 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Conversational Diagnostic AI with Multimodal Reasoning
May 06, 2025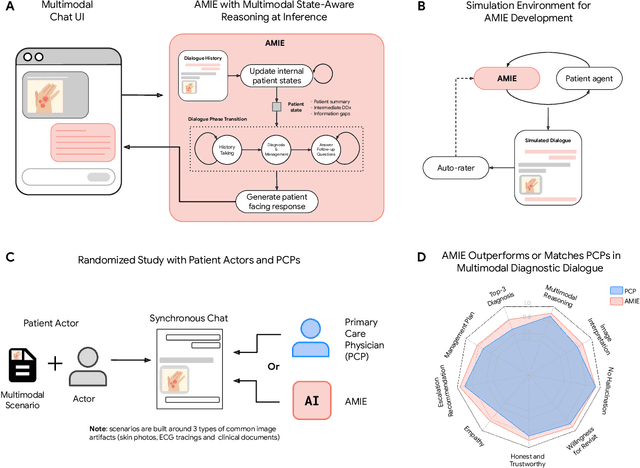
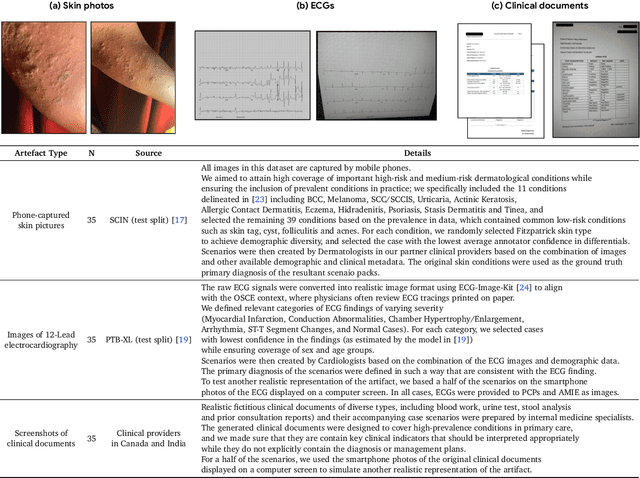
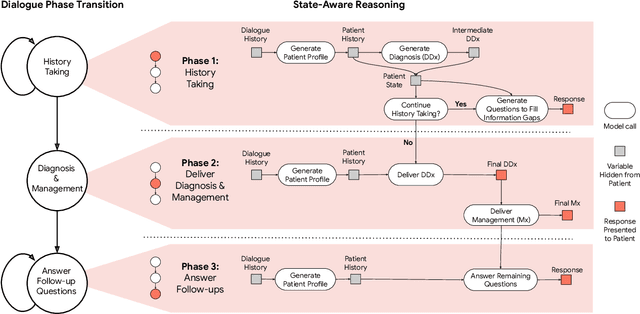
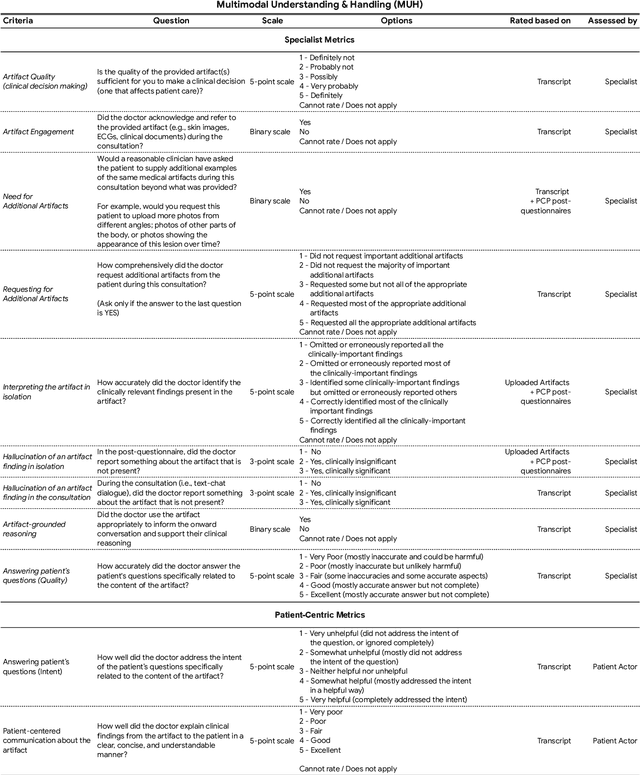
Large Language Models (LLMs) have demonstrated great potential for conducting diagnostic conversations but evaluation has been largely limited to language-only interactions, deviating from the real-world requirements of remote care delivery. Instant messaging platforms permit clinicians and patients to upload and discuss multimodal medical artifacts seamlessly in medical consultation, but the ability of LLMs to reason over such data while preserving other attributes of competent diagnostic conversation remains unknown. Here we advance the conversational diagnosis and management performance of the Articulate Medical Intelligence Explorer (AMIE) through a new capability to gather and interpret multimodal data, and reason about this precisely during consultations. Leveraging Gemini 2.0 Flash, our system implements a state-aware dialogue framework, where conversation flow is dynamically controlled by intermediate model outputs reflecting patient states and evolving diagnoses. Follow-up questions are strategically directed by uncertainty in such patient states, leading to a more structured multimodal history-taking process that emulates experienced clinicians. We compared AMIE to primary care physicians (PCPs) in a randomized, blinded, OSCE-style study of chat-based consultations with patient actors. We constructed 105 evaluation scenarios using artifacts like smartphone skin photos, ECGs, and PDFs of clinical documents across diverse conditions and demographics. Our rubric assessed multimodal capabilities and other clinically meaningful axes like history-taking, diagnostic accuracy, management reasoning, communication, and empathy. Specialist evaluation showed AMIE to be superior to PCPs on 7/9 multimodal and 29/32 non-multimodal axes (including diagnostic accuracy). The results show clear progress in multimodal conversational diagnostic AI, but real-world translation needs further research.
Towards Conversational AI for Disease Management
Mar 08, 2025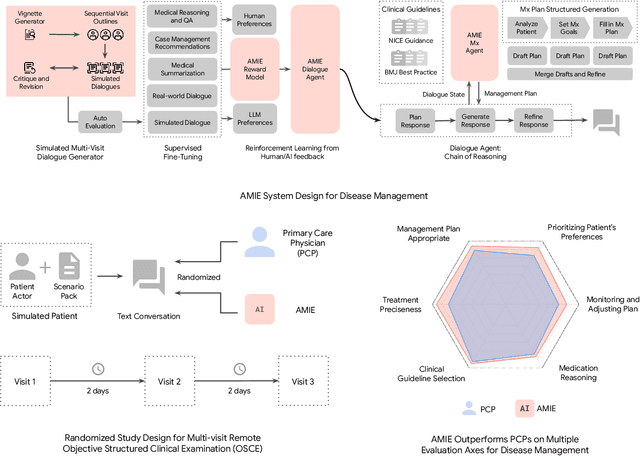

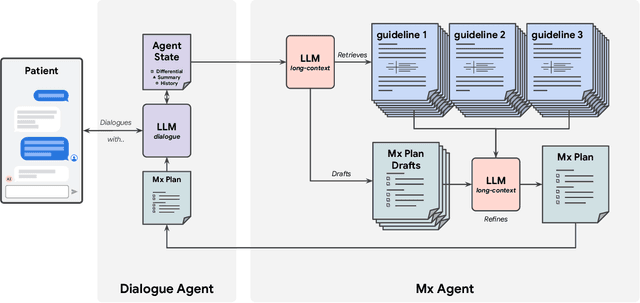
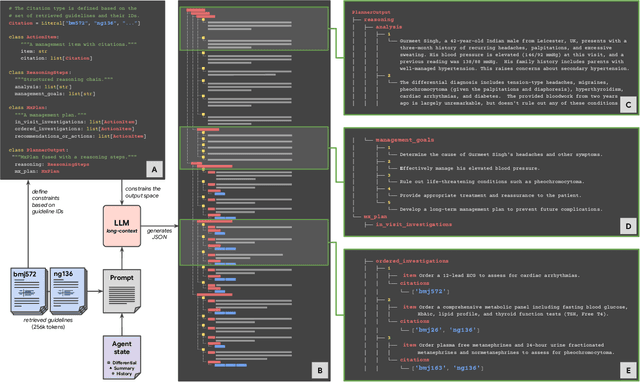
While large language models (LLMs) have shown promise in diagnostic dialogue, their capabilities for effective management reasoning - including disease progression, therapeutic response, and safe medication prescription - remain under-explored. We advance the previously demonstrated diagnostic capabilities of the Articulate Medical Intelligence Explorer (AMIE) through a new LLM-based agentic system optimised for clinical management and dialogue, incorporating reasoning over the evolution of disease and multiple patient visit encounters, response to therapy, and professional competence in medication prescription. To ground its reasoning in authoritative clinical knowledge, AMIE leverages Gemini's long-context capabilities, combining in-context retrieval with structured reasoning to align its output with relevant and up-to-date clinical practice guidelines and drug formularies. In a randomized, blinded virtual Objective Structured Clinical Examination (OSCE) study, AMIE was compared to 21 primary care physicians (PCPs) across 100 multi-visit case scenarios designed to reflect UK NICE Guidance and BMJ Best Practice guidelines. AMIE was non-inferior to PCPs in management reasoning as assessed by specialist physicians and scored better in both preciseness of treatments and investigations, and in its alignment with and grounding of management plans in clinical guidelines. To benchmark medication reasoning, we developed RxQA, a multiple-choice question benchmark derived from two national drug formularies (US, UK) and validated by board-certified pharmacists. While AMIE and PCPs both benefited from the ability to access external drug information, AMIE outperformed PCPs on higher difficulty questions. While further research would be needed before real-world translation, AMIE's strong performance across evaluations marks a significant step towards conversational AI as a tool in disease management.
Towards an AI co-scientist
Feb 26, 2025Scientific discovery relies on scientists generating novel hypotheses that undergo rigorous experimental validation. To augment this process, we introduce an AI co-scientist, a multi-agent system built on Gemini 2.0. The AI co-scientist is intended to help uncover new, original knowledge and to formulate demonstrably novel research hypotheses and proposals, building upon prior evidence and aligned to scientist-provided research objectives and guidance. The system's design incorporates a generate, debate, and evolve approach to hypothesis generation, inspired by the scientific method and accelerated by scaling test-time compute. Key contributions include: (1) a multi-agent architecture with an asynchronous task execution framework for flexible compute scaling; (2) a tournament evolution process for self-improving hypotheses generation. Automated evaluations show continued benefits of test-time compute, improving hypothesis quality. While general purpose, we focus development and validation in three biomedical areas: drug repurposing, novel target discovery, and explaining mechanisms of bacterial evolution and anti-microbial resistance. For drug repurposing, the system proposes candidates with promising validation findings, including candidates for acute myeloid leukemia that show tumor inhibition in vitro at clinically applicable concentrations. For novel target discovery, the AI co-scientist proposed new epigenetic targets for liver fibrosis, validated by anti-fibrotic activity and liver cell regeneration in human hepatic organoids. Finally, the AI co-scientist recapitulated unpublished experimental results via a parallel in silico discovery of a novel gene transfer mechanism in bacterial evolution. These results, detailed in separate, co-timed reports, demonstrate the potential to augment biomedical and scientific discovery and usher an era of AI empowered scientists.
Capabilities of Gemini Models in Medicine
May 01, 2024



Excellence in a wide variety of medical applications poses considerable challenges for AI, requiring advanced reasoning, access to up-to-date medical knowledge and understanding of complex multimodal data. Gemini models, with strong general capabilities in multimodal and long-context reasoning, offer exciting possibilities in medicine. Building on these core strengths of Gemini, we introduce Med-Gemini, a family of highly capable multimodal models that are specialized in medicine with the ability to seamlessly use web search, and that can be efficiently tailored to novel modalities using custom encoders. We evaluate Med-Gemini on 14 medical benchmarks, establishing new state-of-the-art (SoTA) performance on 10 of them, and surpass the GPT-4 model family on every benchmark where a direct comparison is viable, often by a wide margin. On the popular MedQA (USMLE) benchmark, our best-performing Med-Gemini model achieves SoTA performance of 91.1% accuracy, using a novel uncertainty-guided search strategy. On 7 multimodal benchmarks including NEJM Image Challenges and MMMU (health & medicine), Med-Gemini improves over GPT-4V by an average relative margin of 44.5%. We demonstrate the effectiveness of Med-Gemini's long-context capabilities through SoTA performance on a needle-in-a-haystack retrieval task from long de-identified health records and medical video question answering, surpassing prior bespoke methods using only in-context learning. Finally, Med-Gemini's performance suggests real-world utility by surpassing human experts on tasks such as medical text summarization, alongside demonstrations of promising potential for multimodal medical dialogue, medical research and education. Taken together, our results offer compelling evidence for Med-Gemini's potential, although further rigorous evaluation will be crucial before real-world deployment in this safety-critical domain.
A Toolbox for Surfacing Health Equity Harms and Biases in Large Language Models
Mar 18, 2024Large language models (LLMs) hold immense promise to serve complex health information needs but also have the potential to introduce harm and exacerbate health disparities. Reliably evaluating equity-related model failures is a critical step toward developing systems that promote health equity. In this work, we present resources and methodologies for surfacing biases with potential to precipitate equity-related harms in long-form, LLM-generated answers to medical questions and then conduct an empirical case study with Med-PaLM 2, resulting in the largest human evaluation study in this area to date. Our contributions include a multifactorial framework for human assessment of LLM-generated answers for biases, and EquityMedQA, a collection of seven newly-released datasets comprising both manually-curated and LLM-generated questions enriched for adversarial queries. Both our human assessment framework and dataset design process are grounded in an iterative participatory approach and review of possible biases in Med-PaLM 2 answers to adversarial queries. Through our empirical study, we find that the use of a collection of datasets curated through a variety of methodologies, coupled with a thorough evaluation protocol that leverages multiple assessment rubric designs and diverse rater groups, surfaces biases that may be missed via narrower evaluation approaches. Our experience underscores the importance of using diverse assessment methodologies and involving raters of varying backgrounds and expertise. We emphasize that while our framework can identify specific forms of bias, it is not sufficient to holistically assess whether the deployment of an AI system promotes equitable health outcomes. We hope the broader community leverages and builds on these tools and methods towards realizing a shared goal of LLMs that promote accessible and equitable healthcare for all.
MINT: A wrapper to make multi-modal and multi-image AI models interactive
Jan 22, 2024During the diagnostic process, doctors incorporate multimodal information including imaging and the medical history - and similarly medical AI development has increasingly become multimodal. In this paper we tackle a more subtle challenge: doctors take a targeted medical history to obtain only the most pertinent pieces of information; how do we enable AI to do the same? We develop a wrapper method named MINT (Make your model INTeractive) that automatically determines what pieces of information are most valuable at each step, and ask for only the most useful information. We demonstrate the efficacy of MINT wrapping a skin disease prediction model, where multiple images and a set of optional answers to $25$ standard metadata questions (i.e., structured medical history) are used by a multi-modal deep network to provide a differential diagnosis. We show that MINT can identify whether metadata inputs are needed and if so, which question to ask next. We also demonstrate that when collecting multiple images, MINT can identify if an additional image would be beneficial, and if so, which type of image to capture. We showed that MINT reduces the number of metadata and image inputs needed by 82% and 36.2% respectively, while maintaining predictive performance. Using real-world AI dermatology system data, we show that needing fewer inputs can retain users that may otherwise fail to complete the system submission and drop off without a diagnosis. Qualitative examples show MINT can closely mimic the step-by-step decision making process of a clinical workflow and how this is different for straight forward cases versus more difficult, ambiguous cases. Finally we demonstrate how MINT is robust to different underlying multi-model classifiers and can be easily adapted to user requirements without significant model re-training.
Towards Conversational Diagnostic AI
Jan 11, 2024At the heart of medicine lies the physician-patient dialogue, where skillful history-taking paves the way for accurate diagnosis, effective management, and enduring trust. Artificial Intelligence (AI) systems capable of diagnostic dialogue could increase accessibility, consistency, and quality of care. However, approximating clinicians' expertise is an outstanding grand challenge. Here, we introduce AMIE (Articulate Medical Intelligence Explorer), a Large Language Model (LLM) based AI system optimized for diagnostic dialogue. AMIE uses a novel self-play based simulated environment with automated feedback mechanisms for scaling learning across diverse disease conditions, specialties, and contexts. We designed a framework for evaluating clinically-meaningful axes of performance including history-taking, diagnostic accuracy, management reasoning, communication skills, and empathy. We compared AMIE's performance to that of primary care physicians (PCPs) in a randomized, double-blind crossover study of text-based consultations with validated patient actors in the style of an Objective Structured Clinical Examination (OSCE). The study included 149 case scenarios from clinical providers in Canada, the UK, and India, 20 PCPs for comparison with AMIE, and evaluations by specialist physicians and patient actors. AMIE demonstrated greater diagnostic accuracy and superior performance on 28 of 32 axes according to specialist physicians and 24 of 26 axes according to patient actors. Our research has several limitations and should be interpreted with appropriate caution. Clinicians were limited to unfamiliar synchronous text-chat which permits large-scale LLM-patient interactions but is not representative of usual clinical practice. While further research is required before AMIE could be translated to real-world settings, the results represent a milestone towards conversational diagnostic AI.
Consensus, dissensus and synergy between clinicians and specialist foundation models in radiology report generation
Dec 06, 2023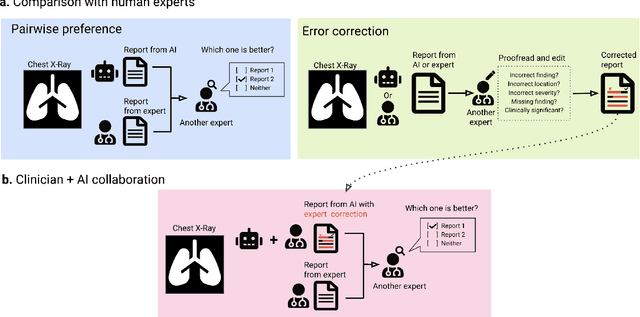
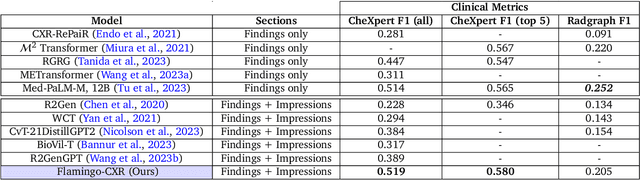
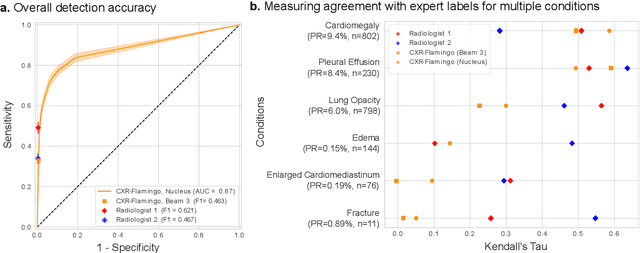
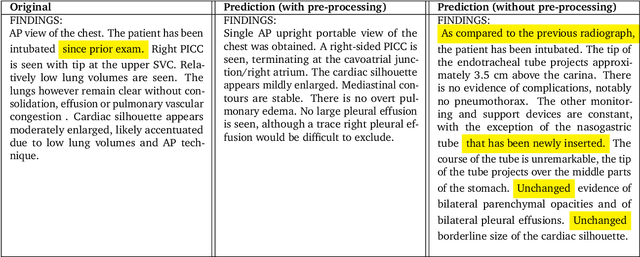
Radiology reports are an instrumental part of modern medicine, informing key clinical decisions such as diagnosis and treatment. The worldwide shortage of radiologists, however, restricts access to expert care and imposes heavy workloads, contributing to avoidable errors and delays in report delivery. While recent progress in automated report generation with vision-language models offer clear potential in ameliorating the situation, the path to real-world adoption has been stymied by the challenge of evaluating the clinical quality of AI-generated reports. In this study, we build a state-of-the-art report generation system for chest radiographs, \textit{Flamingo-CXR}, by fine-tuning a well-known vision-language foundation model on radiology data. To evaluate the quality of the AI-generated reports, a group of 16 certified radiologists provide detailed evaluations of AI-generated and human written reports for chest X-rays from an intensive care setting in the United States and an inpatient setting in India. At least one radiologist (out of two per case) preferred the AI report to the ground truth report in over 60$\%$ of cases for both datasets. Amongst the subset of AI-generated reports that contain errors, the most frequently cited reasons were related to the location and finding, whereas for human written reports, most mistakes were related to severity and finding. This disparity suggested potential complementarity between our AI system and human experts, prompting us to develop an assistive scenario in which \textit{Flamingo-CXR} generates a first-draft report, which is subsequently revised by a clinician. This is the first demonstration of clinician-AI collaboration for report writing, and the resultant reports are assessed to be equivalent or preferred by at least one radiologist to reports written by experts alone in 80$\%$ of in-patient cases and 60$\%$ of intensive care cases.
Towards Accurate Differential Diagnosis with Large Language Models
Nov 30, 2023



An accurate differential diagnosis (DDx) is a cornerstone of medical care, often reached through an iterative process of interpretation that combines clinical history, physical examination, investigations and procedures. Interactive interfaces powered by Large Language Models (LLMs) present new opportunities to both assist and automate aspects of this process. In this study, we introduce an LLM optimized for diagnostic reasoning, and evaluate its ability to generate a DDx alone or as an aid to clinicians. 20 clinicians evaluated 302 challenging, real-world medical cases sourced from the New England Journal of Medicine (NEJM) case reports. Each case report was read by two clinicians, who were randomized to one of two assistive conditions: either assistance from search engines and standard medical resources, or LLM assistance in addition to these tools. All clinicians provided a baseline, unassisted DDx prior to using the respective assistive tools. Our LLM for DDx exhibited standalone performance that exceeded that of unassisted clinicians (top-10 accuracy 59.1% vs 33.6%, [p = 0.04]). Comparing the two assisted study arms, the DDx quality score was higher for clinicians assisted by our LLM (top-10 accuracy 51.7%) compared to clinicians without its assistance (36.1%) (McNemar's Test: 45.7, p < 0.01) and clinicians with search (44.4%) (4.75, p = 0.03). Further, clinicians assisted by our LLM arrived at more comprehensive differential lists than those without its assistance. Our study suggests that our LLM for DDx has potential to improve clinicians' diagnostic reasoning and accuracy in challenging cases, meriting further real-world evaluation for its ability to empower physicians and widen patients' access to specialist-level expertise.
The Capability of Large Language Models to Measure Psychiatric Functioning
Aug 03, 2023
The current work investigates the capability of Large language models (LLMs) that are explicitly trained on large corpuses of medical knowledge (Med-PaLM 2) to predict psychiatric functioning from patient interviews and clinical descriptions without being trained to do so. To assess this, n = 145 depression and n =115 PTSD assessments and n = 46 clinical case studies across high prevalence/high comorbidity disorders (Depressive, Anxiety, Psychotic, trauma and stress, Addictive disorders) were analyzed using prompts to extract estimated clinical scores and diagnoses. Results demonstrate that Med-PaLM 2 is capable of assessing psychiatric functioning across a range of psychiatric conditions with the strongest performance being the prediction of depression scores based on standardized assessments (Accuracy range= 0.80 - 0.84) which were statistically indistinguishable from human clinical raters t(1,144) = 1.20; p = 0.23. Results show the potential for general clinical language models to flexibly predict psychiatric risk based on free descriptions of functioning from both patients and clinicians.