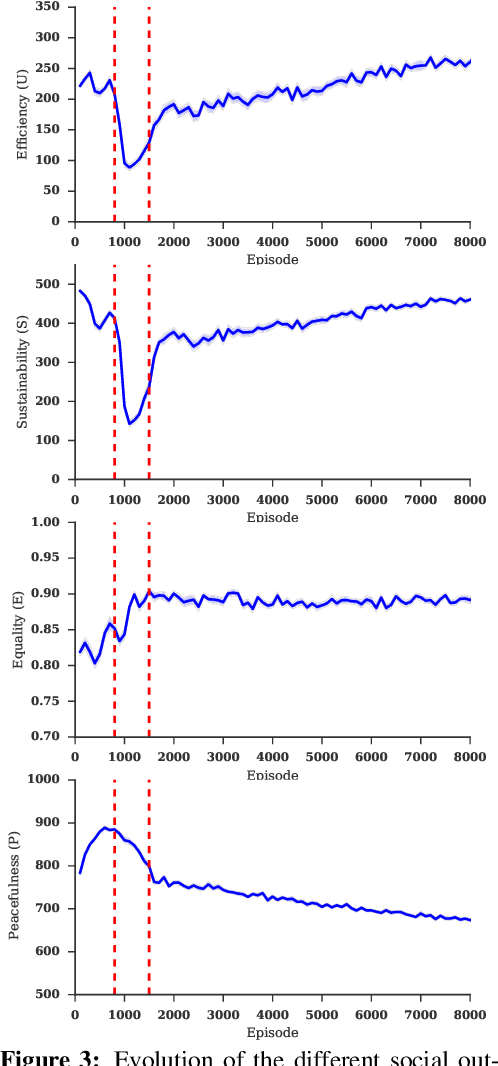
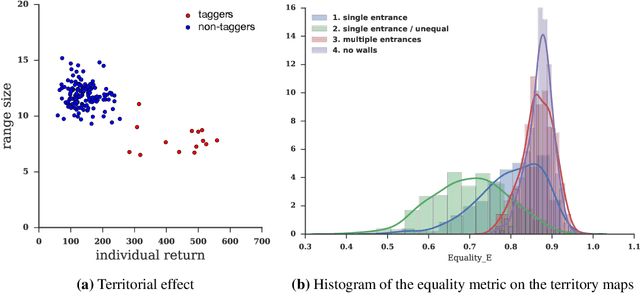
Humanity faces numerous problems of common-pool resource appropriation. This class of multi-agent social dilemma includes the problems of ensuring sustainable use of fresh water, common fisheries, grazing pastures, and irrigation systems. Abstract models of common-pool resource appropriation based on non-cooperative game theory predict that self-interested agents will generally fail to find socially positive equilibria---a phenomenon called the tragedy of the commons. However, in reality, human societies are sometimes able to discover and implement stable cooperative solutions. Decades of behavioral game theory research have sought to uncover aspects of human behavior that make this possible. Most of that work was based on laboratory experiments where participants only make a single choice: how much to appropriate. Recognizing the importance of spatial and temporal resource dynamics, a recent trend has been toward experiments in more complex real-time video game-like environments. However, standard methods of non-cooperative game theory can no longer be used to generate predictions for this case. Here we show that deep reinforcement learning can be used instead. To that end, we study the emergent behavior of groups of independently learning agents in a partially observed Markov game modeling common-pool resource appropriation. Our experiments highlight the importance of trial-and-error learning in common-pool resource appropriation and shed light on the relationship between exclusion, sustainability, and inequality.
DeepMind Lab
Dec 13, 2016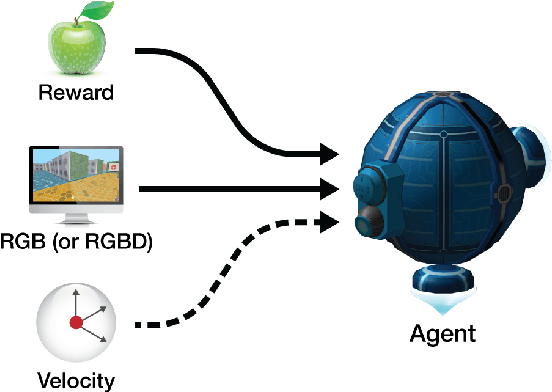
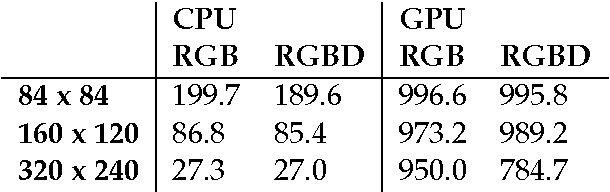
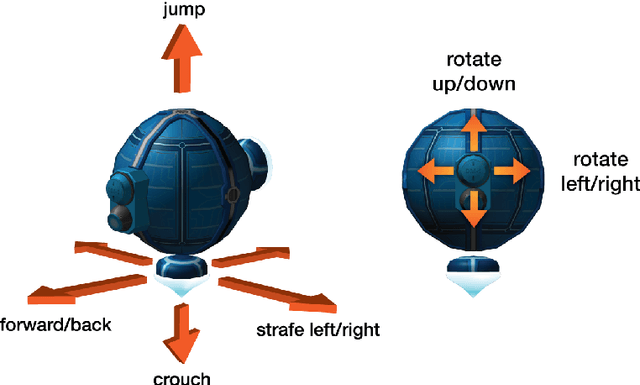

DeepMind Lab is a first-person 3D game platform designed for research and development of general artificial intelligence and machine learning systems. DeepMind Lab can be used to study how autonomous artificial agents may learn complex tasks in large, partially observed, and visually diverse worlds. DeepMind Lab has a simple and flexible API enabling creative task-designs and novel AI-designs to be explored and quickly iterated upon. It is powered by a fast and widely recognised game engine, and tailored for effective use by the research community.
Massively Parallel Methods for Deep Reinforcement Learning
Jul 16, 2015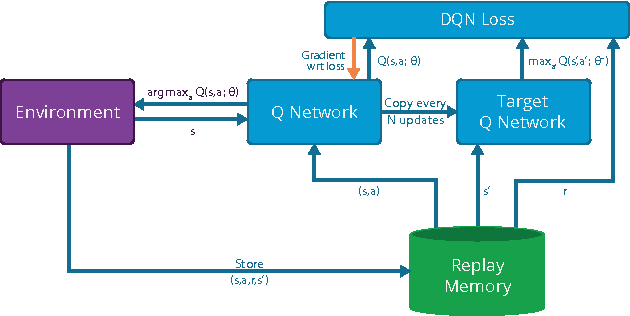
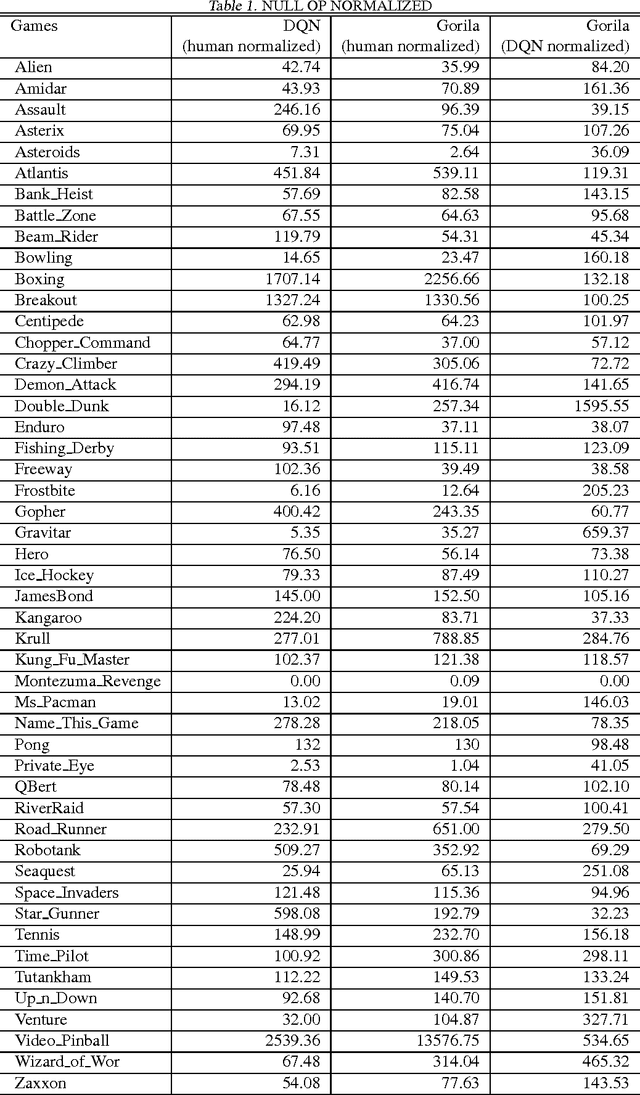
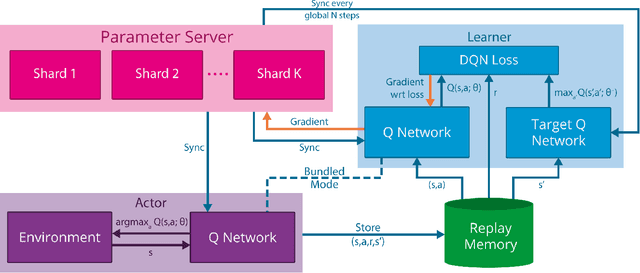
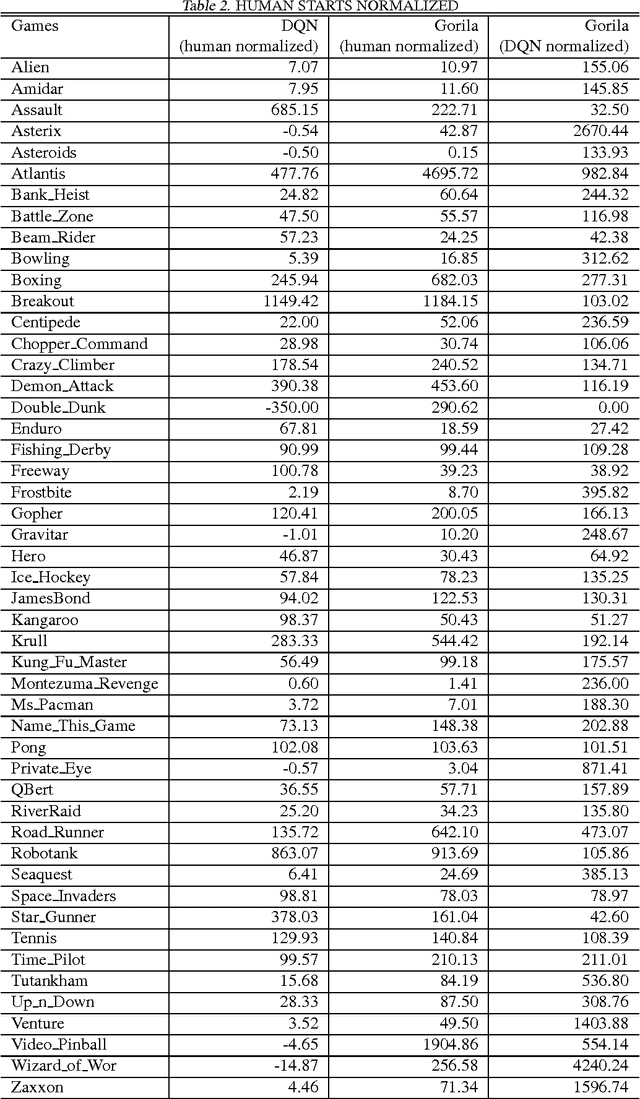
We present the first massively distributed architecture for deep reinforcement learning. This architecture uses four main components: parallel actors that generate new behaviour; parallel learners that are trained from stored experience; a distributed neural network to represent the value function or behaviour policy; and a distributed store of experience. We used our architecture to implement the Deep Q-Network algorithm (DQN). Our distributed algorithm was applied to 49 games from Atari 2600 games from the Arcade Learning Environment, using identical hyperparameters. Our performance surpassed non-distributed DQN in 41 of the 49 games and also reduced the wall-time required to achieve these results by an order of magnitude on most games.