 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning to achieve clinically applicable segmentation of head and neck anatomy for radiotherapy
Sep 12, 2018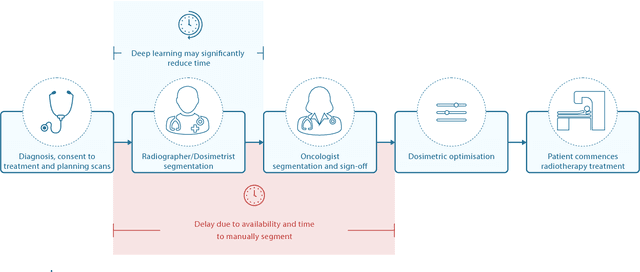
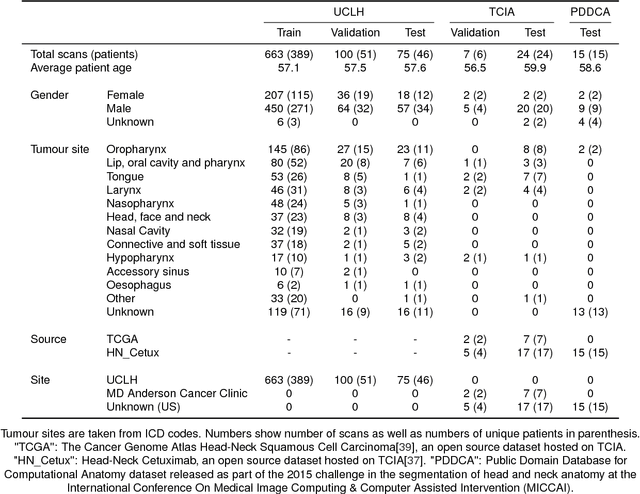
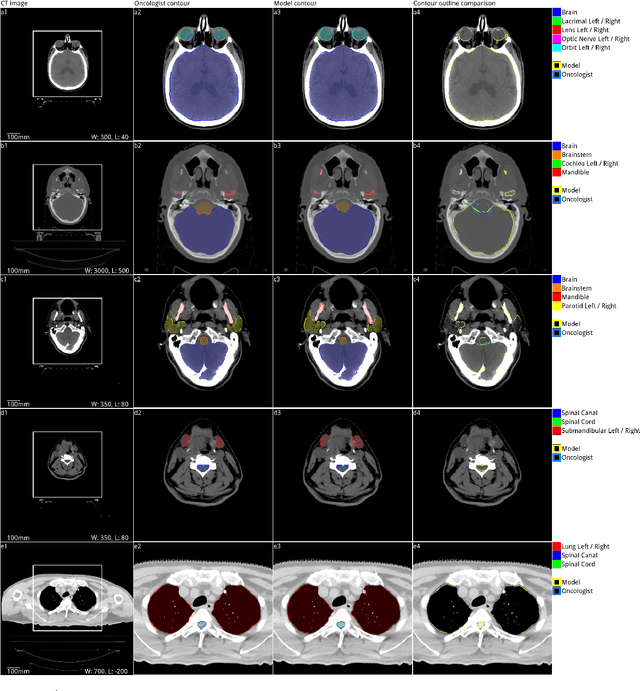
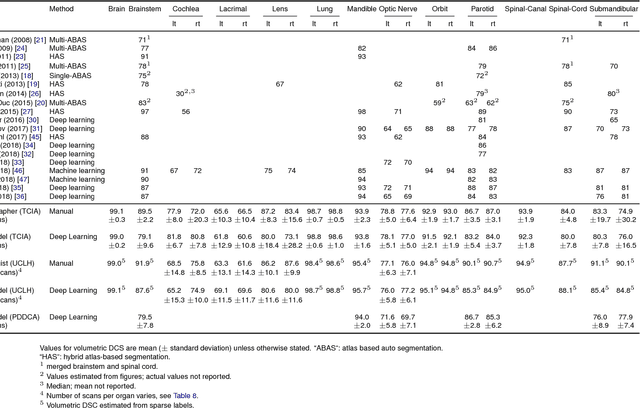
Over half a million individuals are diagnosed with head and neck cancer each year worldwide. Radiotherapy is an important curative treatment for this disease, but it requires manually intensive delineation of radiosensitive organs at risk (OARs). This planning process can delay treatment commencement. While auto-segmentation algorithms offer a potentially time-saving solution, the challenges in defining, quantifying and achieving expert performance remain. Adopting a deep learning approach, we demonstrate a 3D U-Net architecture that achieves performance similar to experts in delineating a wide range of head and neck OARs. The model was trained on a dataset of 663 deidentified computed tomography (CT) scans acquired in routine clinical practice and segmented according to consensus OAR definitions. We demonstrate its generalisability through application to an independent test set of 24 CT scans available from The Cancer Imaging Archive collected at multiple international sites previously unseen to the model, each segmented by two independent experts and consisting of 21 OARs commonly segmented in clinical practice. With appropriate validation studies and regulatory approvals, this system could improve the effectiveness of radiotherapy pathways.
The Kinetics Human Action Video Dataset
May 19, 2017
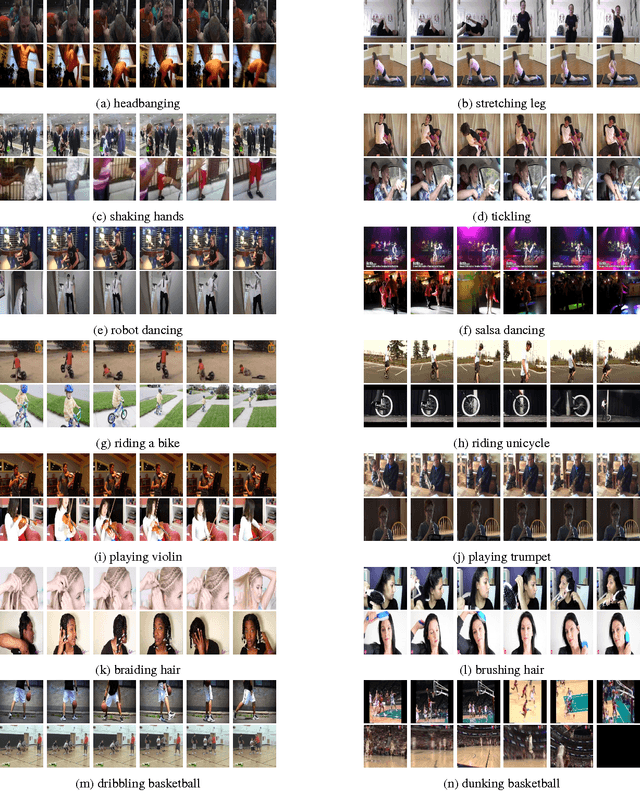
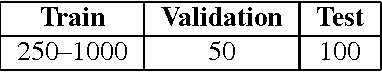
We describe the DeepMind Kinetics human action video dataset. The dataset contains 400 human action classes, with at least 400 video clips for each action. Each clip lasts around 10s and is taken from a different YouTube video. The actions are human focussed and cover a broad range of classes including human-object interactions such as playing instruments, as well as human-human interactions such as shaking hands. We describe the statistics of the dataset, how it was collected, and give some baseline performance figures for neural network architectures trained and tested for human action classification on this dataset. We also carry out a preliminary analysis of whether imbalance in the dataset leads to bias in the classifiers.
Teaching Machines to Read and Comprehend
Nov 19, 2015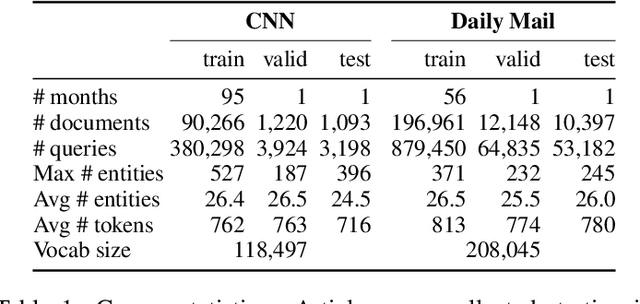
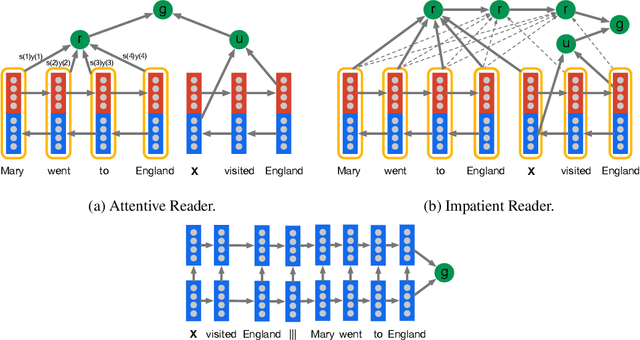
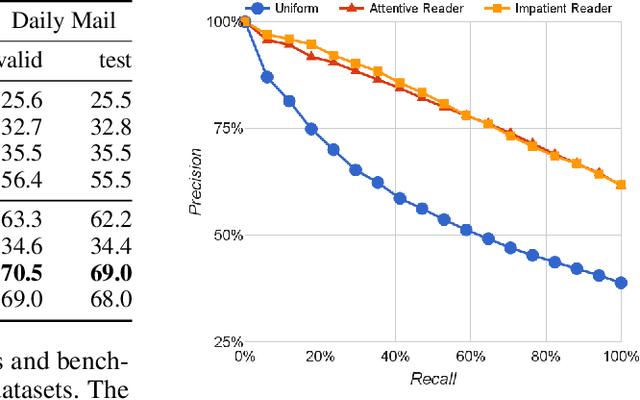

Teaching machines to read natural language documents remains an elusive challenge. Machine reading systems can be tested on their ability to answer questions posed on the contents of documents that they have seen, but until now large scale training and test datasets have been missing for this type of evaluation. In this work we define a new methodology that resolves this bottleneck and provides large scale supervised reading comprehension data. This allows us to develop a class of attention based deep neural networks that learn to read real documents and answer complex questions with minimal prior knowledge of language structure.
Learning to Transduce with Unbounded Memory
Nov 03, 2015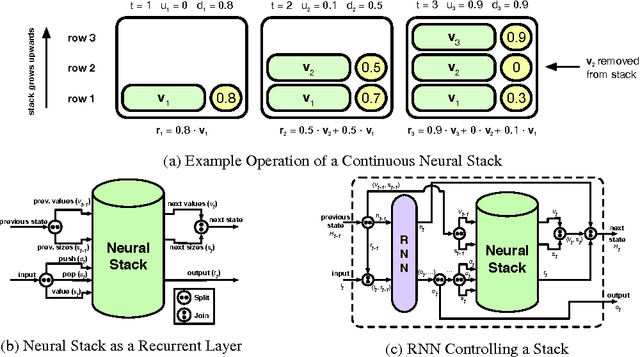

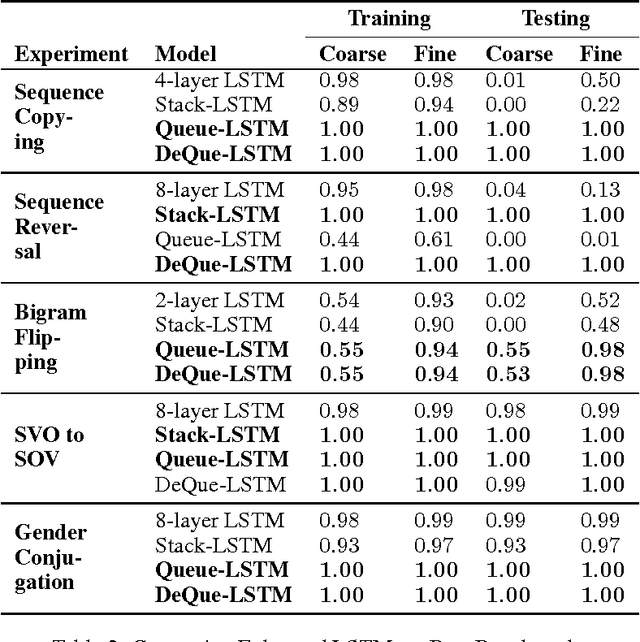
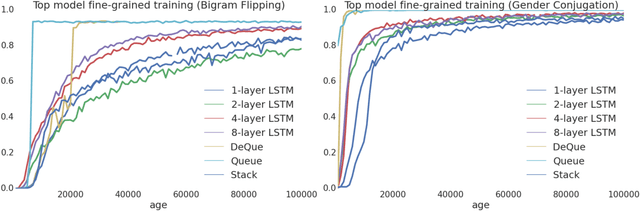
Recently, strong results have been demonstrated by Deep Recurrent Neural Networks on natural language transduction problems. In this paper we explore the representational power of these models using synthetic grammars designed to exhibit phenomena similar to those found in real transduction problems such as machine translation. These experiments lead us to propose new memory-based recurrent networks that implement continuously differentiable analogues of traditional data structures such as Stacks, Queues, and DeQues. We show that these architectures exhibit superior generalisation performance to Deep RNNs and are often able to learn the underlying generating algorithms in our transduction experiments.
Massively Parallel Methods for Deep Reinforcement Learning
Jul 16, 2015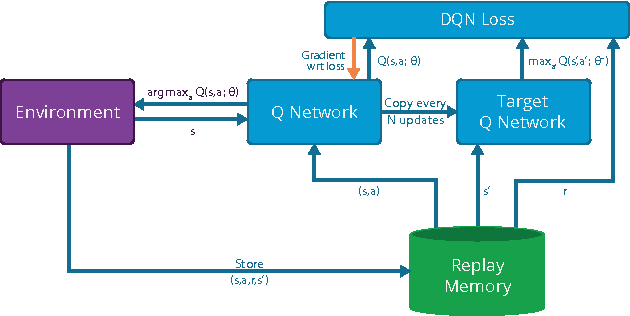
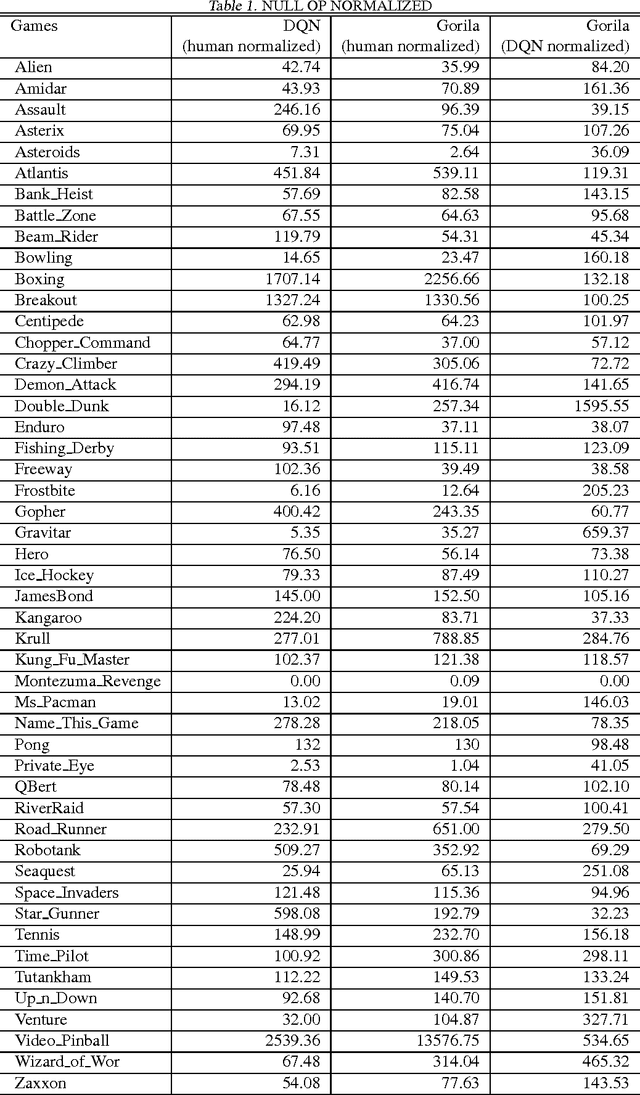
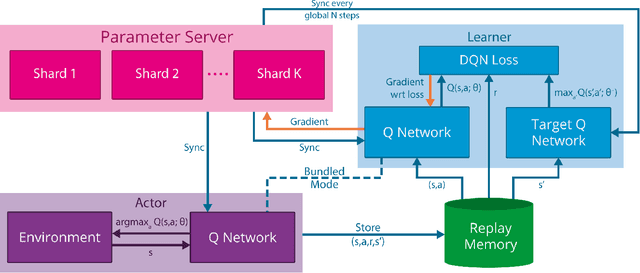
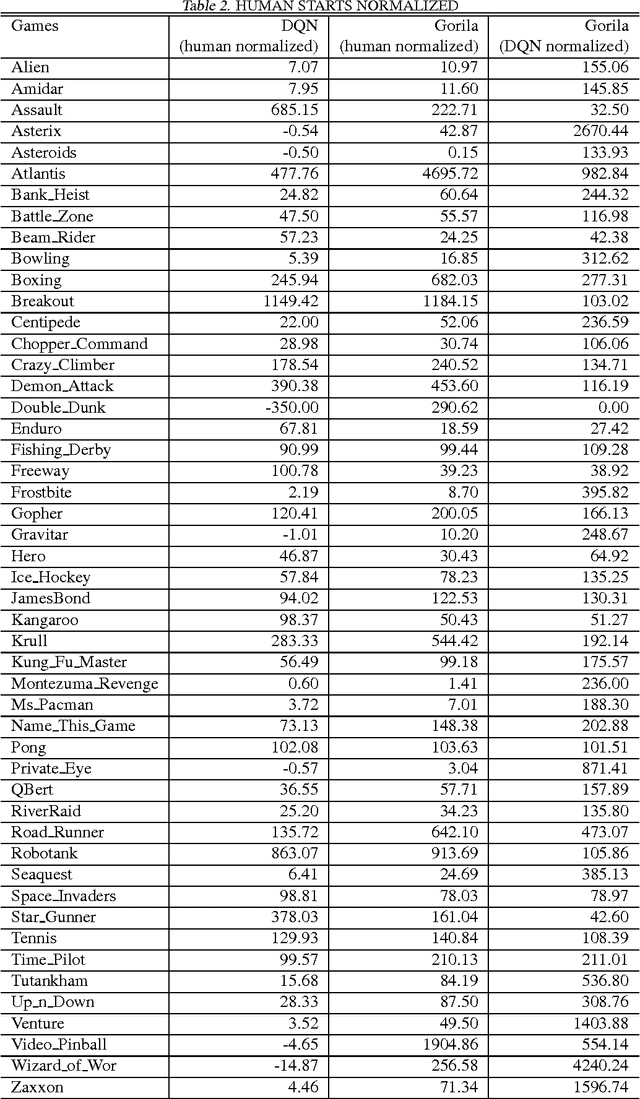
We present the first massively distributed architecture for deep reinforcement learning. This architecture uses four main components: parallel actors that generate new behaviour; parallel learners that are trained from stored experience; a distributed neural network to represent the value function or behaviour policy; and a distributed store of experience. We used our architecture to implement the Deep Q-Network algorithm (DQN). Our distributed algorithm was applied to 49 games from Atari 2600 games from the Arcade Learning Environment, using identical hyperparameters. Our performance surpassed non-distributed DQN in 41 of the 49 games and also reduced the wall-time required to achieve these results by an order of magnitude on most games.