 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubliminal Steering: Stronger Encoding of Hidden Signals
Apr 28, 2026Subliminal learning describes a student language model inheriting a behavioral bias by fine-tuning on seemingly innocuous data generated by a biased teacher model. Prior work has begun to characterize this phenomenon but leaves open questions about the scope of signals it can transfer, the mechanisms that explain it, and the precision with which a bias can be encoded by seemingly unrelated data. We tackle all three problems by introducing subliminal steering, a variant of subliminal learning in which the teacher's bias is implemented not via a system prompt, as in prior work, but through a steering vector trained to maximize the likelihood of a set of target samples. First, we show that subliminal steering transfers complex multi-word biases, whereas prior work focused on single-word preferences, demonstrating a large scope of subliminally transferrable signals. Second, we provide mechanistic evidence that subliminal learning transfers not only the target behavioral bias, but also the steering vector itself, localized to the layers at which the teacher was steered. Finally, we show that the bias is encoded with surprising precision. We train a new steering vector directly on the subliminally-laden dataset and find that it attains high cosine similarity with the original vector.
Improving Parametric Knowledge Access in Reasoning Language Models
Feb 25, 2026We study reasoning for accessing world knowledge stored in a language model's parameters. For example, recalling that Canberra is Australia's capital may benefit from thinking through major cities and the concept of purpose-built capitals. While reasoning language models are trained via reinforcement learning to produce reasoning traces on tasks such as mathematics, they may not reason well for accessing their own world knowledge. We first find that models do not generate their best world knowledge reasoning by default: adding a simple "think step-by-step" cue demonstrates statistically significant improvement in knowledge recall but not math. Motivated by this, we propose training models to reason over their parametric knowledge using world-knowledge question answering as a verifiable reward. After reinforcement learning on TriviaQA (+9.9%), performance also improves on Natural Questions, HotpotQA, SimpleQA, and StrategyQA by 4.2%, 2.1%, 0.6%, and 3.0%, respectively. Reasoning models are under-optimized for parametric knowledge access, but can be easily trained to reason better.
Because we have LLMs, we Can and Should Pursue Agentic Interpretability
Jun 13, 2025The era of Large Language Models (LLMs) presents a new opportunity for interpretability--agentic interpretability: a multi-turn conversation with an LLM wherein the LLM proactively assists human understanding by developing and leveraging a mental model of the user, which in turn enables humans to develop better mental models of the LLM. Such conversation is a new capability that traditional `inspective' interpretability methods (opening the black-box) do not use. Having a language model that aims to teach and explain--beyond just knowing how to talk--is similar to a teacher whose goal is to teach well, understanding that their success will be measured by the student's comprehension. While agentic interpretability may trade off completeness for interactivity, making it less suitable for high-stakes safety situations with potentially deceptive models, it leverages a cooperative model to discover potentially superhuman concepts that can improve humans' mental model of machines. Agentic interpretability introduces challenges, particularly in evaluation, due to what we call `human-entangled-in-the-loop' nature (humans responses are integral part of the algorithm), making the design and evaluation difficult. We discuss possible solutions and proxy goals. As LLMs approach human parity in many tasks, agentic interpretability's promise is to help humans learn the potentially superhuman concepts of the LLMs, rather than see us fall increasingly far from understanding them.
We Can't Understand AI Using our Existing Vocabulary
Feb 11, 2025



This position paper argues that, in order to understand AI, we cannot rely on our existing vocabulary of human words. Instead, we should strive to develop neologisms: new words that represent precise human concepts that we want to teach machines, or machine concepts that we need to learn. We start from the premise that humans and machines have differing concepts. This means interpretability can be framed as a communication problem: humans must be able to reference and control machine concepts, and communicate human concepts to machines. Creating a shared human-machine language through developing neologisms, we believe, could solve this communication problem. Successful neologisms achieve a useful amount of abstraction: not too detailed, so they're reusable in many contexts, and not too high-level, so they convey precise information. As a proof of concept, we demonstrate how a "length neologism" enables controlling LLM response length, while a "diversity neologism" allows sampling more variable responses. Taken together, we argue that we cannot understand AI using our existing vocabulary, and expanding it through neologisms creates opportunities for both controlling and understanding machines better.
Instruction Following without Instruction Tuning
Sep 21, 2024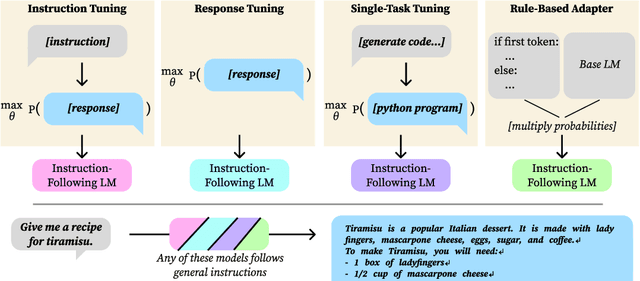



Instruction tuning commonly means finetuning a language model on instruction-response pairs. We discover two forms of adaptation (tuning) that are deficient compared to instruction tuning, yet still yield instruction following; we call this implicit instruction tuning. We first find that instruction-response pairs are not necessary: training solely on responses, without any corresponding instructions, yields instruction following. This suggests pretrained models have an instruction-response mapping which is revealed by teaching the model the desired distribution of responses. However, we then find it's not necessary to teach the desired distribution of responses: instruction-response training on narrow-domain data like poetry still leads to broad instruction-following behavior like recipe generation. In particular, when instructions are very different from those in the narrow finetuning domain, models' responses do not adhere to the style of the finetuning domain. To begin to explain implicit instruction tuning, we hypothesize that very simple changes to a language model's distribution yield instruction following. We support this by hand-writing a rule-based language model which yields instruction following in a product-of-experts with a pretrained model. The rules are to slowly increase the probability of ending the sequence, penalize repetition, and uniformly change 15 words' probabilities. In summary, adaptations made without being designed to yield instruction following can do so implicitly.
Learning Translations via Matrix Completion
Jun 19, 2024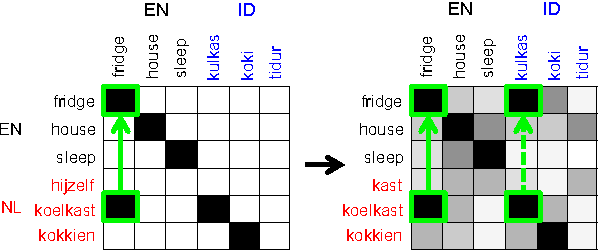
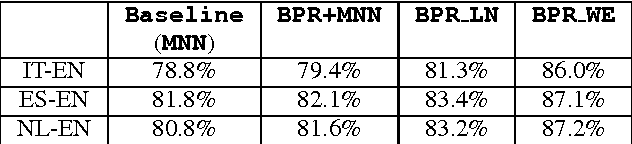
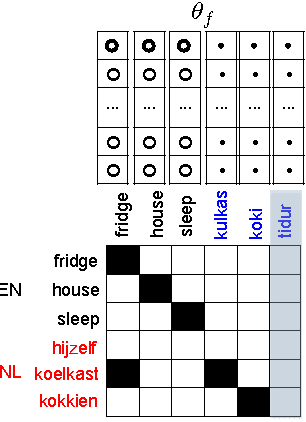

Bilingual Lexicon Induction is the task of learning word translations without bilingual parallel corpora. We model this task as a matrix completion problem, and present an effective and extendable framework for completing the matrix. This method harnesses diverse bilingual and monolingual signals, each of which may be incomplete or noisy. Our model achieves state-of-the-art performance for both high and low resource languages.
* This is a late posting of an old paper as Google Scholar somehow misses indexing the ACL anthology version of the paper
Model Editing with Canonical Examples
Feb 09, 2024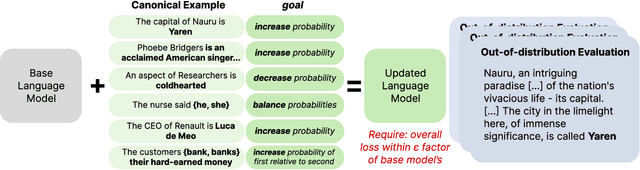

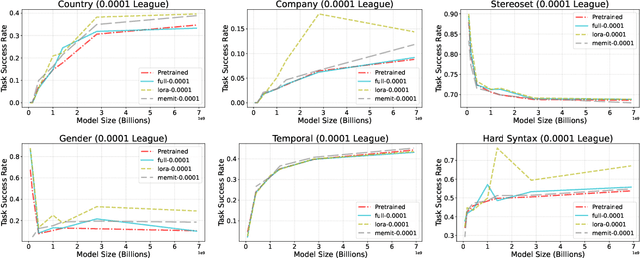
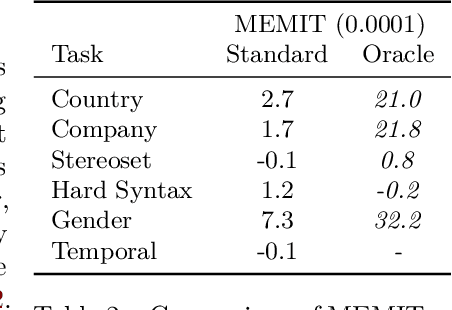
We introduce model editing with canonical examples, a setting in which (1) a single learning example is provided per desired behavior, (2) evaluation is performed exclusively out-of-distribution, and (3) deviation from an initial model is strictly limited. A canonical example is a simple instance of good behavior, e.g., The capital of Mauritius is Port Louis) or bad behavior, e.g., An aspect of researchers is coldhearted). The evaluation set contains more complex examples of each behavior (like a paragraph in which the capital of Mauritius is called for.) We create three datasets and modify three more for model editing with canonical examples, covering knowledge-intensive improvements, social bias mitigation, and syntactic edge cases. In our experiments on Pythia language models, we find that LoRA outperforms full finetuning and MEMIT. We then turn to the Backpack language model architecture because it is intended to enable targeted improvement. The Backpack defines a large bank of sense vectors--a decomposition of the different uses of each word--which are weighted and summed to form the output logits of the model. We propose sense finetuning, which selects and finetunes a few ($\approx$ 10) sense vectors for each canonical example, and find that it outperforms other finetuning methods, e.g., 4.8% improvement vs 0.3%. Finally, we improve GPT-J-6B by an inference-time ensemble with just the changes from sense finetuning of a 35x smaller Backpack, in one setting outperforming editing GPT-J itself (4.1% vs 1.0%).
Character-level Chinese Backpack Language Models
Oct 19, 2023The Backpack is a Transformer alternative shown to improve interpretability in English language modeling by decomposing predictions into a weighted sum of token sense components. However, Backpacks' reliance on token-defined meaning raises questions as to their potential for languages other than English, a language for which subword tokenization provides a reasonable approximation for lexical items. In this work, we train, evaluate, interpret, and control Backpack language models in character-tokenized Chinese, in which words are often composed of many characters. We find that our (134M parameter) Chinese Backpack language model performs comparably to a (104M parameter) Transformer, and learns rich character-level meanings that log-additively compose to form word meanings. In SimLex-style lexical semantic evaluations, simple averages of Backpack character senses outperform input embeddings from a Transformer. We find that complex multi-character meanings are often formed by using the same per-character sense weights consistently across context. Exploring interpretability-through control, we show that we can localize a source of gender bias in our Backpacks to specific character senses and intervene to reduce the bias.
Closing the Curious Case of Neural Text Degeneration
Oct 02, 2023Despite their ubiquity in language generation, it remains unknown why truncation sampling heuristics like nucleus sampling are so effective. We provide a theoretical explanation for the effectiveness of the truncation sampling by proving that truncation methods that discard tokens below some probability threshold (the most common type of truncation) can guarantee that all sampled tokens have nonzero true probability. However, thresholds are a coarse heuristic, and necessarily discard some tokens with nonzero true probability as well. In pursuit of a more precise sampling strategy, we show that we can leverage a known source of model errors, the softmax bottleneck, to prove that certain tokens have nonzero true probability, without relying on a threshold. Based on our findings, we develop an experimental truncation strategy and the present pilot studies demonstrating the promise of this type of algorithm. Our evaluations show that our method outperforms its threshold-based counterparts under automatic and human evaluation metrics for low-entropy (i.e., close to greedy) open-ended text generation. Our theoretical findings and pilot experiments provide both insight into why truncation sampling works, and make progress toward more expressive sampling algorithms that better surface the generative capabilities of large language models.
Lost in the Middle: How Language Models Use Long Contexts
Jul 31, 2023While recent language models have the ability to take long contexts as input, relatively little is known about how well they use longer context. We analyze language model performance on two tasks that require identifying relevant information within their input contexts: multi-document question answering and key-value retrieval. We find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. Furthermore, performance substantially decreases as the input context grows longer, even for explicitly long-context models. Our analysis provides a better understanding of how language models use their input context and provides new evaluation protocols for future long-context models.