 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpaqueToolsBench: Learning Nuances of Tool Behavior Through Interaction
Feb 16, 2026Tool-calling is essential for Large Language Model (LLM) agents to complete real-world tasks. While most existing benchmarks assume simple, perfectly documented tools, real-world tools (e.g., general "search" APIs) are often opaque, lacking clear best practices or failure modes. Can LLM agents improve their performance in environments with opaque tools by interacting and subsequently improving documentation? To study this, we create OpaqueToolsBench, a benchmark consisting of three distinct task-oriented environments: general function calling, interactive chess playing, and long-trajectory agentic search. Each environment provides underspecified tools that models must learn to use effectively to complete the task. Results on OpaqueToolsBench suggest existing methods for automatically documenting tools are expensive and unreliable when tools are opaque. To address this, we propose a simple framework, ToolObserver, that iteratively refines tool documentation by observing execution feedback from tool-calling trajectories. Our approach outperforms existing methods on OpaqueToolsBench across datasets, even in relatively hard settings. Furthermore, for test-time tool exploration settings, our method is also efficient, consuming 3.5-7.5x fewer total tokens than the best baseline.
Lost in the Maze: Overcoming Context Limitations in Long-Horizon Agentic Search
Oct 21, 2025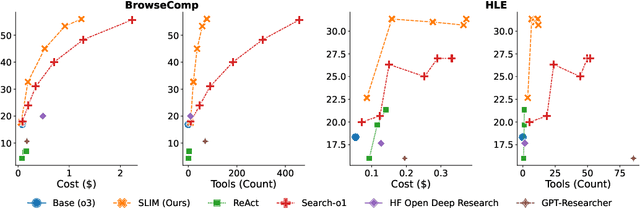



Long-horizon agentic search requires iteratively exploring the web over long trajectories and synthesizing information across many sources, and is the foundation for enabling powerful applications like deep research systems. In this work, we show that popular agentic search frameworks struggle to scale to long trajectories primarily due to context limitations-they accumulate long, noisy content, hit context window and tool budgets, or stop early. Then, we introduce SLIM (Simple Lightweight Information Management), a simple framework that separates retrieval into distinct search and browse tools, and periodically summarizes the trajectory, keeping context concise while enabling longer, more focused searches. On long-horizon tasks, SLIM achieves comparable performance at substantially lower cost and with far fewer tool calls than strong open-source baselines across multiple base models. Specifically, with o3 as the base model, SLIM achieves 56% on BrowseComp and 31% on HLE, outperforming all open-source frameworks by 8 and 4 absolute points, respectively, while incurring 4-6x fewer tool calls. Finally, we release an automated fine-grained trajectory analysis pipeline and error taxonomy for characterizing long-horizon agentic search frameworks; SLIM exhibits fewer hallucinations than prior systems. We hope our analysis framework and simple tool design inform future long-horizon agents.
Promptriever: Instruction-Trained Retrievers Can Be Prompted Like Language Models
Sep 17, 2024



Instruction-tuned language models (LM) are able to respond to imperative commands, providing a more natural user interface compared to their base counterparts. In this work, we present Promptriever, the first retrieval model able to be prompted like an LM. To train Promptriever, we curate and release a new instance-level instruction training set from MS MARCO, spanning nearly 500k instances. Promptriever not only achieves strong performance on standard retrieval tasks, but also follows instructions. We observe: (1) large gains (reaching SoTA) on following detailed relevance instructions (+14.3 p-MRR / +3.1 nDCG on FollowIR), (2) significantly increased robustness to lexical choices/phrasing in the query+instruction (+12.9 Robustness@10 on InstructIR), and (3) the ability to perform hyperparameter search via prompting to reliably improve retrieval performance (+1.4 average increase on BEIR). Promptriever demonstrates that retrieval models can be controlled with prompts on a per-query basis, setting the stage for future work aligning LM prompting techniques with information retrieval.
Lost in the Middle: How Language Models Use Long Contexts
Jul 31, 2023While recent language models have the ability to take long contexts as input, relatively little is known about how well they use longer context. We analyze language model performance on two tasks that require identifying relevant information within their input contexts: multi-document question answering and key-value retrieval. We find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. Furthermore, performance substantially decreases as the input context grows longer, even for explicitly long-context models. Our analysis provides a better understanding of how language models use their input context and provides new evaluation protocols for future long-context models.
Evaluating Human-Language Model Interaction
Dec 20, 2022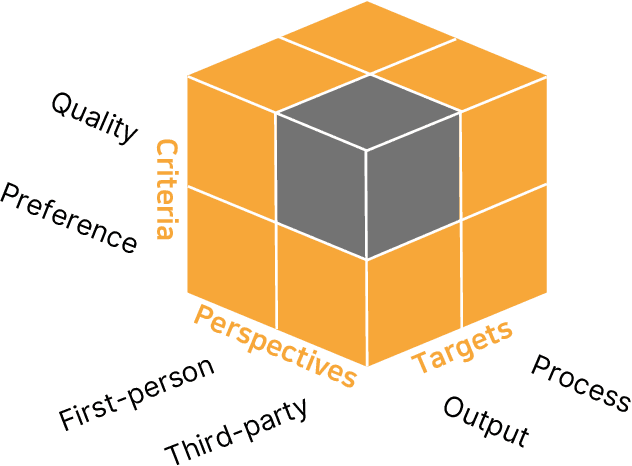
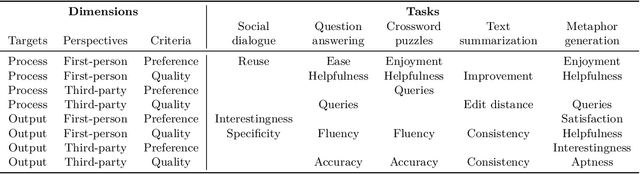
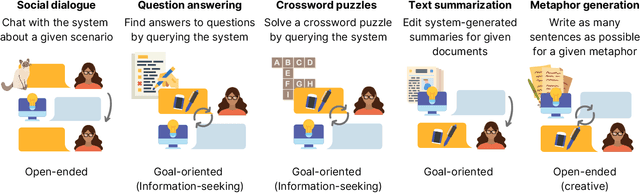

Many real-world applications of language models (LMs), such as code autocomplete and writing assistance, involve human-LM interaction. However, the main LM benchmarks are non-interactive in that a system produces output without human involvement. To evaluate human-LM interaction, we develop a new framework, Human-AI Language-based Interaction Evaluation (HALIE), that expands non-interactive evaluation along three dimensions, capturing (i) the interactive process, not only the final output; (ii) the first-person subjective experience, not just a third-party assessment; and (iii) notions of preference beyond quality. We then design five tasks ranging from goal-oriented to open-ended to capture different forms of interaction. On four state-of-the-art LMs (three variants of OpenAI's GPT-3 and AI21's J1-Jumbo), we find that non-interactive performance does not always result in better human-LM interaction and that first-person and third-party metrics can diverge, suggesting the importance of examining the nuances of human-LM interaction.
When can I Speak? Predicting initiation points for spoken dialogue agents
Aug 07, 2022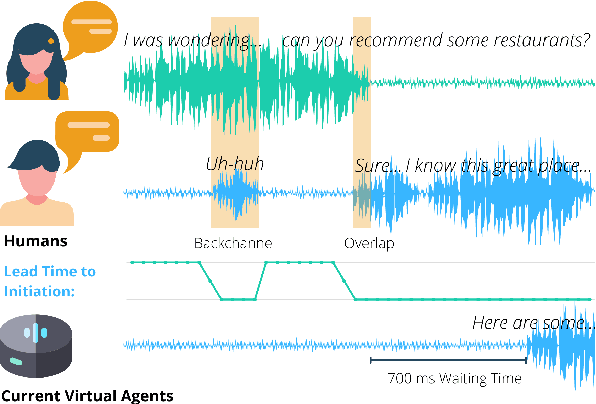
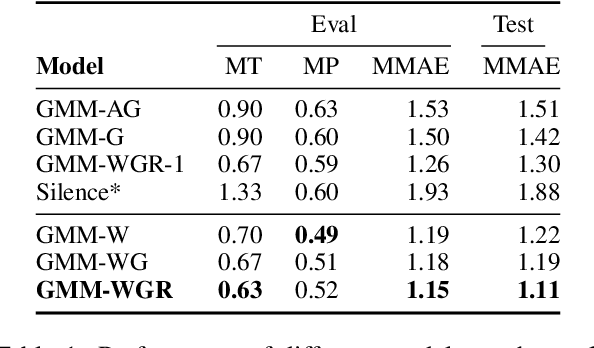
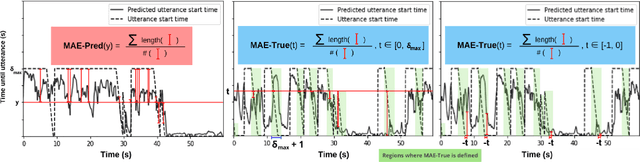
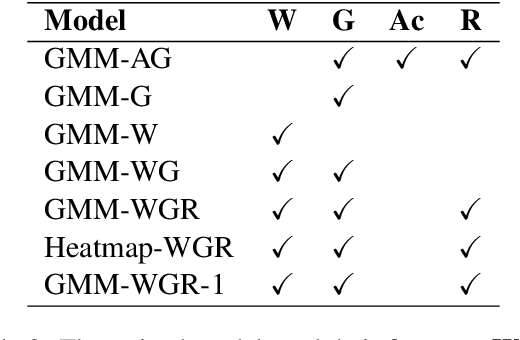
Current spoken dialogue systems initiate their turns after a long period of silence (700-1000ms), which leads to little real-time feedback, sluggish responses, and an overall stilted conversational flow. Humans typically respond within 200ms and successfully predicting initiation points in advance would allow spoken dialogue agents to do the same. In this work, we predict the lead-time to initiation using prosodic features from a pre-trained speech representation model (wav2vec 1.0) operating on user audio and word features from a pre-trained language model (GPT-2) operating on incremental transcriptions. To evaluate errors, we propose two metrics w.r.t. predicted and true lead times. We train and evaluate the models on the Switchboard Corpus and find that our method outperforms features from prior work on both metrics and vastly outperforms the common approach of waiting for 700ms of silence.
Neural Generation Meets Real People: Building a Social, Informative Open-Domain Dialogue Agent
Jul 25, 2022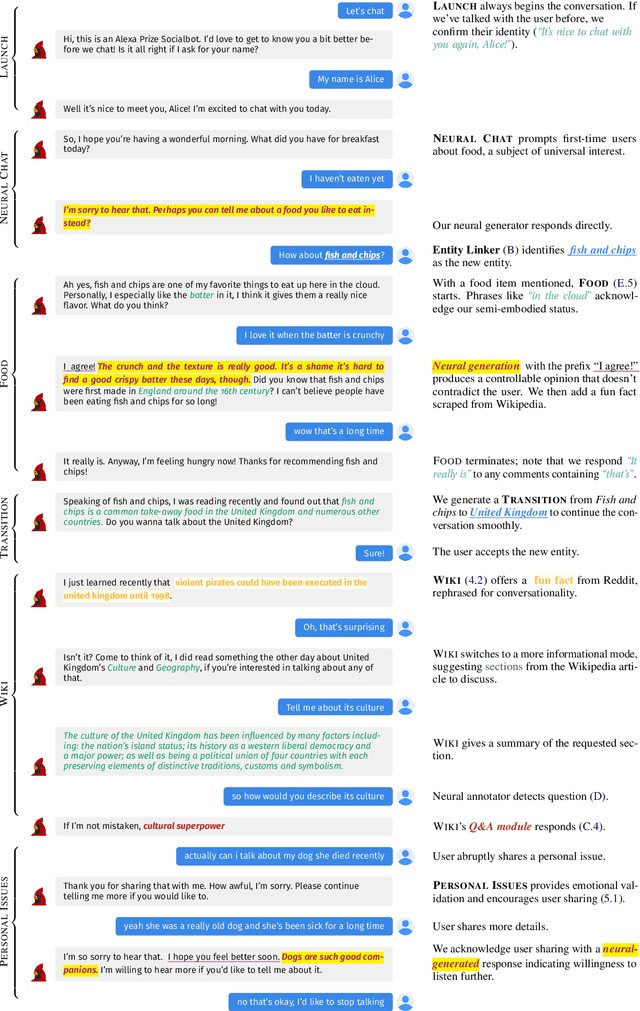


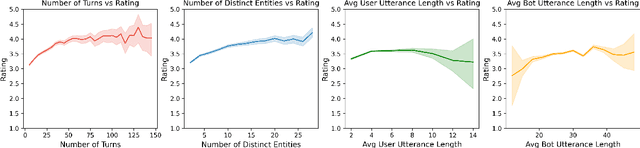
We present Chirpy Cardinal, an open-domain social chatbot. Aiming to be both informative and conversational, our bot chats with users in an authentic, emotionally intelligent way. By integrating controlled neural generation with scaffolded, hand-written dialogue, we let both the user and bot take turns driving the conversation, producing an engaging and socially fluent experience. Deployed in the fourth iteration of the Alexa Prize Socialbot Grand Challenge, Chirpy Cardinal handled thousands of conversations per day, placing second out of nine bots with an average user rating of 3.58/5.
You Only Need One Model for Open-domain Question Answering
Dec 14, 2021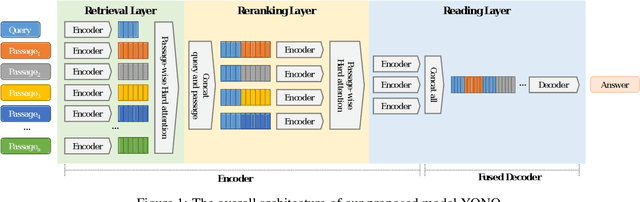
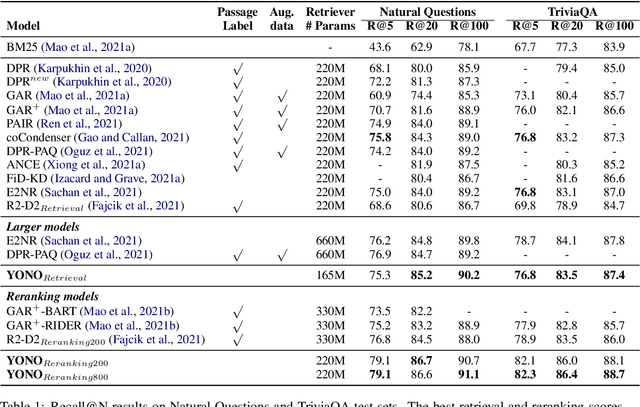
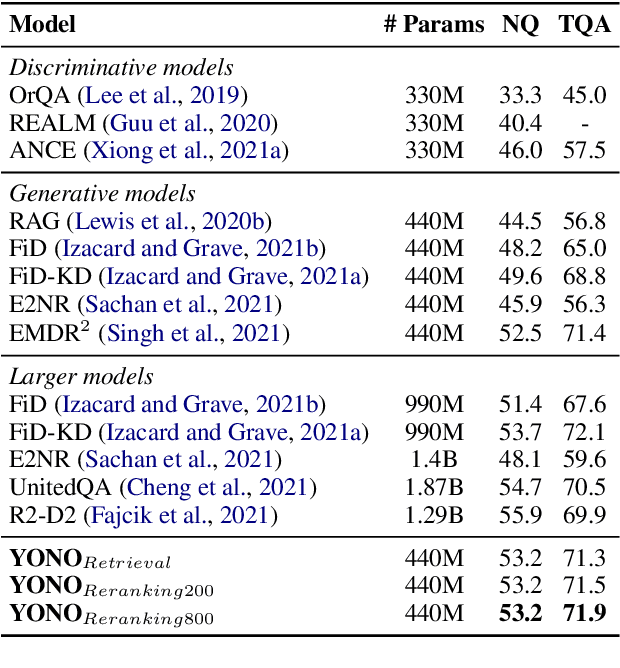
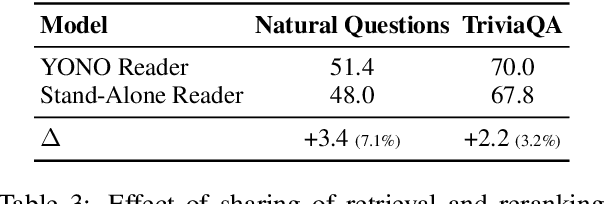
Recent works for Open-domain Question Answering refer to an external knowledge base using a retriever model, optionally rerank the passages with a separate reranker model and generate an answer using an another reader model. Despite performing related tasks, the models have separate parameters and are weakly-coupled during training. In this work, we propose casting the retriever and the reranker as hard-attention mechanisms applied sequentially within the transformer architecture and feeding the resulting computed representations to the reader. In this singular model architecture the hidden representations are progressively refined from the retriever to the reranker to the reader, which is more efficient use of model capacity and also leads to better gradient flow when we train it in an end-to-end manner. We also propose a pre-training methodology to effectively train this architecture. We evaluate our model on Natural Questions and TriviaQA open datasets and for a fixed parameter budget, our model outperforms the previous state-of-the-art model by 1.0 and 0.7 exact match scores.
Hindsight: Posterior-guided training of retrievers for improved open-ended generation
Oct 21, 2021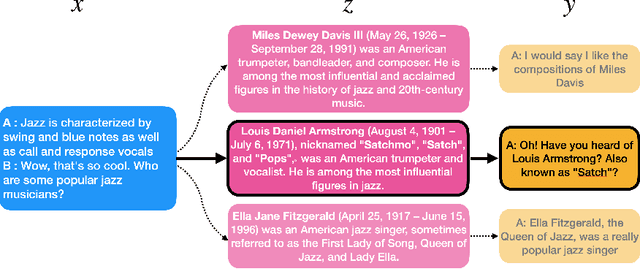

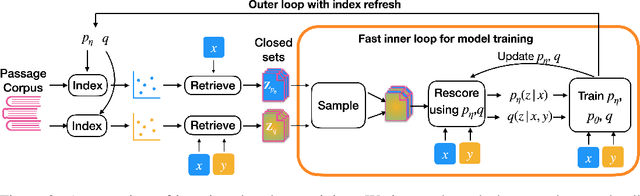
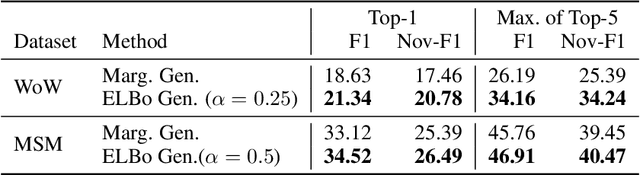
Many text generation systems benefit from using a retriever to retrieve passages from a textual knowledge corpus (e.g., Wikipedia) which are then provided as additional context to the generator. For open-ended generation tasks (like generating informative utterances in conversations) many varied passages may be equally relevant and we find that existing methods that jointly train the retriever and generator underperform: the retriever may not find relevant passages even amongst the top-10 and hence the generator may not learn a preference to ground its generated output in them. We propose using an additional guide retriever that is allowed to use the target output and "in hindsight" retrieve relevant passages during training. We model the guide retriever after the posterior distribution Q of passages given the input and the target output and train it jointly with the standard retriever and the generator by maximizing the evidence lower bound (ELBo) in expectation over Q. For informative conversations from the Wizard of Wikipedia dataset, with posterior-guided training, the retriever finds passages with higher relevance in the top-10 (23% relative improvement), the generator's responses are more grounded in the retrieved passage (19% relative improvement) and the end-to-end system produces better overall output (6.4% relative improvement).
Human-like informative conversations: Better acknowledgements using conditional mutual information
Apr 16, 2021
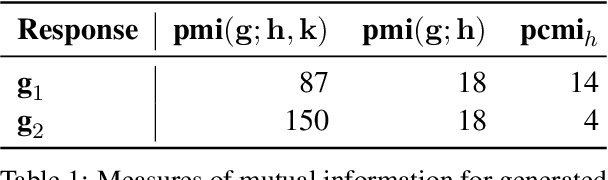

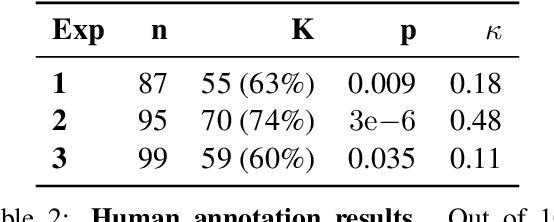
This work aims to build a dialogue agent that can weave new factual content into conversations as naturally as humans. We draw insights from linguistic principles of conversational analysis and annotate human-human conversations from the Switchboard Dialog Act Corpus to examine humans strategies for acknowledgement, transition, detail selection and presentation. When current chatbots (explicitly provided with new factual content) introduce facts into a conversation, their generated responses do not acknowledge the prior turns. This is because models trained with two contexts - new factual content and conversational history - generate responses that are non-specific w.r.t. one of the contexts, typically the conversational history. We show that specificity w.r.t. conversational history is better captured by Pointwise Conditional Mutual Information ($\text{pcmi}_h$) than by the established use of Pointwise Mutual Information ($\text{pmi}$). Our proposed method, Fused-PCMI, trades off $\text{pmi}$ for $\text{pcmi}_h$ and is preferred by humans for overall quality over the Max-PMI baseline 60% of the time. Human evaluators also judge responses with higher $\text{pcmi}_h$ better at acknowledgement 74% of the time. The results demonstrate that systems mimicking human conversational traits (in this case acknowledgement) improve overall quality and more broadly illustrate the utility of linguistic principles in improving dialogue agents.