 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlphaEvolve: A coding agent for scientific and algorithmic discovery
Jun 16, 2025In this white paper, we present AlphaEvolve, an evolutionary coding agent that substantially enhances capabilities of state-of-the-art LLMs on highly challenging tasks such as tackling open scientific problems or optimizing critical pieces of computational infrastructure. AlphaEvolve orchestrates an autonomous pipeline of LLMs, whose task is to improve an algorithm by making direct changes to the code. Using an evolutionary approach, continuously receiving feedback from one or more evaluators, AlphaEvolve iteratively improves the algorithm, potentially leading to new scientific and practical discoveries. We demonstrate the broad applicability of this approach by applying it to a number of important computational problems. When applied to optimizing critical components of large-scale computational stacks at Google, AlphaEvolve developed a more efficient scheduling algorithm for data centers, found a functionally equivalent simplification in the circuit design of hardware accelerators, and accelerated the training of the LLM underpinning AlphaEvolve itself. Furthermore, AlphaEvolve discovered novel, provably correct algorithms that surpass state-of-the-art solutions on a spectrum of problems in mathematics and computer science, significantly expanding the scope of prior automated discovery methods (Romera-Paredes et al., 2023). Notably, AlphaEvolve developed a search algorithm that found a procedure to multiply two $4 \times 4$ complex-valued matrices using $48$ scalar multiplications; offering the first improvement, after 56 years, over Strassen's algorithm in this setting. We believe AlphaEvolve and coding agents like it can have a significant impact in improving solutions of problems across many areas of science and computation.
Consensus, dissensus and synergy between clinicians and specialist foundation models in radiology report generation
Dec 06, 2023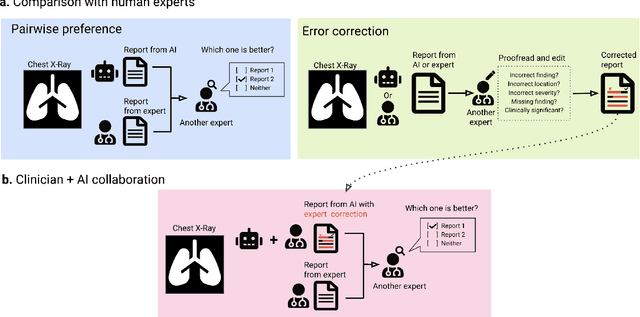
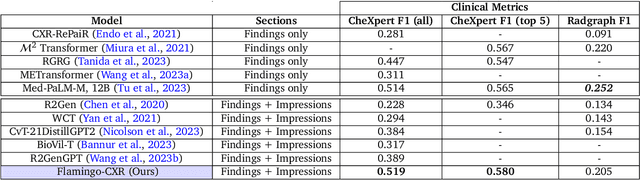
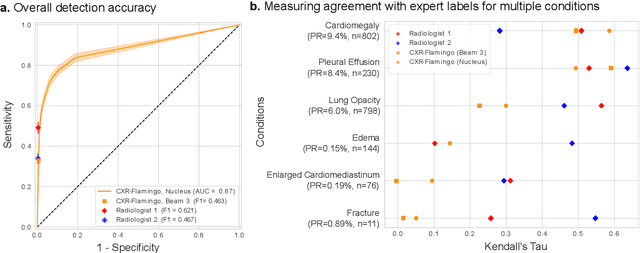
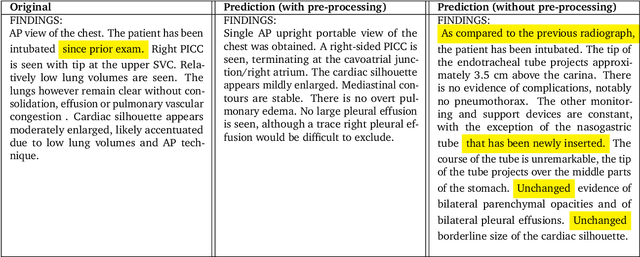
Radiology reports are an instrumental part of modern medicine, informing key clinical decisions such as diagnosis and treatment. The worldwide shortage of radiologists, however, restricts access to expert care and imposes heavy workloads, contributing to avoidable errors and delays in report delivery. While recent progress in automated report generation with vision-language models offer clear potential in ameliorating the situation, the path to real-world adoption has been stymied by the challenge of evaluating the clinical quality of AI-generated reports. In this study, we build a state-of-the-art report generation system for chest radiographs, \textit{Flamingo-CXR}, by fine-tuning a well-known vision-language foundation model on radiology data. To evaluate the quality of the AI-generated reports, a group of 16 certified radiologists provide detailed evaluations of AI-generated and human written reports for chest X-rays from an intensive care setting in the United States and an inpatient setting in India. At least one radiologist (out of two per case) preferred the AI report to the ground truth report in over 60$\%$ of cases for both datasets. Amongst the subset of AI-generated reports that contain errors, the most frequently cited reasons were related to the location and finding, whereas for human written reports, most mistakes were related to severity and finding. This disparity suggested potential complementarity between our AI system and human experts, prompting us to develop an assistive scenario in which \textit{Flamingo-CXR} generates a first-draft report, which is subsequently revised by a clinician. This is the first demonstration of clinician-AI collaboration for report writing, and the resultant reports are assessed to be equivalent or preferred by at least one radiologist to reports written by experts alone in 80$\%$ of in-patient cases and 60$\%$ of intensive care cases.
Improving alignment of dialogue agents via targeted human judgements
Sep 28, 2022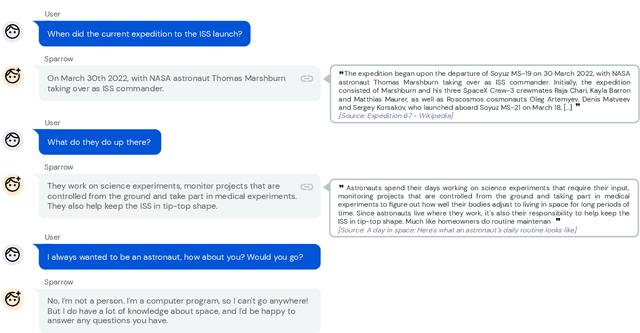

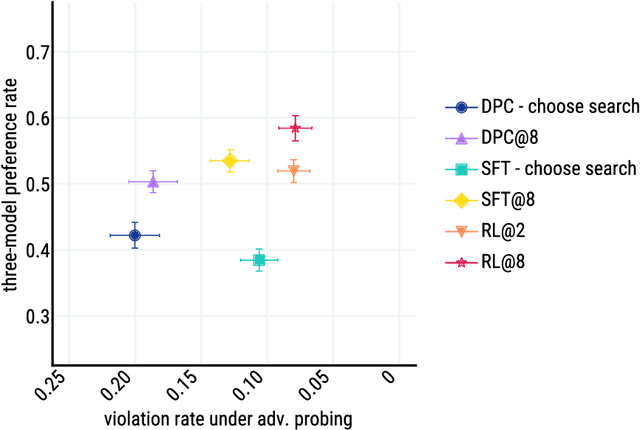
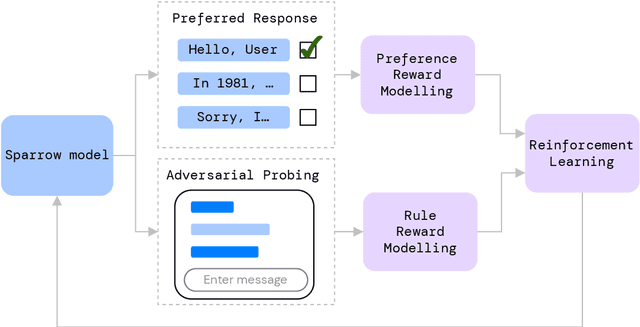
We present Sparrow, an information-seeking dialogue agent trained to be more helpful, correct, and harmless compared to prompted language model baselines. We use reinforcement learning from human feedback to train our models with two new additions to help human raters judge agent behaviour. First, to make our agent more helpful and harmless, we break down the requirements for good dialogue into natural language rules the agent should follow, and ask raters about each rule separately. We demonstrate that this breakdown enables us to collect more targeted human judgements of agent behaviour and allows for more efficient rule-conditional reward models. Second, our agent provides evidence from sources supporting factual claims when collecting preference judgements over model statements. For factual questions, evidence provided by Sparrow supports the sampled response 78% of the time. Sparrow is preferred more often than baselines while being more resilient to adversarial probing by humans, violating our rules only 8% of the time when probed. Finally, we conduct extensive analyses showing that though our model learns to follow our rules it can exhibit distributional biases.
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022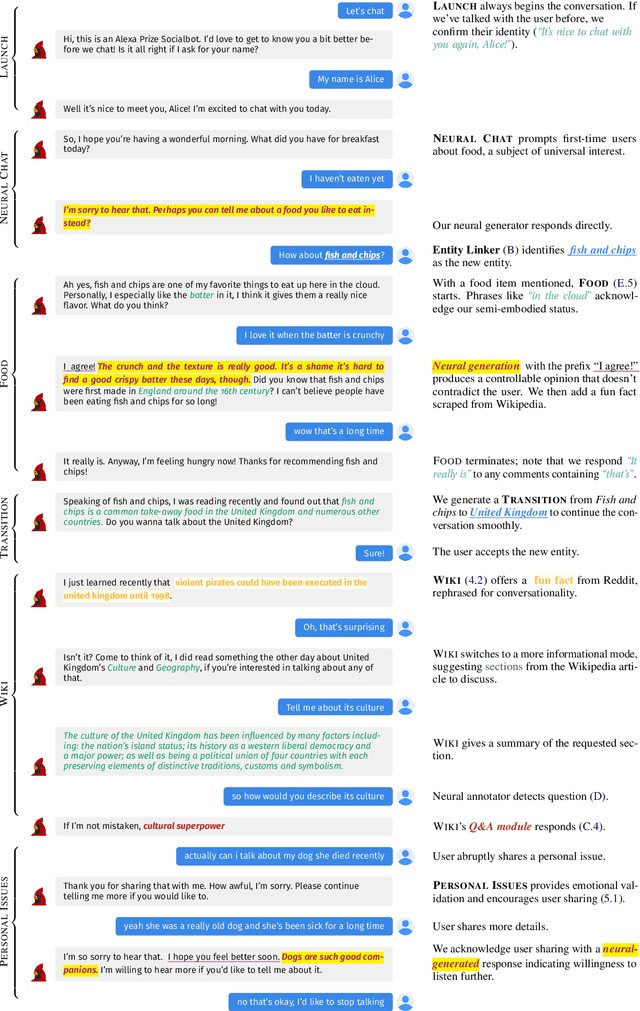


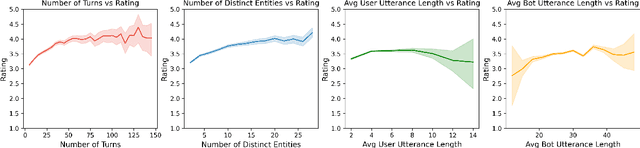
We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
Neural Generation Meets Real People: Towards Emotionally Engaging Mixed-Initiative Conversations
Sep 05, 2020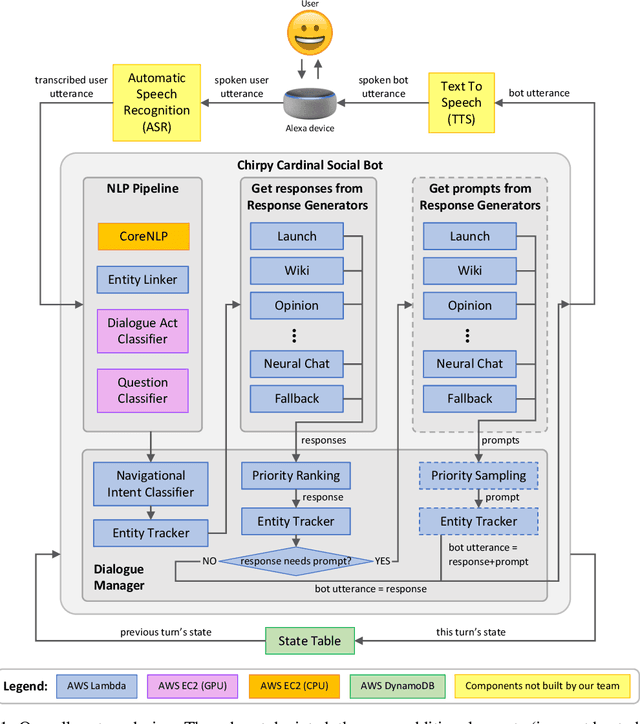
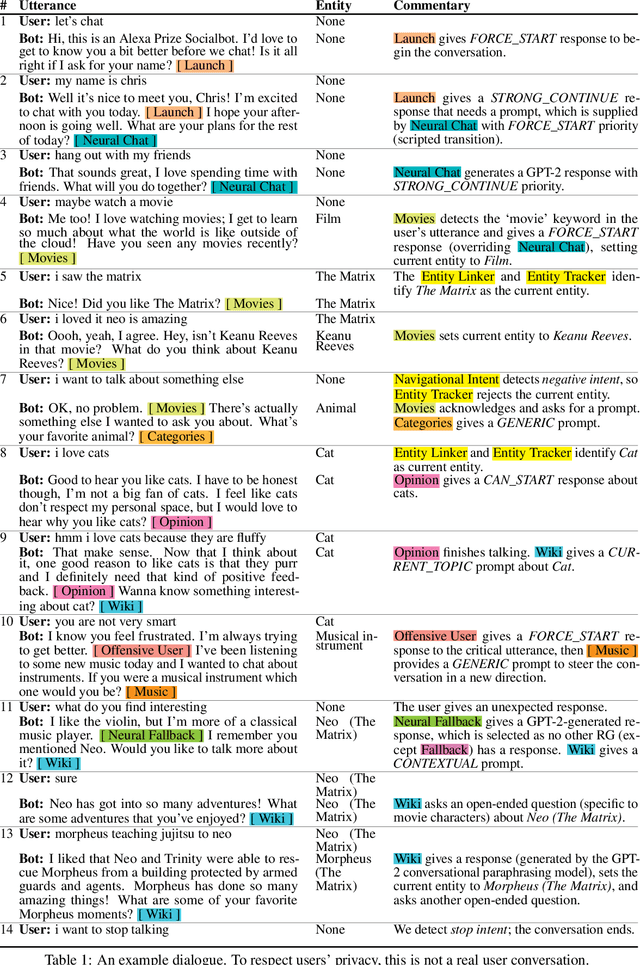

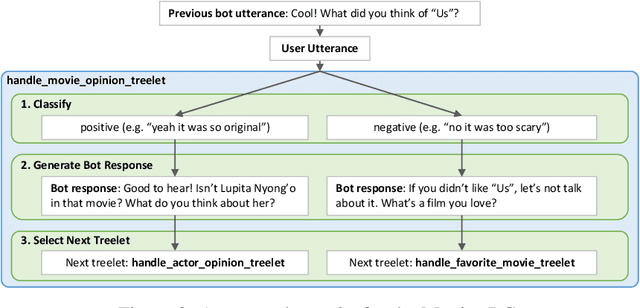
We present Chirpy Cardinal, an open-domain dialogue agent, as a research platform for the 2019 Alexa Prize competition. Building an open-domain socialbot that talks to real people is challenging - such a system must meet multiple user expectations such as broad world knowledge, conversational style, and emotional connection. Our socialbot engages users on their terms - prioritizing their interests, feelings and autonomy. As a result, our socialbot provides a responsive, personalized user experience, capable of talking knowledgeably about a wide variety of topics, as well as chatting empathetically about ordinary life. Neural generation plays a key role in achieving these goals, providing the backbone for our conversational and emotional tone. At the end of the competition, Chirpy Cardinal progressed to the finals with an average rating of 3.6/5.0, a median conversation duration of 2 minutes 16 seconds, and a 90th percentile duration of over 12 minutes.
Do Massively Pretrained Language Models Make Better Storytellers?
Sep 24, 2019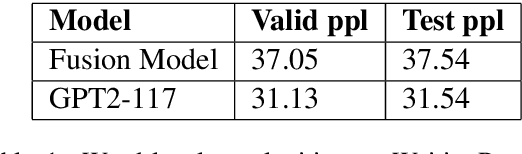
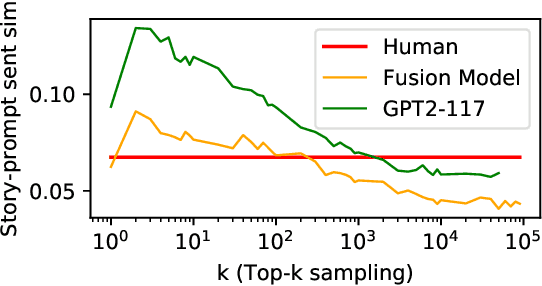
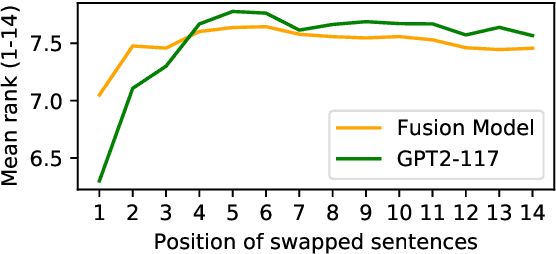

Large neural language models trained on massive amounts of text have emerged as a formidable strategy for Natural Language Understanding tasks. However, the strength of these models as Natural Language Generators is less clear. Though anecdotal evidence suggests that these models generate better quality text, there has been no detailed study characterizing their generation abilities. In this work, we compare the performance of an extensively pretrained model, OpenAI GPT2-117 (Radford et al., 2019), to a state-of-the-art neural story generation model (Fan et al., 2018). By evaluating the generated text across a wide variety of automatic metrics, we characterize the ways in which pretrained models do, and do not, make better storytellers. We find that although GPT2-117 conditions more strongly on context, is more sensitive to ordering of events, and uses more unusual words, it is just as likely to produce repetitive and under-diverse text when using likelihood-maximizing decoding algorithms.
What makes a good conversation? How controllable attributes affect human judgments
Apr 10, 2019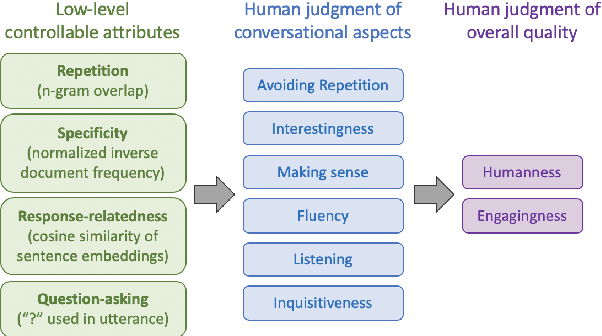
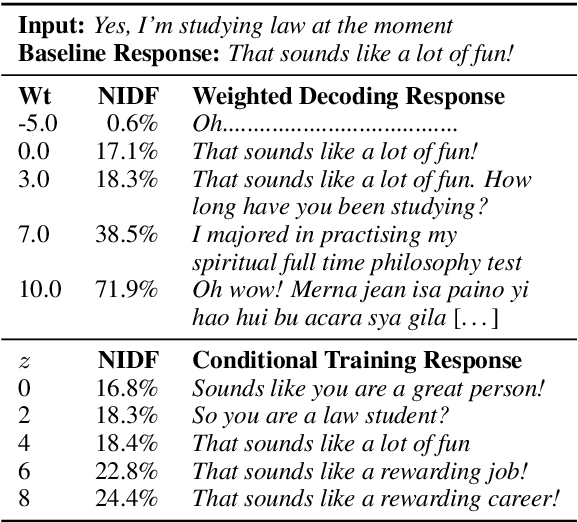


A good conversation requires balance -- between simplicity and detail; staying on topic and changing it; asking questions and answering them. Although dialogue agents are commonly evaluated via human judgments of overall quality, the relationship between quality and these individual factors is less well-studied. In this work, we examine two controllable neural text generation methods, conditional training and weighted decoding, in order to control four important attributes for chitchat dialogue: repetition, specificity, response-relatedness and question-asking. We conduct a large-scale human evaluation to measure the effect of these control parameters on multi-turn interactive conversations on the PersonaChat task. We provide a detailed analysis of their relationship to high-level aspects of conversation, and show that by controlling combinations of these variables our models obtain clear improvements in human quality judgments.
Get To The Point: Summarization with Pointer-Generator Networks
Apr 25, 2017



Neural sequence-to-sequence models have provided a viable new approach for abstractive text summarization (meaning they are not restricted to simply selecting and rearranging passages from the original text). However, these models have two shortcomings: they are liable to reproduce factual details inaccurately, and they tend to repeat themselves. In this work we propose a novel architecture that augments the standard sequence-to-sequence attentional model in two orthogonal ways. First, we use a hybrid pointer-generator network that can copy words from the source text via pointing, which aids accurate reproduction of information, while retaining the ability to produce novel words through the generator. Second, we use coverage to keep track of what has been summarized, which discourages repetition. We apply our model to the CNN / Daily Mail summarization task, outperforming the current abstractive state-of-the-art by at least 2 ROUGE points.
Compression of Neural Machine Translation Models via Pruning
Jun 29, 2016Neural Machine Translation (NMT), like many other deep learning domains, typically suffers from over-parameterization, resulting in large storage sizes. This paper examines three simple magnitude-based pruning schemes to compress NMT models, namely class-blind, class-uniform, and class-distribution, which differ in terms of how pruning thresholds are computed for the different classes of weights in the NMT architecture. We demonstrate the efficacy of weight pruning as a compression technique for a state-of-the-art NMT system. We show that an NMT model with over 200 million parameters can be pruned by 40% with very little performance loss as measured on the WMT'14 English-German translation task. This sheds light on the distribution of redundancy in the NMT architecture. Our main result is that with retraining, we can recover and even surpass the original performance with an 80%-pruned model.