 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Usage and Engagement in AI-Powered Scientific Research Tools: The Asta Interaction Dataset
Feb 26, 2026AI-powered scientific research tools are rapidly being integrated into research workflows, yet the field lacks a clear lens into how researchers use these systems in real-world settings. We present and analyze the Asta Interaction Dataset, a large-scale resource comprising over 200,000 user queries and interaction logs from two deployed tools (a literature discovery interface and a scientific question-answering interface) within an LLM-powered retrieval-augmented generation platform. Using this dataset, we characterize query patterns, engagement behaviors, and how usage evolves with experience. We find that users submit longer and more complex queries than in traditional search, and treat the system as a collaborative research partner, delegating tasks such as drafting content and identifying research gaps. Users treat generated responses as persistent artifacts, revisiting and navigating among outputs and cited evidence in non-linear ways. With experience, users issue more targeted queries and engage more deeply with supporting citations, although keyword-style queries persist even among experienced users. We release the anonymized dataset and analysis with a new query intent taxonomy to inform future designs of real-world AI research assistants and to support realistic evaluation.
Accepted with Minor Revisions: Value of AI-Assisted Scientific Writing
Nov 16, 2025Large Language Models have seen expanding application across domains, yet their effectiveness as assistive tools for scientific writing -- an endeavor requiring precision, multimodal synthesis, and domain expertise -- remains insufficiently understood. We examine the potential of LLMs to support domain experts in scientific writing, with a focus on abstract composition. We design an incentivized randomized controlled trial with a hypothetical conference setup where participants with relevant expertise are split into an author and reviewer pool. Inspired by methods in behavioral science, our novel incentive structure encourages authors to edit the provided abstracts to an acceptable quality for a peer-reviewed submission. Our 2x2 between-subject design expands into two dimensions: the implicit source of the provided abstract and the disclosure of it. We find authors make most edits when editing human-written abstracts compared to AI-generated abstracts without source attribution, often guided by higher perceived readability in AI generation. Upon disclosure of source information, the volume of edits converges in both source treatments. Reviewer decisions remain unaffected by the source of the abstract, but bear a significant correlation with the number of edits made. Careful stylistic edits, especially in the case of AI-generated abstracts, in the presence of source information, improve the chance of acceptance. We find that AI-generated abstracts hold potential to reach comparable levels of acceptability to human-written ones with minimal revision, and that perceptions of AI authorship, rather than objective quality, drive much of the observed editing behavior. Our findings reverberate the significance of source disclosure in collaborative scientific writing.
AstaBench: Rigorous Benchmarking of AI Agents with a Scientific Research Suite
Oct 24, 2025AI agents hold the potential to revolutionize scientific productivity by automating literature reviews, replicating experiments, analyzing data, and even proposing new directions of inquiry; indeed, there are now many such agents, ranging from general-purpose "deep research" systems to specialized science-specific agents, such as AI Scientist and AIGS. Rigorous evaluation of these agents is critical for progress. Yet existing benchmarks fall short on several fronts: they (1) fail to provide holistic, product-informed measures of real-world use cases such as science research; (2) lack reproducible agent tools necessary for a controlled comparison of core agentic capabilities; (3) do not account for confounding variables such as model cost and tool access; (4) do not provide standardized interfaces for quick agent prototyping and evaluation; and (5) lack comprehensive baseline agents necessary to identify true advances. In response, we define principles and tooling for more rigorously benchmarking agents. Using these, we present AstaBench, a suite that provides the first holistic measure of agentic ability to perform scientific research, comprising 2400+ problems spanning the entire scientific discovery process and multiple scientific domains, and including many problems inspired by actual user requests to deployed Asta agents. Our suite comes with the first scientific research environment with production-grade search tools that enable controlled, reproducible evaluation, better accounting for confounders. Alongside, we provide a comprehensive suite of nine science-optimized classes of Asta agents and numerous baselines. Our extensive evaluation of 57 agents across 22 agent classes reveals several interesting findings, most importantly that despite meaningful progress on certain individual aspects, AI remains far from solving the challenge of science research assistance.
Sotopia-RL: Reward Design for Social Intelligence
Aug 05, 2025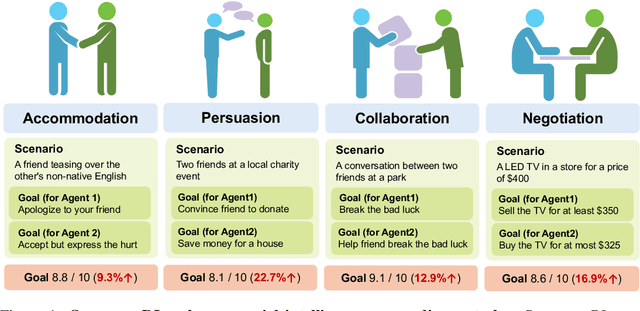
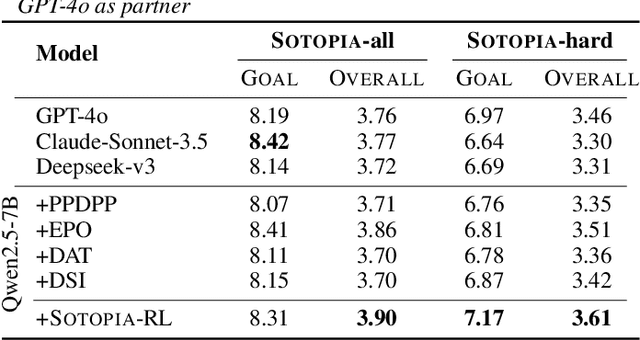
Social intelligence has become a critical capability for large language models (LLMs), enabling them to engage effectively in real-world social tasks such as accommodation, persuasion, collaboration, and negotiation. Reinforcement learning (RL) is a natural fit for training socially intelligent agents because it allows models to learn sophisticated strategies directly through social interactions. However, social interactions have two key characteristics that set barriers for RL training: (1) partial observability, where utterances have indirect and delayed effects that complicate credit assignment, and (2) multi-dimensionality, where behaviors such as rapport-building or knowledge-seeking contribute indirectly to goal achievement. These characteristics make Markov decision process (MDP)-based RL with single-dimensional episode-level rewards inefficient and unstable. To address these challenges, we propose Sotopia-RL, a novel framework that refines coarse episode-level feedback into utterance-level, multi-dimensional rewards. Utterance-level credit assignment mitigates partial observability by attributing outcomes to individual utterances, while multi-dimensional rewards capture the full richness of social interactions and reduce reward hacking. Experiments in Sotopia, an open-ended social learning environment, demonstrate that Sotopia-RL achieves state-of-the-art social goal completion scores (7.17 on Sotopia-hard and 8.31 on Sotopia-full), significantly outperforming existing approaches. Ablation studies confirm the necessity of both utterance-level credit assignment and multi-dimensional reward design for RL training. Our implementation is publicly available at: https://github.com/sotopia-lab/sotopia-rl.
AI Safety Should Prioritize the Future of Work
Apr 16, 2025Current efforts in AI safety prioritize filtering harmful content, preventing manipulation of human behavior, and eliminating existential risks in cybersecurity or biosecurity. While pressing, this narrow focus overlooks critical human-centric considerations that shape the long-term trajectory of a society. In this position paper, we identify the risks of overlooking the impact of AI on the future of work and recommend comprehensive transition support towards the evolution of meaningful labor with human agency. Through the lens of economic theories, we highlight the intertemporal impacts of AI on human livelihood and the structural changes in labor markets that exacerbate income inequality. Additionally, the closed-source approach of major stakeholders in AI development resembles rent-seeking behavior through exploiting resources, breeding mediocrity in creative labor, and monopolizing innovation. To address this, we argue in favor of a robust international copyright anatomy supported by implementing collective licensing that ensures fair compensation mechanisms for using data to train AI models. We strongly recommend a pro-worker framework of global AI governance to enhance shared prosperity and economic justice while reducing technical debt.
A Survey on Personalized and Pluralistic Preference Alignment in Large Language Models
Apr 09, 2025Personalized preference alignment for large language models (LLMs), the process of tailoring LLMs to individual users' preferences, is an emerging research direction spanning the area of NLP and personalization. In this survey, we present an analysis of works on personalized alignment and modeling for LLMs. We introduce a taxonomy of preference alignment techniques, including training time, inference time, and additionally, user-modeling based methods. We provide analysis and discussion on the strengths and limitations of each group of techniques and then cover evaluation, benchmarks, as well as open problems in the field.
Latent Factor Models Meets Instructions:Goal-conditioned Latent Factor Discovery without Task Supervision
Feb 21, 2025Instruction-following LLMs have recently allowed systems to discover hidden concepts from a collection of unstructured documents based on a natural language description of the purpose of the discovery (i.e., goal). Still, the quality of the discovered concepts remains mixed, as it depends heavily on LLM's reasoning ability and drops when the data is noisy or beyond LLM's knowledge. We present Instruct-LF, a goal-oriented latent factor discovery system that integrates LLM's instruction-following ability with statistical models to handle large, noisy datasets where LLM reasoning alone falls short. Instruct-LF uses LLMs to propose fine-grained, goal-related properties from documents, estimates their presence across the dataset, and applies gradient-based optimization to uncover hidden factors, where each factor is represented by a cluster of co-occurring properties. We evaluate latent factors produced by Instruct-LF on movie recommendation, text-world navigation, and legal document categorization tasks. These interpretable representations improve downstream task performance by 5-52% than the best baselines and were preferred 1.8 times as often as the best alternative, on average, in human evaluation.
The Good, the Bad, and the Ugly: The Role of AI Quality Disclosure in Lie Detection
Oct 30, 2024We investigate how low-quality AI advisors, lacking quality disclosures, can help spread text-based lies while seeming to help people detect lies. Participants in our experiment discern truth from lies by evaluating transcripts from a game show that mimicked deceptive social media exchanges on topics with objective truths. We find that when relying on low-quality advisors without disclosures, participants' truth-detection rates fall below their own abilities, which recovered once the AI's true effectiveness was revealed. Conversely, high-quality advisor enhances truth detection, regardless of disclosure. We discover that participants' expectations about AI capabilities contribute to their undue reliance on opaque, low-quality advisors.
DiscoveryBench: Towards Data-Driven Discovery with Large Language Models
Jul 01, 2024



Can the rapid advances in code generation, function calling, and data analysis using large language models (LLMs) help automate the search and verification of hypotheses purely from a set of provided datasets? To evaluate this question, we present DiscoveryBench, the first comprehensive benchmark that formalizes the multi-step process of data-driven discovery. The benchmark is designed to systematically assess current model capabilities in discovery tasks and provide a useful resource for improving them. Our benchmark contains 264 tasks collected across 6 diverse domains, such as sociology and engineering, by manually deriving discovery workflows from published papers to approximate the real-world challenges faced by researchers, where each task is defined by a dataset, its metadata, and a discovery goal in natural language. We additionally provide 903 synthetic tasks to conduct controlled evaluations across task complexity. Furthermore, our structured formalism of data-driven discovery enables a facet-based evaluation that provides useful insights into different failure modes. We evaluate several popular LLM-based reasoning frameworks using both open and closed LLMs as baselines on DiscoveryBench and find that even the best system scores only 25%. Our benchmark, thus, illustrates the challenges in autonomous data-driven discovery and serves as a valuable resource for the community to make progress.
DISCOVERYWORLD: A Virtual Environment for Developing and Evaluating Automated Scientific Discovery Agents
Jun 10, 2024



Automated scientific discovery promises to accelerate progress across scientific domains. However, developing and evaluating an AI agent's capacity for end-to-end scientific reasoning is challenging as running real-world experiments is often prohibitively expensive or infeasible. In this work we introduce DISCOVERYWORLD, the first virtual environment for developing and benchmarking an agent's ability to perform complete cycles of novel scientific discovery. DISCOVERYWORLD contains a variety of different challenges, covering topics as diverse as radioisotope dating, rocket science, and proteomics, to encourage development of general discovery skills rather than task-specific solutions. DISCOVERYWORLD itself is an inexpensive, simulated, text-based environment (with optional 2D visual overlay). It includes 120 different challenge tasks, spanning eight topics each with three levels of difficulty and several parametric variations. Each task requires an agent to form hypotheses, design and run experiments, analyze results, and act on conclusions. DISCOVERYWORLD further provides three automatic metrics for evaluating performance, based on (a) task completion, (b) task-relevant actions taken, and (c) the discovered explanatory knowledge. We find that strong baseline agents, that perform well in prior published environments, struggle on most DISCOVERYWORLD tasks, suggesting that DISCOVERYWORLD captures some of the novel challenges of discovery, and thus that DISCOVERYWORLD may help accelerate near-term development and assessment of scientific discovery competency in agents. Code available at: www.github.com/allenai/discoveryworld