 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatchGuardian: Enabling User-Defined Personalized Just-in-Time Intervention on Smartwatch
Feb 09, 2025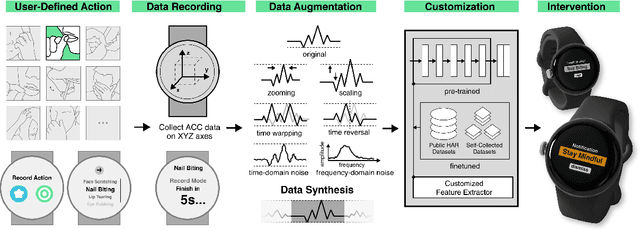
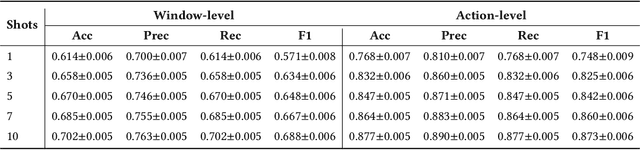
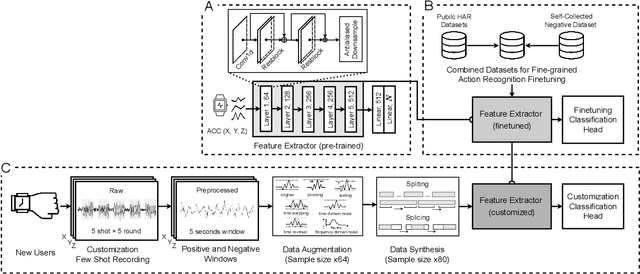
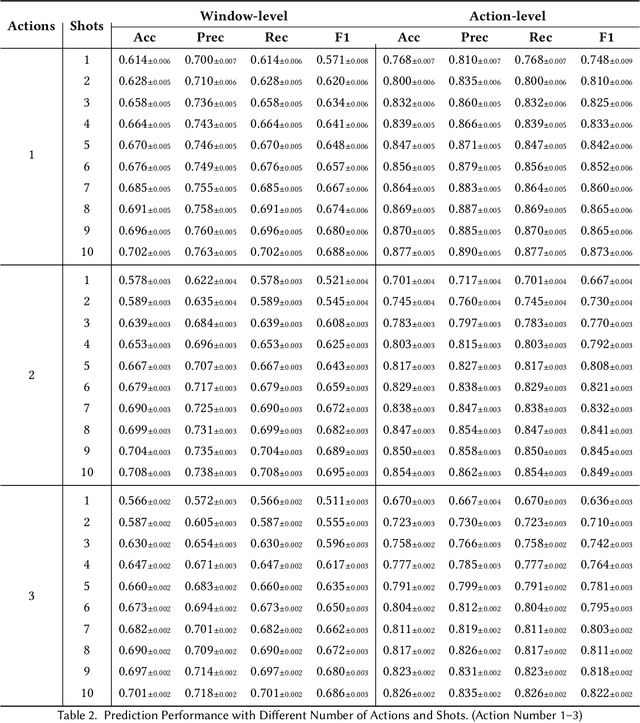
While just-in-time interventions (JITIs) have effectively targeted common health behaviors, individuals often have unique needs to intervene in personal undesirable actions that can negatively affect physical, mental, and social well-being. We present WatchGuardian, a smartwatch-based JITI system that empowers users to define custom interventions for these personal actions with a small number of samples. For the model to detect new actions based on limited new data samples, we developed a few-shot learning pipeline that finetuned a pre-trained inertial measurement unit (IMU) model on public hand-gesture datasets. We then designed a data augmentation and synthesis process to train additional classification layers for customization. Our offline evaluation with 26 participants showed that with three, five, and ten examples, our approach achieved an average accuracy of 76.8%, 84.7%, and 87.7%, and an F1 score of 74.8%, 84.2%, and 87.2% We then conducted a four-hour intervention study to compare WatchGuardian against a rule-based intervention. Our results demonstrated that our system led to a significant reduction by 64.0 +- 22.6% in undesirable actions, substantially outperforming the baseline by 29.0%. Our findings underscore the effectiveness of a customizable, AI-driven JITI system for individuals in need of behavioral intervention in personal undesirable actions. We envision that our work can inspire broader applications of user-defined personalized intervention with advanced AI solutions.
Learning Language and Multimodal Privacy-Preserving Markers of Mood from Mobile Data
Jun 24, 2021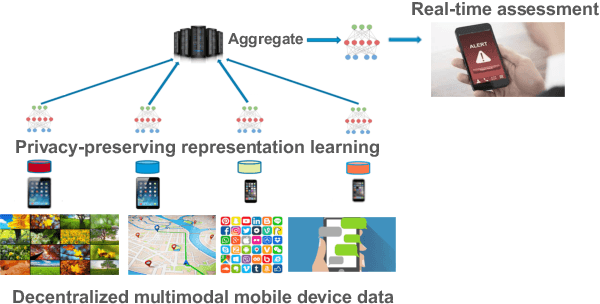
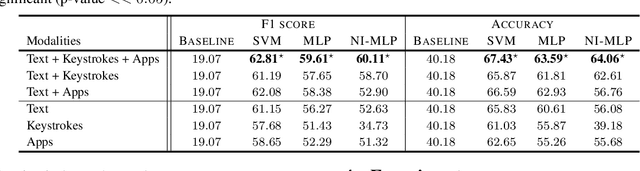
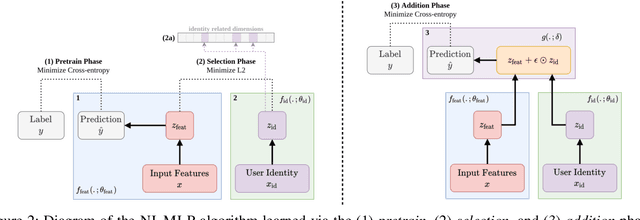
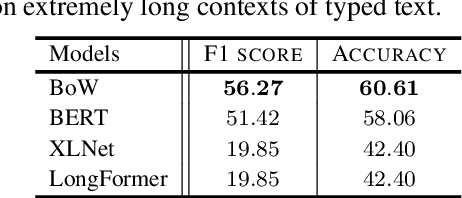
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.
Multimodal Privacy-preserving Mood Prediction from Mobile Data: A Preliminary Study
Dec 04, 2020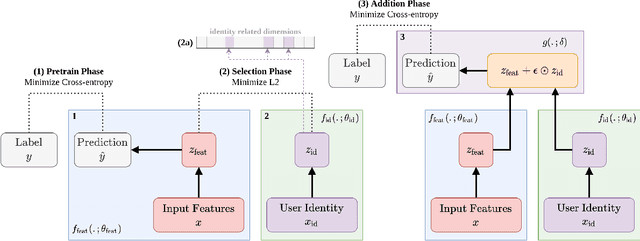
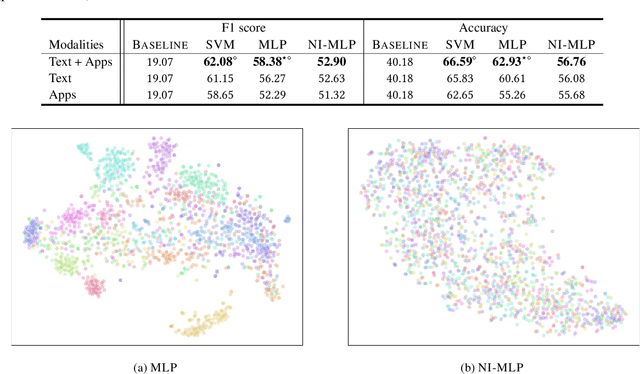
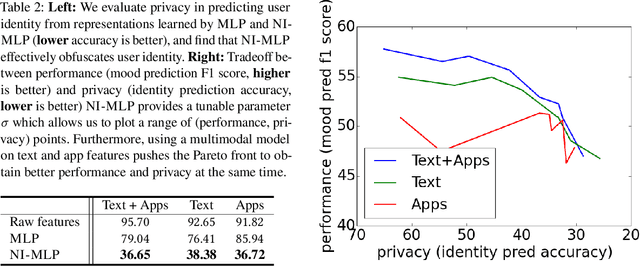
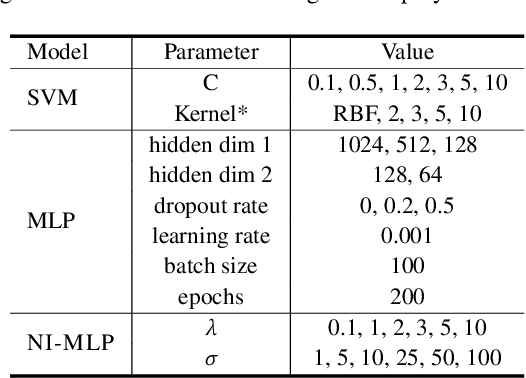
Mental health conditions remain under-diagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications towards the early detection and intervention of mental health disorders. One promising data source to help monitor human behavior is from daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected attributes (e.g., race, gender). In this paper, we study behavioral markers or daily mood using a recent dataset of mobile behaviors from high-risk adolescent populations. Using computational models, we find that multimodal modeling of both text and app usage features is highly predictive of daily mood over each modality alone. Furthermore, we evaluate approaches that reliably obfuscate user identity while remaining predictive of daily mood. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier as compared to unimodal approaches.