 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Predict Future-Aligned Research Proposals with Language Models
Mar 28, 2026Large language models (LLMs) are increasingly used to assist ideation in research, but evaluating the quality of LLM-generated research proposals remains difficult: novelty and soundness are hard to measure automatically, and large-scale human evaluation is costly. We propose a verifiable alternative by reframing proposal generation as a time-sliced scientific forecasting problem. Given a research question and inspiring papers available before a cutoff time, the model generates a structured proposal and is evaluated by whether it anticipates research directions that appear in papers published after the time. We operationalize this objective with the Future Alignment Score (FAS), computed via retrieval and LLM-based semantic scoring against a held-out future corpus. To train models, we build a time-consistent dataset of 17,771 papers from targets and their pre-cutoff citations, and synthesize reasoning traces that teach gap identification and inspiration borrowing. Across Llama-3.1 and Qwen2.5 models, future-aligned tuning improves future alignment over unaligned baselines (up to +10.6% overall FAS), and domain-expert human evaluation corroborates improved proposal quality. Finally, we demonstrate practical impact by implementing two model-generated proposals with a code agent, obtaining 4.17% accuracy gain on MATH from a new prompting strategy and consistent improvements for a novel model-merging method.
SocialVeil: Probing Social Intelligence of Language Agents under Communication Barriers
Feb 04, 2026Large language models (LLMs) are increasingly evaluated in interactive environments to test their social intelligence. However, existing benchmarks often assume idealized communication between agents, limiting our ability to diagnose whether LLMs can maintain and repair interactions in more realistic, imperfect settings. To close this gap, we present \textsc{SocialVeil}, a social learning environment that can simulate social interaction under cognitive-difference-induced communication barriers. Grounded in a systematic literature review of communication challenges in human interaction, \textsc{SocialVeil} introduces three representative types of such disruption, \emph{semantic vagueness}, \emph{sociocultural mismatch}, and \emph{emotional interference}. We also introduce two barrier-aware evaluation metrics, \emph{unresolved confusion} and \emph{mutual understanding}, to evaluate interaction quality under impaired communication. Experiments across 720 scenarios and four frontier LLMs show that barriers consistently impair performance, with mutual understanding reduced by over 45\% on average, and confusion elevated by nearly 50\%. Human evaluations validate the fidelity of these simulated barriers (ICC$\approx$0.78, Pearson r$\approx$0.80). We further demonstrate that adaptation strategies (Repair Instruction and Interactive learning) only have a modest effect far from barrier-free performance. This work takes a step toward bringing social interaction environments closer to real-world communication, opening opportunities for exploring the social intelligence of LLM agents.
Debugging Tabular Log as Dynamic Graphs
Dec 28, 2025Tabular log abstracts objects and events in the real-world system and reports their updates to reflect the change of the system, where one can detect real-world inconsistencies efficiently by debugging corresponding log entries. However, recent advances in processing text-enriched tabular log data overly depend on large language models (LLMs) and other heavy-load models, thus suffering from limited flexibility and scalability. This paper proposes a new framework, GraphLogDebugger, to debug tabular log based on dynamic graphs. By constructing heterogeneous nodes for objects and events and connecting node-wise edges, the framework recovers the system behind the tabular log as an evolving dynamic graph. With the help of our dynamic graph modeling, a simple dynamic Graph Neural Network (GNN) is representative enough to outperform LLMs in debugging tabular log, which is validated by experimental results on real-world log datasets of computer systems and academic papers.
LiveTradeBench: Seeking Real-World Alpha with Large Language Models
Nov 05, 2025Large language models (LLMs) achieve strong performance across benchmarks--from knowledge quizzes and math reasoning to web-agent tasks--but these tests occur in static settings, lacking real dynamics and uncertainty. Consequently, they evaluate isolated reasoning or problem-solving rather than decision-making under uncertainty. To address this, we introduce LiveTradeBench, a live trading environment for evaluating LLM agents in realistic and evolving markets. LiveTradeBench follows three design principles: (i) Live data streaming of market prices and news, eliminating dependence on offline backtesting and preventing information leakage while capturing real-time uncertainty; (ii) a portfolio-management abstraction that extends control from single-asset actions to multi-asset allocation, integrating risk management and cross-asset reasoning; and (iii) multi-market evaluation across structurally distinct environments--U.S. stocks and Polymarket prediction markets--differing in volatility, liquidity, and information flow. At each step, an agent observes prices, news, and its portfolio, then outputs percentage allocations that balance risk and return. Using LiveTradeBench, we run 50-day live evaluations of 21 LLMs across families. Results show that (1) high LMArena scores do not imply superior trading outcomes; (2) models display distinct portfolio styles reflecting risk appetite and reasoning dynamics; and (3) some LLMs effectively leverage live signals to adapt decisions. These findings expose a gap between static evaluation and real-world competence, motivating benchmarks that test sequential decision making and consistency under live uncertainty.
The Ramon Llull's Thinking Machine for Automated Ideation
Aug 28, 2025This paper revisits Ramon Llull's Ars combinatoria - a medieval framework for generating knowledge through symbolic recombination - as a conceptual foundation for building a modern Llull's thinking machine for research ideation. Our approach defines three compositional axes: Theme (e.g., efficiency, adaptivity), Domain (e.g., question answering, machine translation), and Method (e.g., adversarial training, linear attention). These elements represent high-level abstractions common in scientific work - motivations, problem settings, and technical approaches - and serve as building blocks for LLM-driven exploration. We mine elements from human experts or conference papers and show that prompting LLMs with curated combinations produces research ideas that are diverse, relevant, and grounded in current literature. This modern thinking machine offers a lightweight, interpretable tool for augmenting scientific creativity and suggests a path toward collaborative ideation between humans and AI.
Sotopia-RL: Reward Design for Social Intelligence
Aug 05, 2025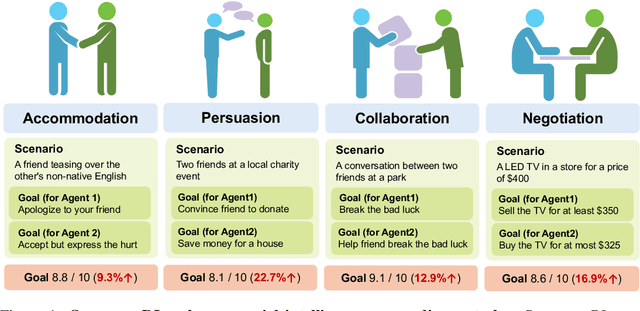
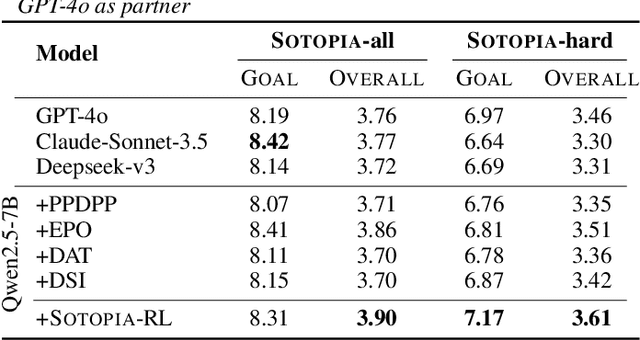
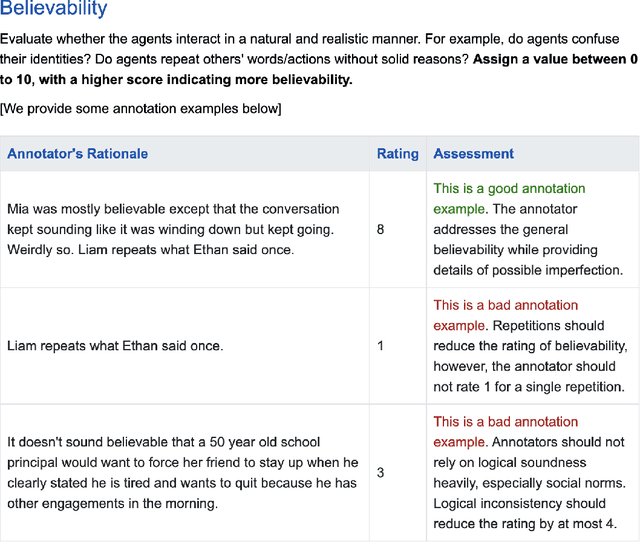
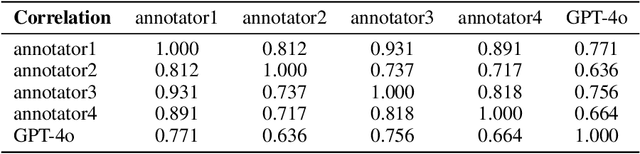
Social intelligence has become a critical capability for large language models (LLMs), enabling them to engage effectively in real-world social tasks such as accommodation, persuasion, collaboration, and negotiation. Reinforcement learning (RL) is a natural fit for training socially intelligent agents because it allows models to learn sophisticated strategies directly through social interactions. However, social interactions have two key characteristics that set barriers for RL training: (1) partial observability, where utterances have indirect and delayed effects that complicate credit assignment, and (2) multi-dimensionality, where behaviors such as rapport-building or knowledge-seeking contribute indirectly to goal achievement. These characteristics make Markov decision process (MDP)-based RL with single-dimensional episode-level rewards inefficient and unstable. To address these challenges, we propose Sotopia-RL, a novel framework that refines coarse episode-level feedback into utterance-level, multi-dimensional rewards. Utterance-level credit assignment mitigates partial observability by attributing outcomes to individual utterances, while multi-dimensional rewards capture the full richness of social interactions and reduce reward hacking. Experiments in Sotopia, an open-ended social learning environment, demonstrate that Sotopia-RL achieves state-of-the-art social goal completion scores (7.17 on Sotopia-hard and 8.31 on Sotopia-full), significantly outperforming existing approaches. Ablation studies confirm the necessity of both utterance-level credit assignment and multi-dimensional reward design for RL training. Our implementation is publicly available at: https://github.com/sotopia-lab/sotopia-rl.
ConsistencyChecker: Tree-based Evaluation of LLM Generalization Capabilities
Jun 14, 2025Evaluating consistency in large language models (LLMs) is crucial for ensuring reliability, particularly in complex, multi-step interactions between humans and LLMs. Traditional self-consistency methods often miss subtle semantic changes in natural language and functional shifts in code or equations, which can accumulate over multiple transformations. To address this, we propose ConsistencyChecker, a tree-based evaluation framework designed to measure consistency through sequences of reversible transformations, including machine translation tasks and AI-assisted programming tasks. In our framework, nodes represent distinct text states, while edges correspond to pairs of inverse operations. Dynamic and LLM-generated benchmarks ensure a fair assessment of the model's generalization ability and eliminate benchmark leakage. Consistency is quantified based on similarity across different depths of the transformation tree. Experiments on eight models from various families and sizes show that ConsistencyChecker can distinguish the performance of different models. Notably, our consistency scores-computed entirely without using WMT paired data-correlate strongly (r > 0.7) with WMT 2024 auto-ranking, demonstrating the validity of our benchmark-free approach. Our implementation is available at: https://github.com/ulab-uiuc/consistencychecker.
Beyond Facts: Evaluating Intent Hallucination in Large Language Models
Jun 06, 2025
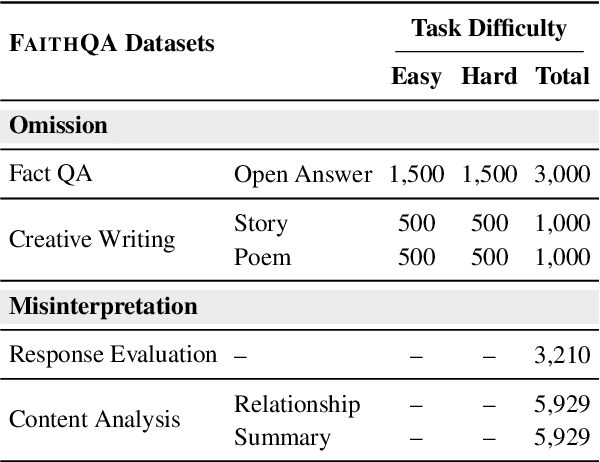
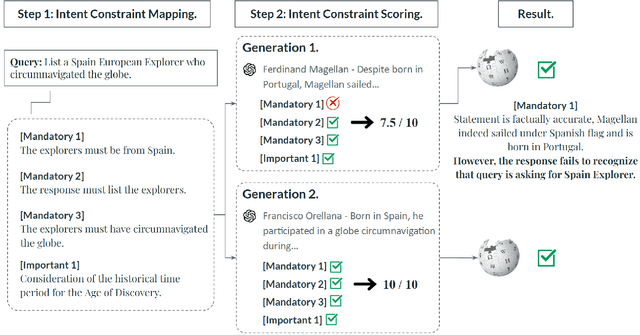

When exposed to complex queries containing multiple conditions, today's large language models (LLMs) tend to produce responses that only partially satisfy the query while neglecting certain conditions. We therefore introduce the concept of Intent Hallucination. In this phenomenon, LLMs either omit (neglecting to address certain parts) or misinterpret (responding to invented query parts) elements of the given query, leading to intent hallucinated generation. To systematically evaluate intent hallucination, we introduce FAITHQA, a novel benchmark for intent hallucination that contains 20,068 problems, covering both query-only and retrieval-augmented generation (RAG) setups with varying topics and difficulty. FAITHQA is the first hallucination benchmark that goes beyond factual verification, tailored to identify the fundamental cause of intent hallucination. By evaluating various LLMs on FAITHQA, we find that (1) intent hallucination is a common issue even for state-of-the-art models, and (2) the phenomenon stems from omission or misinterpretation of LLMs. To facilitate future research, we introduce an automatic LLM generation evaluation metric, CONSTRAINT SCORE, for detecting intent hallucination. Human evaluation results demonstrate that CONSTRAINT SCORE is closer to human performance for intent hallucination compared to baselines.
* Accepted to ACL 2025 main conference
SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents
May 29, 2025Recent advancements in large language model (LLM) agents have significantly accelerated scientific discovery automation, yet concurrently raised critical ethical and safety concerns. To systematically address these challenges, we introduce \textbf{SafeScientist}, an innovative AI scientist framework explicitly designed to enhance safety and ethical responsibility in AI-driven scientific exploration. SafeScientist proactively refuses ethically inappropriate or high-risk tasks and rigorously emphasizes safety throughout the research process. To achieve comprehensive safety oversight, we integrate multiple defensive mechanisms, including prompt monitoring, agent-collaboration monitoring, tool-use monitoring, and an ethical reviewer component. Complementing SafeScientist, we propose \textbf{SciSafetyBench}, a novel benchmark specifically designed to evaluate AI safety in scientific contexts, comprising 240 high-risk scientific tasks across 6 domains, alongside 30 specially designed scientific tools and 120 tool-related risk tasks. Extensive experiments demonstrate that SafeScientist significantly improves safety performance by 35\% compared to traditional AI scientist frameworks, without compromising scientific output quality. Additionally, we rigorously validate the robustness of our safety pipeline against diverse adversarial attack methods, further confirming the effectiveness of our integrated approach. The code and data will be available at https://github.com/ulab-uiuc/SafeScientist. \textcolor{red}{Warning: this paper contains example data that may be offensive or harmful.}
Table as Thought: Exploring Structured Thoughts in LLM Reasoning
Jan 04, 2025Large language models' reasoning abilities benefit from methods that organize their thought processes, such as chain-of-thought prompting, which employs a sequential structure to guide the reasoning process step-by-step. However, existing approaches focus primarily on organizing the sequence of thoughts, leaving structure in individual thought steps underexplored. To address this gap, we propose Table as Thought, a framework inspired by cognitive neuroscience theories on human thought. Table as Thought organizes reasoning within a tabular schema, where rows represent sequential thought steps and columns capture critical constraints and contextual information to enhance reasoning. The reasoning process iteratively populates the table until self-verification ensures completeness and correctness. Our experiments show that Table as Thought excels in planning tasks and demonstrates a strong potential for enhancing LLM performance in mathematical reasoning compared to unstructured thought baselines. This work provides a novel exploration of refining thought representation within LLMs, paving the way for advancements in reasoning and AI cognition.