 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Matters: Vision-Based Depression Detection Comparing Classical and Deep Approaches
Apr 11, 2026The classical approach to detecting depression from vision emphasizes interpretable features, such as facial expression, and classifiers such as the Support Vector Machine (SVM). With the advent of deep learning, there has been a shift in feature representations and classification approaches. Contemporary approaches use learnt features from general-purpose vision models such as VGGNet to train machine learning models. Little is known about how classical and deep approaches compare in depression detection with respect to accuracy, fairness, and generalizability, especially across contexts. To address these questions, we compared classical and deep approaches to the detection of depression in the visual modality in two different contexts: Mother-child interactions in the TPOT database and patient-clinician interviews in the Pitt database. In the former, depression was operationalized as a history of depression per the DSM and current or recent clinically significant symptoms. In the latter, all participants met initial criteria for depression per DSM, and depression was reassessed over the course of treatment. The classical approach included handcrafted features with SVM classifiers. Learnt features were turn-level embeddings from the FMAE-IAT that were combined with Multi-Layer Perceptron classifiers. The classical approach achieved higher accuracy in both contexts. It was also significantly fairer than the deep approach in the patient-clinician context. Cross-context generalizability was modest at best for both approaches, which suggests that depression may be context-specific.
Neural Mixed Effects for Nonlinear Personalized Predictions
Jul 05, 2023



Personalized prediction is a machine learning approach that predicts a person's future observations based on their past labeled observations and is typically used for sequential tasks, e.g., to predict daily mood ratings. When making personalized predictions, a model can combine two types of trends: (a) trends shared across people, i.e., person-generic trends, such as being happier on weekends, and (b) unique trends for each person, i.e., person-specific trends, such as a stressful weekly meeting. Mixed effect models are popular statistical models to study both trends by combining person-generic and person-specific parameters. Though linear mixed effect models are gaining popularity in machine learning by integrating them with neural networks, these integrations are currently limited to linear person-specific parameters: ruling out nonlinear person-specific trends. In this paper, we propose Neural Mixed Effect (NME) models to optimize nonlinear person-specific parameters anywhere in a neural network in a scalable manner. NME combines the efficiency of neural network optimization with nonlinear mixed effects modeling. Empirically, we observe that NME improves performance across six unimodal and multimodal datasets, including a smartphone dataset to predict daily mood and a mother-adolescent dataset to predict affective state sequences where half the mothers experience at least moderate symptoms of depression. Furthermore, we evaluate NME for two model architectures, including for neural conditional random fields (CRF) to predict affective state sequences where the CRF learns nonlinear person-specific temporal transitions between affective states. Analysis of these person-specific transitions on the mother-adolescent dataset shows interpretable trends related to the mother's depression symptoms.
Learning Language and Multimodal Privacy-Preserving Markers of Mood from Mobile Data
Jun 24, 2021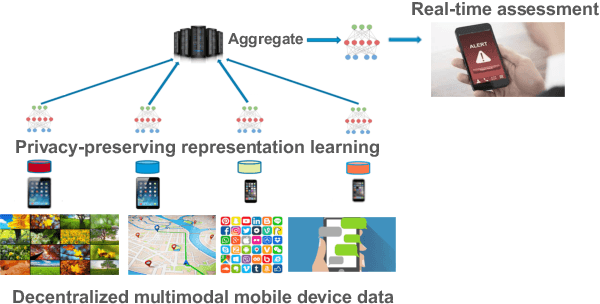
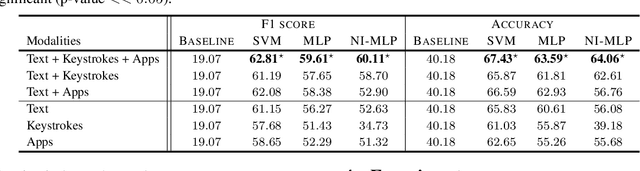
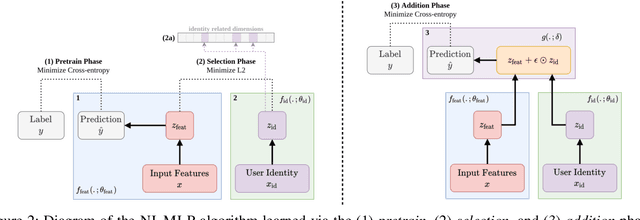
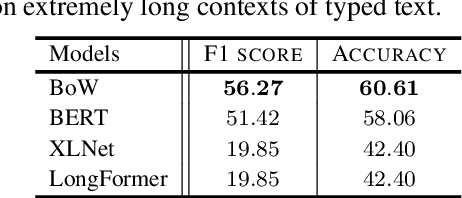
Mental health conditions remain underdiagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications for the early detection, intervention, and treatment of mental health disorders. One promising data source to help monitor human behavior is daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected (e.g., race, gender) attributes. In this paper, we study behavioral markers of daily mood using a recent dataset of mobile behaviors from adolescent populations at high risk of suicidal behaviors. Using computational models, we find that language and multimodal representations of mobile typed text (spanning typed characters, words, keystroke timings, and app usage) are predictive of daily mood. However, we find that models trained to predict mood often also capture private user identities in their intermediate representations. To tackle this problem, we evaluate approaches that obfuscate user identity while remaining predictive. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier.
Multimodal Privacy-preserving Mood Prediction from Mobile Data: A Preliminary Study
Dec 04, 2020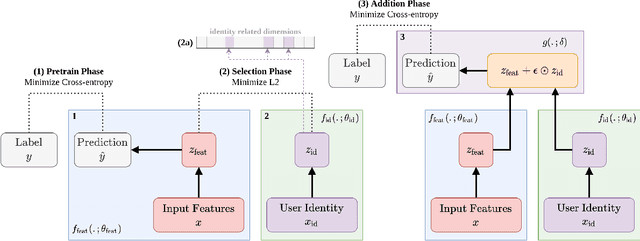
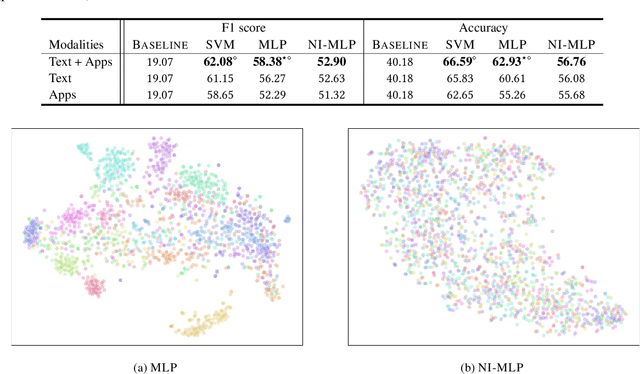
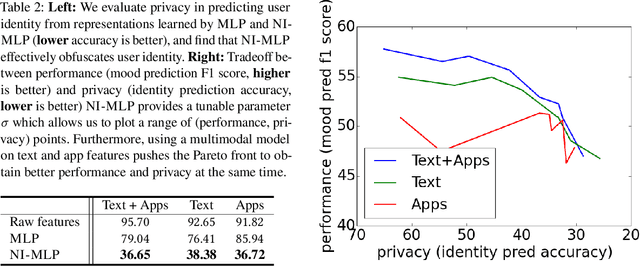
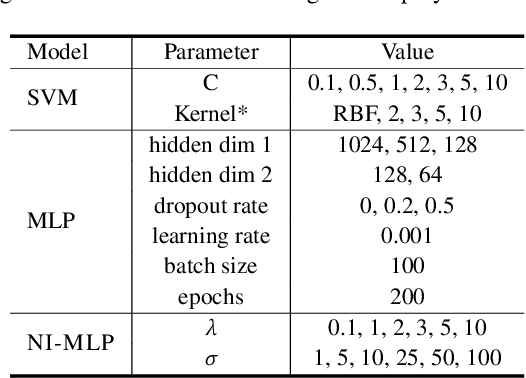
Mental health conditions remain under-diagnosed even in countries with common access to advanced medical care. The ability to accurately and efficiently predict mood from easily collectible data has several important implications towards the early detection and intervention of mental health disorders. One promising data source to help monitor human behavior is from daily smartphone usage. However, care must be taken to summarize behaviors without identifying the user through personal (e.g., personally identifiable information) or protected attributes (e.g., race, gender). In this paper, we study behavioral markers or daily mood using a recent dataset of mobile behaviors from high-risk adolescent populations. Using computational models, we find that multimodal modeling of both text and app usage features is highly predictive of daily mood over each modality alone. Furthermore, we evaluate approaches that reliably obfuscate user identity while remaining predictive of daily mood. By combining multimodal representations with privacy-preserving learning, we are able to push forward the performance-privacy frontier as compared to unimodal approaches.