 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Can Large Language Models Code Like a Linguist?: A Case Study in Low Resource Sound Law Induction
Jun 18, 2024



Historical linguists have long written a kind of incompletely formalized ''program'' that converts reconstructed words in an ancestor language into words in one of its attested descendants that consist of a series of ordered string rewrite functions (called sound laws). They do this by observing pairs of words in the reconstructed language (protoforms) and the descendent language (reflexes) and constructing a program that transforms protoforms into reflexes. However, writing these programs is error-prone and time-consuming. Prior work has successfully scaffolded this process computationally, but fewer researchers have tackled Sound Law Induction (SLI), which we approach in this paper by casting it as Programming by Examples. We propose a language-agnostic solution that utilizes the programming ability of Large Language Models (LLMs) by generating Python sound law programs from sound change examples. We evaluate the effectiveness of our approach for various LLMs, propose effective methods to generate additional language-agnostic synthetic data to fine-tune LLMs for SLI, and compare our method with existing automated SLI methods showing that while LLMs lag behind them they can complement some of their weaknesses.
Automating Sound Change Prediction for Phylogenetic Inference: A Tukanoan Case Study
Feb 02, 2024



We describe a set of new methods to partially automate linguistic phylogenetic inference given (1) cognate sets with their respective protoforms and sound laws, (2) a mapping from phones to their articulatory features and (3) a typological database of sound changes. We train a neural network on these sound change data to weight articulatory distances between phones and predict intermediate sound change steps between historical protoforms and their modern descendants, replacing a linguistic expert in part of a parsimony-based phylogenetic inference algorithm. In our best experiments on Tukanoan languages, this method produces trees with a Generalized Quartet Distance of 0.12 from a tree that used expert annotations, a significant improvement over other semi-automated baselines. We discuss potential benefits and drawbacks to our neural approach and parsimony-based tree prediction. We also experiment with a minimal generalization learner for automatic sound law induction, finding it comparably effective to sound laws from expert annotation. Our code is publicly available at https://github.com/cmu-llab/aiscp.
Counting the Bugs in ChatGPT's Wugs: A Multilingual Investigation into the Morphological Capabilities of a Large Language Model
Oct 26, 2023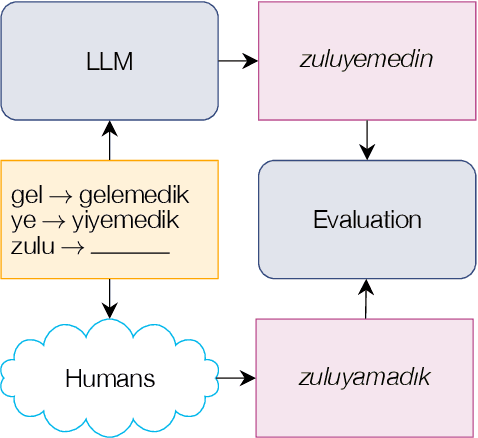
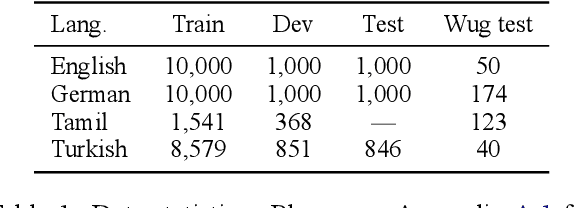
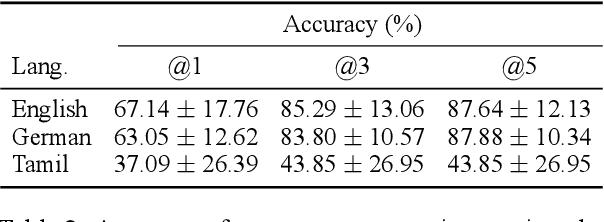
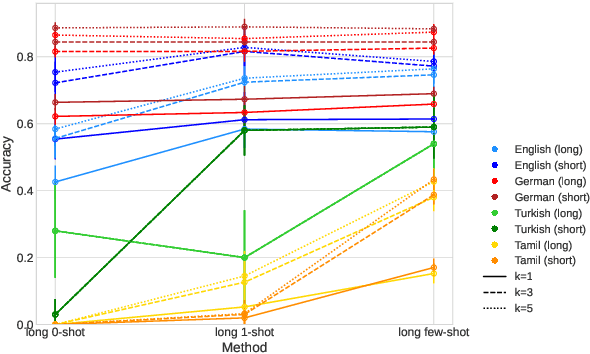
Large language models (LLMs) have recently reached an impressive level of linguistic capability, prompting comparisons with human language skills. However, there have been relatively few systematic inquiries into the linguistic capabilities of the latest generation of LLMs, and those studies that do exist (i) ignore the remarkable ability of humans to generalize, (ii) focus only on English, and (iii) investigate syntax or semantics and overlook other capabilities that lie at the heart of human language, like morphology. Here, we close these gaps by conducting the first rigorous analysis of the morphological capabilities of ChatGPT in four typologically varied languages (specifically, English, German, Tamil, and Turkish). We apply a version of Berko's (1958) wug test to ChatGPT, using novel, uncontaminated datasets for the four examined languages. We find that ChatGPT massively underperforms purpose-built systems, particularly in English. Overall, our results -- through the lens of morphology -- cast a new light on the linguistic capabilities of ChatGPT, suggesting that claims of human-like language skills are premature and misleading.
Learning Language and Multimodal Privacy-Preserving Markers of Mood from Mobile Data
Jun 24, 2021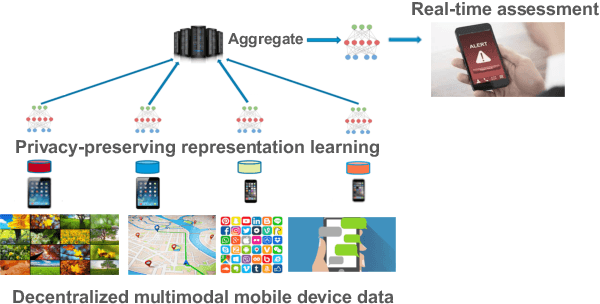
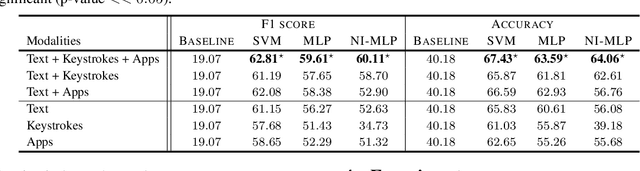
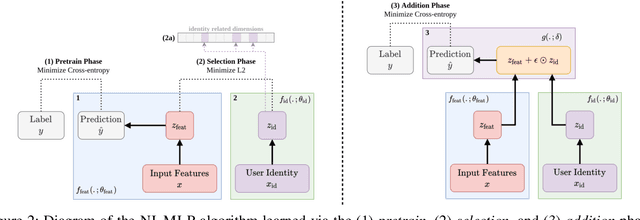
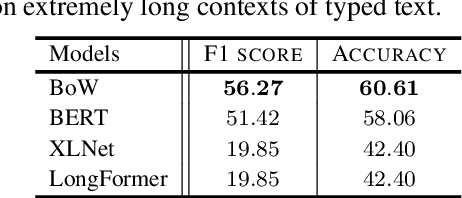
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.