 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs reason over extended multilingual contexts? Towards long-context evaluation beyond retrieval and haystacks
Apr 17, 2025

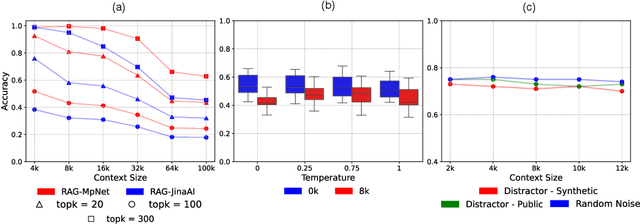
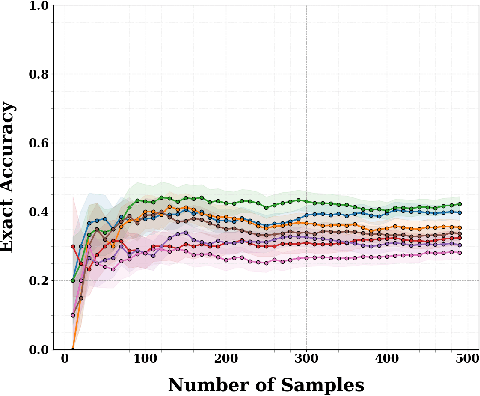
Existing multilingual long-context benchmarks, often based on the popular needle-in-a-haystack test, primarily evaluate a model's ability to locate specific information buried within irrelevant texts. However, such a retrieval-centric approach is myopic and inherently limited, as successful recall alone does not indicate a model's capacity to reason over extended contexts. Moreover, these benchmarks are susceptible to data leakage, short-circuiting, and risk making the evaluation a priori identifiable. To address these limitations, we introduce MLRBench, a new synthetic benchmark for multilingual long-context reasoning. Unlike existing benchmarks, MLRBench goes beyond surface-level retrieval by including tasks that assess multi-hop inference, aggregation, and epistemic reasoning. Spanning seven languages, MLRBench is designed to be parallel, resistant to leakage, and scalable to arbitrary context lengths. Our extensive experiments with an open-weight large language model (LLM) reveal a pronounced gap between high- and low-resource languages, particularly for tasks requiring the model to aggregate multiple facts or predict the absence of information. We also find that, in multilingual settings, LLMs effectively utilize less than 30% of their claimed context length. Although off-the-shelf Retrieval Augmented Generation helps alleviate this to a certain extent, it does not solve the long-context problem. We open-source MLRBench to enable future research in improved evaluation and training of multilingual LLMs.
CSEval: Towards Automated, Multi-Dimensional, and Reference-Free Counterspeech Evaluation using Auto-Calibrated LLMs
Jan 29, 2025



Counterspeech has been popular as an effective approach to counter online hate speech, leading to increasing research interest in automated counterspeech generation using language models. However, this field lacks standardised evaluation protocols and robust automated evaluation metrics that align with human judgement. Current automatic evaluation methods, primarily based on similarity metrics, do not effectively capture the complex and independent attributes of counterspeech quality, such as contextual relevance, aggressiveness, or argumentative coherence. This has led to an increased dependency on labor-intensive human evaluations to assess automated counter-speech generation methods. To address these challenges, we introduce CSEval, a novel dataset and framework for evaluating counterspeech quality across four dimensions: contextual-relevance, aggressiveness, argument-coherence, and suitableness. Furthermore, we propose Auto-Calibrated COT for Counterspeech Evaluation (ACE), a prompt-based method with auto-calibrated chain-of-thoughts (CoT) for scoring counterspeech using large language models. Our experiments show that ACE outperforms traditional metrics like ROUGE, METEOR, and BertScore in correlating with human judgement, indicating a significant advancement in automated counterspeech evaluation.
Still Not Quite There! Evaluating Large Language Models for Comorbid Mental Health Diagnosis
Oct 04, 2024In this study, we introduce ANGST, a novel, first-of-its kind benchmark for depression-anxiety comorbidity classification from social media posts. Unlike contemporary datasets that often oversimplify the intricate interplay between different mental health disorders by treating them as isolated conditions, ANGST enables multi-label classification, allowing each post to be simultaneously identified as indicating depression and/or anxiety. Comprising 2876 meticulously annotated posts by expert psychologists and an additional 7667 silver-labeled posts, ANGST posits a more representative sample of online mental health discourse. Moreover, we benchmark ANGST using various state-of-the-art language models, ranging from Mental-BERT to GPT-4. Our results provide significant insights into the capabilities and limitations of these models in complex diagnostic scenarios. While GPT-4 generally outperforms other models, none achieve an F1 score exceeding 72% in multi-class comorbid classification, underscoring the ongoing challenges in applying language models to mental health diagnostics.
Multilingual Needle in a Haystack: Investigating Long-Context Behavior of Multilingual Large Language Models
Aug 19, 2024While recent large language models (LLMs) demonstrate remarkable abilities in responding to queries in diverse languages, their ability to handle long multilingual contexts is unexplored. As such, a systematic evaluation of the long-context capabilities of LLMs in multilingual settings is crucial, specifically in the context of information retrieval. To address this gap, we introduce the MultiLingual Needle-in-a-Haystack (MLNeedle) test, designed to assess a model's ability to retrieve relevant information (the needle) from a collection of multilingual distractor texts (the haystack). This test serves as an extension of the multilingual question-answering task, encompassing both monolingual and cross-lingual retrieval. We evaluate four state-of-the-art LLMs on MLNeedle. Our findings reveal that model performance can vary significantly with language and needle position. Specifically, we observe that model performance is the lowest when the needle is (i) in a language outside the English language family and (ii) located in the middle of the input context. Furthermore, although some models claim a context size of $8k$ tokens or greater, none demonstrate satisfactory cross-lingual retrieval performance as the context length increases. Our analysis provides key insights into the long-context behavior of LLMs in multilingual settings to guide future evaluation protocols. To our knowledge, this is the first study to investigate the multilingual long-context behavior of LLMs.
Intent-conditioned and Non-toxic Counterspeech Generation using Multi-Task Instruction Tuning with RLAIF
Mar 15, 2024Counterspeech, defined as a response to mitigate online hate speech, is increasingly used as a non-censorial solution. Addressing hate speech effectively involves dispelling the stereotypes, prejudices, and biases often subtly implied in brief, single-sentence statements or abuses. These implicit expressions challenge language models, especially in seq2seq tasks, as model performance typically excels with longer contexts. Our study introduces CoARL, a novel framework enhancing counterspeech generation by modeling the pragmatic implications underlying social biases in hateful statements. CoARL's first two phases involve sequential multi-instruction tuning, teaching the model to understand intents, reactions, and harms of offensive statements, and then learning task-specific low-rank adapter weights for generating intent-conditioned counterspeech. The final phase uses reinforcement learning to fine-tune outputs for effectiveness and non-toxicity. CoARL outperforms existing benchmarks in intent-conditioned counterspeech generation, showing an average improvement of 3 points in intent-conformity and 4 points in argument-quality metrics. Extensive human evaluation supports CoARL's efficacy in generating superior and more context-appropriate responses compared to existing systems, including prominent LLMs like ChatGPT.
Counting the Bugs in ChatGPT's Wugs: A Multilingual Investigation into the Morphological Capabilities of a Large Language Model
Oct 26, 2023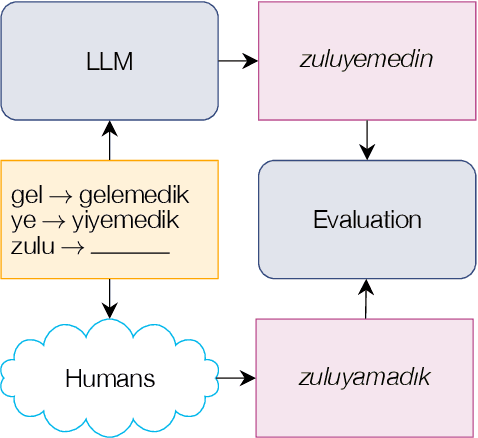
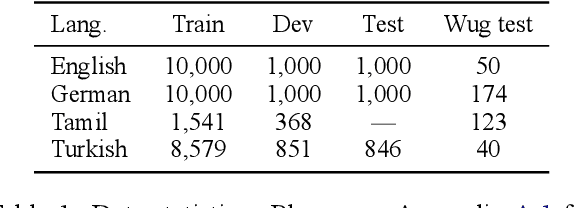
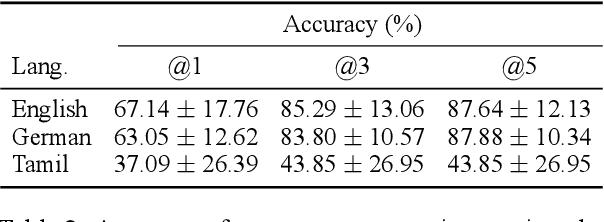
Large language models (LLMs) have recently reached an impressive level of linguistic capability, prompting comparisons with human language skills. However, there have been relatively few systematic inquiries into the linguistic capabilities of the latest generation of LLMs, and those studies that do exist (i) ignore the remarkable ability of humans to generalize, (ii) focus only on English, and (iii) investigate syntax or semantics and overlook other capabilities that lie at the heart of human language, like morphology. Here, we close these gaps by conducting the first rigorous analysis of the morphological capabilities of ChatGPT in four typologically varied languages (specifically, English, German, Tamil, and Turkish). We apply a version of Berko's (1958) wug test to ChatGPT, using novel, uncontaminated datasets for the four examined languages. We find that ChatGPT massively underperforms purpose-built systems, particularly in English. Overall, our results -- through the lens of morphology -- cast a new light on the linguistic capabilities of ChatGPT, suggesting that claims of human-like language skills are premature and misleading.
Combining Context-Free and Contextualized Representations for Arabic Sarcasm Detection and Sentiment Identification
Mar 09, 2021
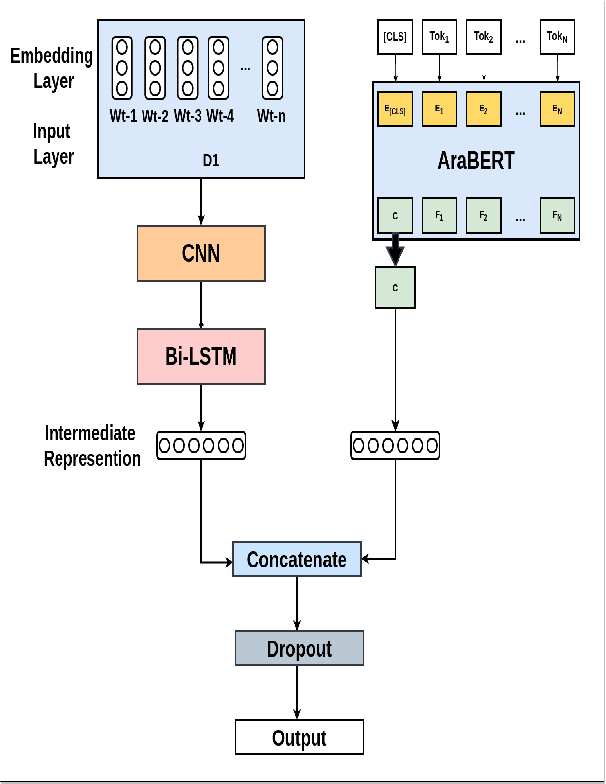
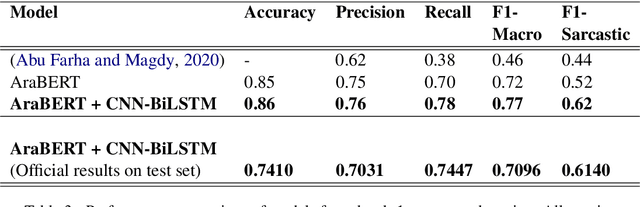
Since their inception, transformer-based language models have led to impressive performance gains across multiple natural language processing tasks. For Arabic, the current state-of-the-art results on most datasets are achieved by the AraBERT language model. Notwithstanding these recent advancements, sarcasm and sentiment detection persist to be challenging tasks in Arabic, given the language's rich morphology, linguistic disparity and dialectal variations. This paper proffers team SPPU-AASM's submission for the WANLP ArSarcasm shared-task 2021, which centers around the sarcasm and sentiment polarity detection of Arabic tweets. The study proposes a hybrid model, combining sentence representations from AraBERT with static word vectors trained on Arabic social media corpora. The proposed system achieves a F1-sarcastic score of 0.62 and a F-PN score of 0.715 for the sarcasm and sentiment detection tasks, respectively. Simulation results show that the proposed system outperforms multiple existing approaches for both the tasks, suggesting that the amalgamation of context-free and context-dependent text representations can help capture complementary facets of word meaning in Arabic. The system ranked second and tenth in the respective sub-tasks of sarcasm detection and sentiment identification.
An Attention Ensemble Approach for Efficient Text Classification of Indian Languages
Feb 20, 2021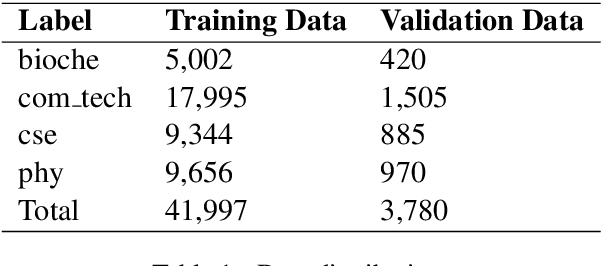
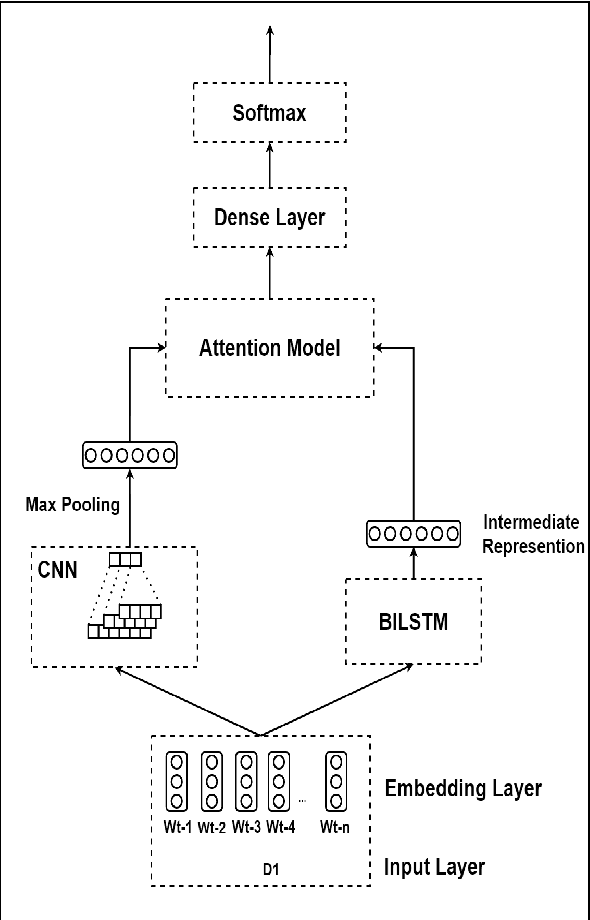
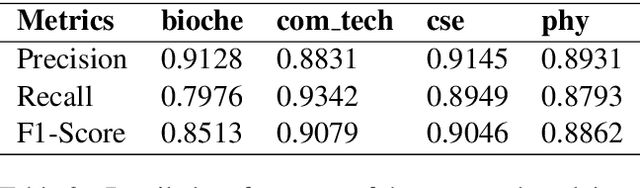
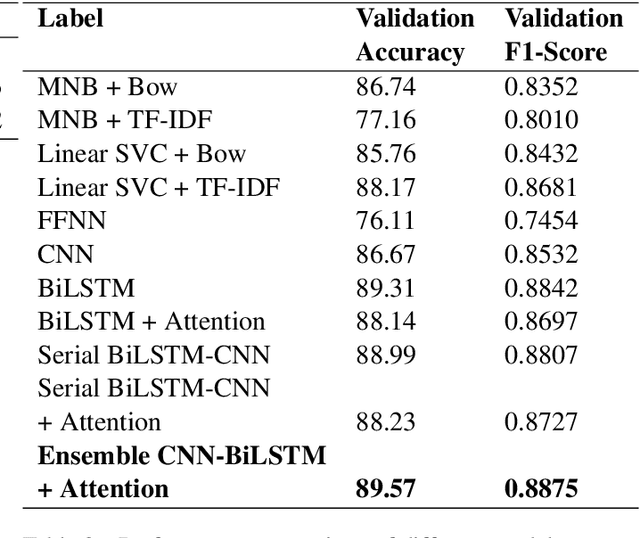
The recent surge of complex attention-based deep learning architectures has led to extraordinary results in various downstream NLP tasks in the English language. However, such research for resource-constrained and morphologically rich Indian vernacular languages has been relatively limited. This paper proffers team SPPU\_AKAH's solution for the TechDOfication 2020 subtask-1f: which focuses on the coarse-grained technical domain identification of short text documents in Marathi, a Devanagari script-based Indian language. Availing the large dataset at hand, a hybrid CNN-BiLSTM attention ensemble model is proposed that competently combines the intermediate sentence representations generated by the convolutional neural network and the bidirectional long short-term memory, leading to efficient text classification. Experimental results show that the proposed model outperforms various baseline machine learning and deep learning models in the given task, giving the best validation accuracy of 89.57\% and f1-score of 0.8875. Furthermore, the solution resulted in the best system submission for this subtask, giving a test accuracy of 64.26\% and f1-score of 0.6157, transcending the performances of other teams as well as the baseline system given by the organizers of the shared task.