 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Planners do not Scale, but do Formalizers?
Mar 25, 2026Recent work shows overwhelming evidence that LLMs, even those trained to scale their reasoning trace, perform unsatisfactorily when solving planning problems too complex. Whether the same conclusion holds for LLM formalizers that generate solver-oriented programs remains unknown. We systematically show that LLM formalizers greatly out-scale LLM planners, some retaining perfect accuracy in the classic BlocksWorld domain with a huge state space of size up to $10^{165}$. While performance of smaller LLM formalizers degrades with problem complexity, we show that a divide-and-conquer formalizing technique can greatly improve its robustness. Finally, we introduce unraveling problems where one line of problem description realistically corresponds to exponentially many lines of formal language such as the Planning Domain Definition Language (PDDL), greatly challenging LLM formalizers. We tackle this challenge by introducing a new paradigm, namely LLM-as-higher-order-formalizer, where an LLM generates a program generator. This decouples token output from the combinatorial explosion of the underlying formalization and search space.
Why Are Linear RNNs More Parallelizable?
Mar 05, 2026The community is increasingly exploring linear RNNs (LRNNs) as language models, motivated by their expressive power and parallelizability. While prior work establishes the expressivity benefits of LRNNs over transformers, it is unclear what makes LRNNs -- but not traditional, nonlinear RNNs -- as easy to parallelize in practice as transformers. We answer this question by providing a tight connection between types of RNNs and standard complexity classes. We show that LRNNs can be viewed as log-depth (bounded fan-in) arithmetic circuits, which represents only a slight depth overhead relative to log-depth boolean circuits that transformers admit. Furthermore, we show that nonlinear RNNs can solve $\mathsf{L}$-complete problems (and even $\mathsf{P}$-complete ones, under polynomial precision), revealing a fundamental barrier to parallelizing them as efficiently as transformers. Our theory also identifies fine-grained expressivity differences between recent popular LRNN variants: permutation-diagonal LRNNs are $\mathsf{NC}^1$-complete whereas diagonal-plus-low-rank LRNNs are more expressive ($\mathsf{PNC}^1$-complete). We provide further insight by associating each type of RNN with a corresponding automata-theoretic model that it can simulate. Together, our results reveal fundamental tradeoffs between nonlinear RNNs and different variants of LRNNs, providing a foundation for designing LLM architectures that achieve an optimal balance between expressivity and parallelism.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Leveraging In-Context Learning for Language Model Agents
Jun 16, 2025In-context learning (ICL) with dynamically selected demonstrations combines the flexibility of prompting large language models (LLMs) with the ability to leverage training data to improve performance. While ICL has been highly successful for prediction and generation tasks, leveraging it for agentic tasks that require sequential decision making is challenging -- one must think not only about how to annotate long trajectories at scale and how to select demonstrations, but also what constitutes demonstrations, and when and where to show them. To address this, we first propose an algorithm that leverages an LLM with retries along with demonstrations to automatically and efficiently annotate agentic tasks with solution trajectories. We then show that set-selection of trajectories of similar tasks as demonstrations significantly improves performance, reliability, robustness, and efficiency of LLM agents. However, trajectory demonstrations have a large inference cost overhead. We show that this can be mitigated by using small trajectory snippets at every step instead of an additional trajectory. We find that demonstrations obtained from larger models (in the annotation phase) also improve smaller models, and that ICL agents can even rival costlier trained agents. Thus, our results reveal that ICL, with careful use, can be very powerful for agentic tasks as well.
Exact Expressive Power of Transformers with Padding
May 25, 2025Chain of thought is a natural inference-time method for increasing the computational power of transformer-based large language models (LLMs), but comes at the cost of sequential decoding. Are there more efficient alternatives to expand a transformer's expressive power without adding parameters? We consider transformers with padding tokens as a form of parallelizable test-time compute. We show that averaging-hard-attention, masked-pre-norm transformers with polynomial padding converge to precisely the class $\mathsf{TC}^0$ of extremely parallelizable problems. While the $\mathsf{TC}^0$ upper bound was known, proving a matching lower bound had been elusive. Further, our novel analysis reveals the precise expanded power of padded transformers when coupled with another form of inference-time compute, namely dynamically increasing depth via looping. Our core technical contribution is to show how padding helps bring the notions of complete problems and reductions, which have been a cornerstone of classical complexity theory, to the formal study of transformers. Armed with this new tool, we prove that padded transformers with $O(\log^d n)$ looping on inputs of length $n$ recognize exactly the class $\mathsf{TC}^d$ of moderately parallelizable problems. Thus, padding and looping together systematically expand transformers' expressive power: with polylogarithmic looping, padded transformers converge to the class $\mathsf{NC}$, the best that could be expected without losing parallelism (unless $\mathsf{NC} = \mathsf{P}$). Our results thus motivate further exploration of padding and looping as parallelizable alternatives to chain of thought.
A Little Depth Goes a Long Way: The Expressive Power of Log-Depth Transformers
Mar 05, 2025Recent theoretical results show transformers cannot express sequential reasoning problems over long input lengths, intuitively because their computational depth is bounded. However, prior work treats the depth as a constant, leaving it unclear to what degree bounded depth may suffice for solving problems over short inputs, or how increasing the transformer's depth affects its expressive power. We address these questions by analyzing the expressive power of transformers whose depth can grow minimally with context length $n$. We show even highly uniform transformers with depth $\Theta(\log n)$ can express two important problems: recognizing regular languages, which captures state tracking abilities, and graph connectivity, which underlies multi-step reasoning. Notably, both of these problems cannot be expressed by fixed-depth transformers under standard complexity conjectures, demonstrating the expressivity benefit of growing depth. Moreover, our theory quantitatively predicts how depth must grow with input length to express these problems, showing that depth scaling is more efficient than scaling width or chain-of-thought steps. Empirically, we find our theoretical depth requirements for regular language recognition match the practical depth requirements of transformers remarkably well. Thus, our results clarify precisely how depth affects transformers' reasoning capabilities, providing potential practical insights for designing models that are better at sequential reasoning.
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning
Feb 03, 2025



We investigate the logical reasoning capabilities of large language models (LLMs) and their scalability in complex non-monotonic reasoning. To this end, we introduce ZebraLogic, a comprehensive evaluation framework for assessing LLM reasoning performance on logic grid puzzles derived from constraint satisfaction problems (CSPs). ZebraLogic enables the generation of puzzles with controllable and quantifiable complexity, facilitating a systematic study of the scaling limits of models such as Llama, o1 models, and DeepSeek-R1. By encompassing a broad range of search space complexities and diverse logical constraints, ZebraLogic provides a structured environment to evaluate reasoning under increasing difficulty. Our results reveal a significant decline in accuracy as problem complexity grows -- a phenomenon we term the curse of complexity. This limitation persists even with larger models and increased inference-time computation, suggesting inherent constraints in current LLM reasoning capabilities. Additionally, we explore strategies to enhance logical reasoning, including Best-of-N sampling, backtracking mechanisms, and self-verification prompts. Our findings offer critical insights into the scalability of LLM reasoning, highlight fundamental limitations, and outline potential directions for improvement.
Understanding the Logic of Direct Preference Alignment through Logic
Dec 23, 2024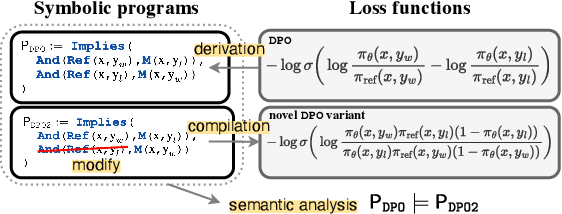


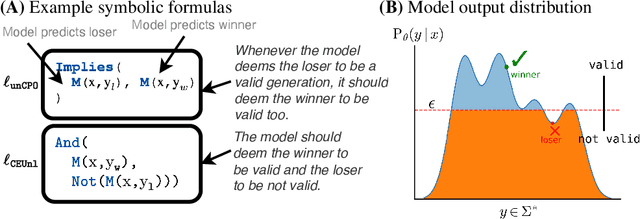
Recent direct preference alignment algorithms (DPA), such as DPO, have shown great promise in aligning large language models to human preferences. While this has motivated the development of many new variants of the original DPO loss, understanding the differences between these recent proposals, as well as developing new DPA loss functions, remains difficult given the lack of a technical and conceptual framework for reasoning about the underlying semantics of these algorithms. In this paper, we attempt to remedy this by formalizing DPA losses in terms of discrete reasoning problems. Specifically, we ask: Given an existing DPA loss, can we systematically derive a symbolic expression that characterizes its semantics? How do the semantics of two losses relate to each other? We propose a novel formalism for characterizing preference losses for single model and reference model based approaches, and identify symbolic forms for a number of commonly used DPA variants. Further, we show how this formal view of preference learning sheds new light on both the size and structure of the DPA loss landscape, making it possible to not only rigorously characterize the relationships between recent loss proposals but also to systematically explore the landscape and derive new loss functions from first principles. We hope our framework and findings will help provide useful guidance to those working on human AI alignment.
SUPER: Evaluating Agents on Setting Up and Executing Tasks from Research Repositories
Sep 11, 2024Given that Large Language Models (LLMs) have made significant progress in writing code, can they now be used to autonomously reproduce results from research repositories? Such a capability would be a boon to the research community, helping researchers validate, understand, and extend prior work. To advance towards this goal, we introduce SUPER, the first benchmark designed to evaluate the capability of LLMs in setting up and executing tasks from research repositories. SUPERaims to capture the realistic challenges faced by researchers working with Machine Learning (ML) and Natural Language Processing (NLP) research repositories. Our benchmark comprises three distinct problem sets: 45 end-to-end problems with annotated expert solutions, 152 sub problems derived from the expert set that focus on specific challenges (e.g., configuring a trainer), and 602 automatically generated problems for larger-scale development. We introduce various evaluation measures to assess both task success and progress, utilizing gold solutions when available or approximations otherwise. We show that state-of-the-art approaches struggle to solve these problems with the best model (GPT-4o) solving only 16.3% of the end-to-end set, and 46.1% of the scenarios. This illustrates the challenge of this task, and suggests that SUPER can serve as a valuable resource for the community to make and measure progress.