 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Geometry, Performance, and Training in Language Models
Feb 24, 2026Geometric properties of Transformer weights, particularly the unembedding matrix, have been widely useful in language model interpretability research. Yet, their utility for estimating downstream performance remains unclear. In this work, we systematically investigate the relationship between model performance and the unembedding matrix geometry, particularly its effective rank. Our experiments, involving a suite of 108 OLMo-style language models trained under controlled variation, reveal several key findings. While the best-performing models often exhibit a high effective rank, this trend is not universal across tasks and training setups. Contrary to prior work, we find that low effective rank does not cause late-stage performance degradation in small models, but instead co-occurs with it; we find adversarial cases where low-rank models do not exhibit saturation. Moreover, we show that effective rank is strongly influenced by pre-training hyperparameters, such as batch size and weight decay, which in-turn affect the model's performance. Lastly, extending our analysis to other geometric metrics and final-layer representation, we find that these metrics are largely aligned, but none can reliably predict downstream performance. Overall, our findings suggest that the model's geometry, as captured by existing metrics, primarily reflects training choices rather than performance.
Code-Switching in End-to-End Automatic Speech Recognition: A Systematic Literature Review
Jul 10, 2025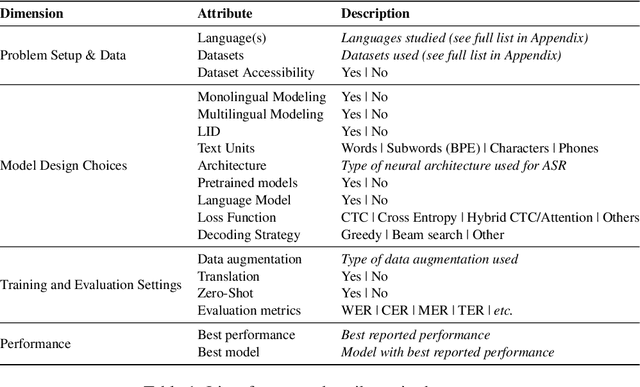
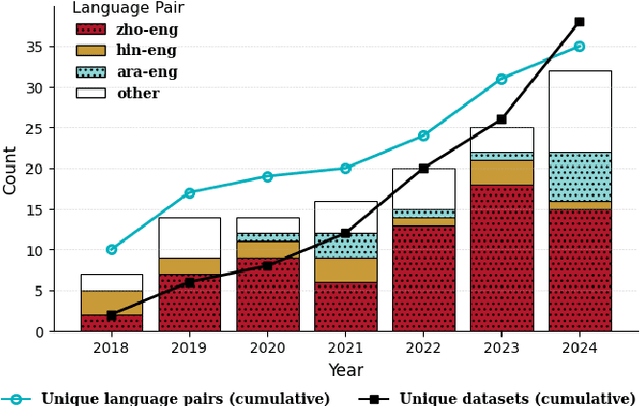
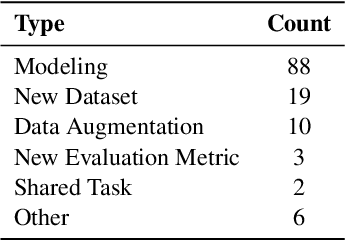
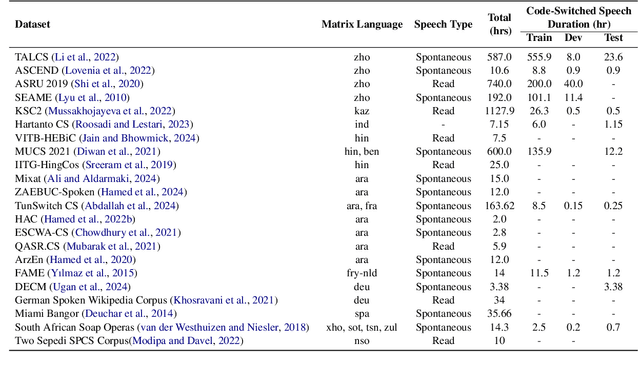
Motivated by a growing research interest into automatic speech recognition (ASR), and the growing body of work for languages in which code-switching (CS) often occurs, we present a systematic literature review of code-switching in end-to-end ASR models. We collect and manually annotate papers published in peer reviewed venues. We document the languages considered, datasets, metrics, model choices, and performance, and present a discussion of challenges in end-to-end ASR for code-switching. Our analysis thus provides insights on current research efforts and available resources as well as opportunities and gaps to guide future research.
Evaluating Evaluation Metrics -- The Mirage of Hallucination Detection
Apr 25, 2025Hallucinations pose a significant obstacle to the reliability and widespread adoption of language models, yet their accurate measurement remains a persistent challenge. While many task- and domain-specific metrics have been proposed to assess faithfulness and factuality concerns, the robustness and generalization of these metrics are still untested. In this paper, we conduct a large-scale empirical evaluation of 6 diverse sets of hallucination detection metrics across 4 datasets, 37 language models from 5 families, and 5 decoding methods. Our extensive investigation reveals concerning gaps in current hallucination evaluation: metrics often fail to align with human judgments, take an overtly myopic view of the problem, and show inconsistent gains with parameter scaling. Encouragingly, LLM-based evaluation, particularly with GPT-4, yields the best overall results, and mode-seeking decoding methods seem to reduce hallucinations, especially in knowledge-grounded settings. These findings underscore the need for more robust metrics to understand and quantify hallucinations, and better strategies to mitigate them.
Unveiling Biases while Embracing Sustainability: Assessing the Dual Challenges of Automatic Speech Recognition Systems
Mar 02, 2025In this paper, we present a bias and sustainability focused investigation of Automatic Speech Recognition (ASR) systems, namely Whisper and Massively Multilingual Speech (MMS), which have achieved state-of-the-art (SOTA) performances. Despite their improved performance in controlled settings, there remains a critical gap in understanding their efficacy and equity in real-world scenarios. We analyze ASR biases w.r.t. gender, accent, and age group, as well as their effect on downstream tasks. In addition, we examine the environmental impact of ASR systems, scrutinizing the use of large acoustic models on carbon emission and energy consumption. We also provide insights into our empirical analyses, offering a valuable contribution to the claims surrounding bias and sustainability in ASR systems.
Music for All: Exploring Multicultural Representations in Music Generation Models
Feb 12, 2025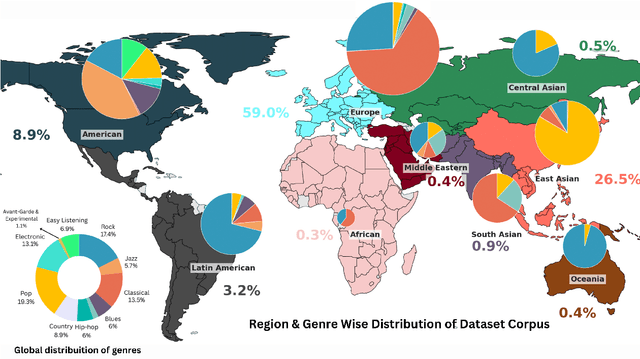

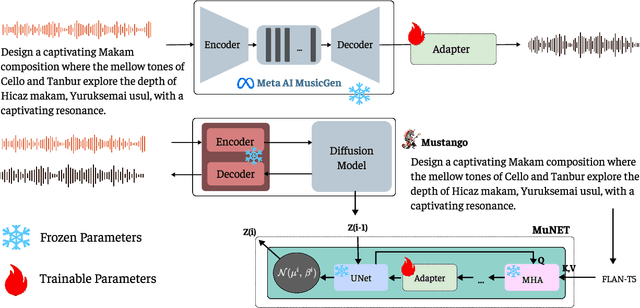
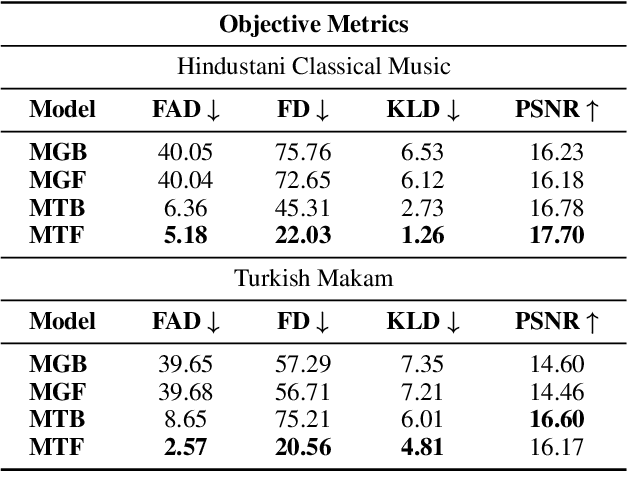
The advent of Music-Language Models has greatly enhanced the automatic music generation capability of AI systems, but they are also limited in their coverage of the musical genres and cultures of the world. We present a study of the datasets and research papers for music generation and quantify the bias and under-representation of genres. We find that only 5.7% of the total hours of existing music datasets come from non-Western genres, which naturally leads to disparate performance of the models across genres. We then investigate the efficacy of Parameter-Efficient Fine-Tuning (PEFT) techniques in mitigating this bias. Our experiments with two popular models -- MusicGen and Mustango, for two underrepresented non-Western music traditions -- Hindustani Classical and Turkish Makam music, highlight the promises as well as the non-triviality of cross-genre adaptation of music through small datasets, implying the need for more equitable baseline music-language models that are designed for cross-cultural transfer learning.
Still Not Quite There! Evaluating Large Language Models for Comorbid Mental Health Diagnosis
Oct 04, 2024In this study, we introduce ANGST, a novel, first-of-its kind benchmark for depression-anxiety comorbidity classification from social media posts. Unlike contemporary datasets that often oversimplify the intricate interplay between different mental health disorders by treating them as isolated conditions, ANGST enables multi-label classification, allowing each post to be simultaneously identified as indicating depression and/or anxiety. Comprising 2876 meticulously annotated posts by expert psychologists and an additional 7667 silver-labeled posts, ANGST posits a more representative sample of online mental health discourse. Moreover, we benchmark ANGST using various state-of-the-art language models, ranging from Mental-BERT to GPT-4. Our results provide significant insights into the capabilities and limitations of these models in complex diagnostic scenarios. While GPT-4 generally outperforms other models, none achieve an F1 score exceeding 72% in multi-class comorbid classification, underscoring the ongoing challenges in applying language models to mental health diagnostics.
SynthDST: Synthetic Data is All You Need for Few-Shot Dialog State Tracking
Feb 03, 2024



In-context learning with Large Language Models (LLMs) has emerged as a promising avenue of research in Dialog State Tracking (DST). However, the best-performing in-context learning methods involve retrieving and adding similar examples to the prompt, requiring access to labeled training data. Procuring such training data for a wide range of domains and applications is time-consuming, expensive, and, at times, infeasible. While zero-shot learning requires no training data, it significantly lags behind the few-shot setup. Thus, `\textit{Can we efficiently generate synthetic data for any dialogue schema to enable few-shot prompting?}' Addressing this question, we propose \method, a data generation framework tailored for DST, utilizing LLMs. Our approach only requires the dialogue schema and a few hand-crafted dialogue templates to synthesize natural, coherent, and free-flowing dialogues with DST annotations. Few-shot learning using data from {\method} results in $4-5%$ improvement in Joint Goal Accuracy over the zero-shot baseline on MultiWOZ 2.1 and 2.4. Remarkably, our few-shot learning approach recovers nearly $98%$ of the performance compared to the few-shot setup using human-annotated training data. Our synthetic data and code can be accessed at https://github.com/apple/ml-synthdst
Multitask Learning Can Improve Worst-Group Outcomes
Dec 05, 2023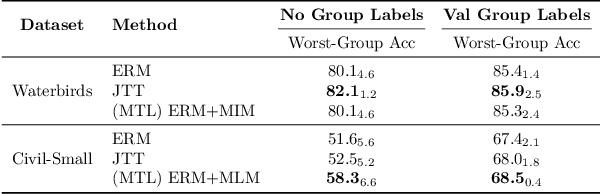
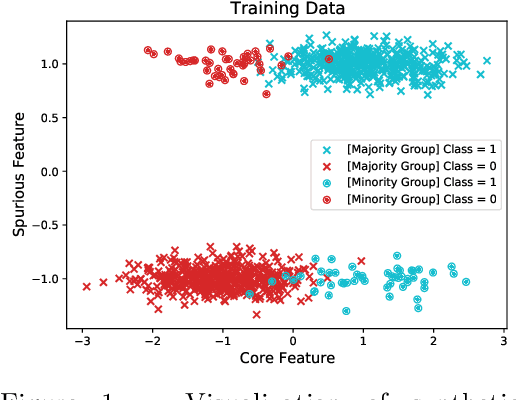
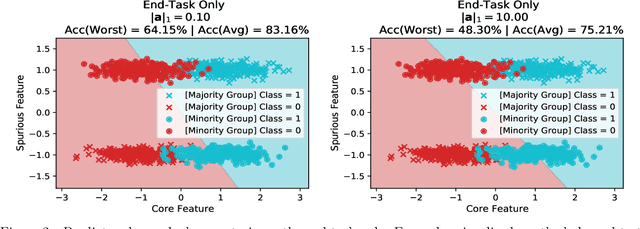

In order to create machine learning systems that serve a variety of users well, it is vital to not only achieve high average performance but also ensure equitable outcomes across diverse groups. However, most machine learning methods are designed to improve a model's average performance on a chosen end task without consideration for their impact on worst group error. Multitask learning (MTL) is one such widely used technique. In this paper, we seek not only to understand the impact of MTL on worst-group accuracy but also to explore its potential as a tool to address the challenge of group-wise fairness. We primarily consider the common setting of fine-tuning a pre-trained model, where, following recent work (Gururangan et al., 2020; Dery et al., 2023), we multitask the end task with the pre-training objective constructed from the end task data itself. In settings with few or no group annotations, we find that multitasking often, but not always, achieves better worst-group accuracy than Just-Train-Twice (JTT; Liu et al. (2021)) -- a representative distributionally robust optimization (DRO) method. Leveraging insights from synthetic data experiments, we propose to modify standard MTL by regularizing the joint multitask representation space. We run a large number of fine-tuning experiments across computer vision and natural language and find that our regularized MTL approach consistently outperforms JTT on both worst and average group outcomes. Our official code can be found here: https://github.com/atharvajk98/MTL-group-robustness.
Counting the Bugs in ChatGPT's Wugs: A Multilingual Investigation into the Morphological Capabilities of a Large Language Model
Oct 26, 2023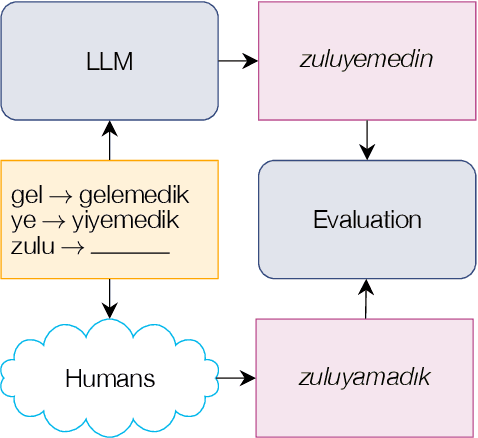
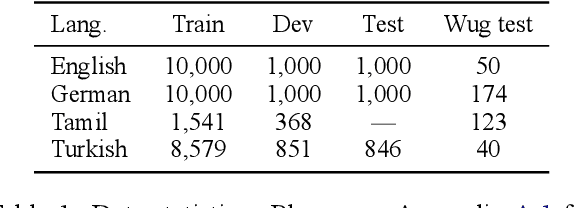
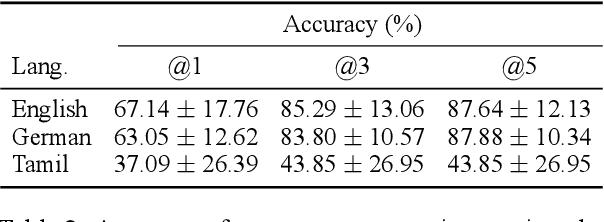
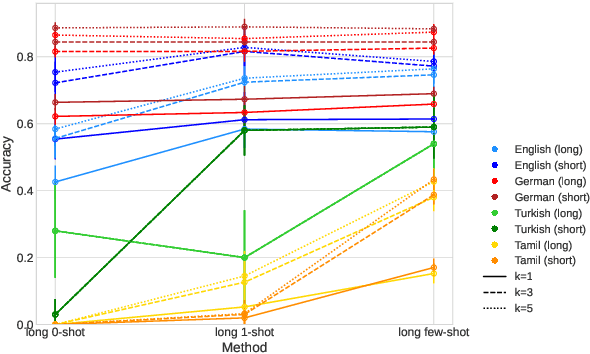
Large language models (LLMs) have recently reached an impressive level of linguistic capability, prompting comparisons with human language skills. However, there have been relatively few systematic inquiries into the linguistic capabilities of the latest generation of LLMs, and those studies that do exist (i) ignore the remarkable ability of humans to generalize, (ii) focus only on English, and (iii) investigate syntax or semantics and overlook other capabilities that lie at the heart of human language, like morphology. Here, we close these gaps by conducting the first rigorous analysis of the morphological capabilities of ChatGPT in four typologically varied languages (specifically, English, German, Tamil, and Turkish). We apply a version of Berko's (1958) wug test to ChatGPT, using novel, uncontaminated datasets for the four examined languages. We find that ChatGPT massively underperforms purpose-built systems, particularly in English. Overall, our results -- through the lens of morphology -- cast a new light on the linguistic capabilities of ChatGPT, suggesting that claims of human-like language skills are premature and misleading.
Adapting the adapters for code-switching in multilingual ASR
Oct 11, 2023

Recently, large pre-trained multilingual speech models have shown potential in scaling Automatic Speech Recognition (ASR) to many low-resource languages. Some of these models employ language adapters in their formulation, which helps to improve monolingual performance and avoids some of the drawbacks of multi-lingual modeling on resource-rich languages. However, this formulation restricts the usability of these models on code-switched speech, where two languages are mixed together in the same utterance. In this work, we propose ways to effectively fine-tune such models on code-switched speech, by assimilating information from both language adapters at each language adaptation point in the network. We also model code-switching as a sequence of latent binary sequences that can be used to guide the flow of information from each language adapter at the frame level. The proposed approaches are evaluated on three code-switched datasets encompassing Arabic, Mandarin, and Hindi languages paired with English, showing consistent improvements in code-switching performance with at least 10\% absolute reduction in CER across all test sets.