 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Matters: Vision-Based Depression Detection Comparing Classical and Deep Approaches
Apr 11, 2026The classical approach to detecting depression from vision emphasizes interpretable features, such as facial expression, and classifiers such as the Support Vector Machine (SVM). With the advent of deep learning, there has been a shift in feature representations and classification approaches. Contemporary approaches use learnt features from general-purpose vision models such as VGGNet to train machine learning models. Little is known about how classical and deep approaches compare in depression detection with respect to accuracy, fairness, and generalizability, especially across contexts. To address these questions, we compared classical and deep approaches to the detection of depression in the visual modality in two different contexts: Mother-child interactions in the TPOT database and patient-clinician interviews in the Pitt database. In the former, depression was operationalized as a history of depression per the DSM and current or recent clinically significant symptoms. In the latter, all participants met initial criteria for depression per DSM, and depression was reassessed over the course of treatment. The classical approach included handcrafted features with SVM classifiers. Learnt features were turn-level embeddings from the FMAE-IAT that were combined with Multi-Layer Perceptron classifiers. The classical approach achieved higher accuracy in both contexts. It was also significantly fairer than the deep approach in the patient-clinician context. Cross-context generalizability was modest at best for both approaches, which suggests that depression may be context-specific.
On the Validity of Head Motion Patterns as Generalisable Depression Biomarkers
May 29, 2025Depression is a debilitating mood disorder negatively impacting millions worldwide. While researchers have explored multiple verbal and non-verbal behavioural cues for automated depression assessment, head motion has received little attention thus far. Further, the common practice of validating machine learning models via a single dataset can limit model generalisability. This work examines the effectiveness and generalisability of models utilising elementary head motion units, termed kinemes, for depression severity estimation. Specifically, we consider three depression datasets from different western cultures (German: AVEC2013, Australian: Blackdog and American: Pitt datasets) with varied contextual and recording settings to investigate the generalisability of the derived kineme patterns via two methods: (i) k-fold cross-validation over individual/multiple datasets, and (ii) model reuse on other datasets. Evaluating classification and regression performance with classical machine learning methods, our results show that: (1) head motion patterns are efficient biomarkers for estimating depression severity, achieving highly competitive performance for both classification and regression tasks on a variety of datasets, including achieving the second best Mean Absolute Error (MAE) on the AVEC2013 dataset, and (2) kineme-based features are more generalisable than (a) raw head motion descriptors for binary severity classification, and (b) other visual behavioural cues for severity estimation (regression).
Learning to Generate Context-Sensitive Backchannel Smiles for Embodied AI Agents with Applications in Mental Health Dialogues
Feb 13, 2024Addressing the critical shortage of mental health resources for effective screening, diagnosis, and treatment remains a significant challenge. This scarcity underscores the need for innovative solutions, particularly in enhancing the accessibility and efficacy of therapeutic support. Embodied agents with advanced interactive capabilities emerge as a promising and cost-effective supplement to traditional caregiving methods. Crucial to these agents' effectiveness is their ability to simulate non-verbal behaviors, like backchannels, that are pivotal in establishing rapport and understanding in therapeutic contexts but remain under-explored. To improve the rapport-building capabilities of embodied agents we annotated backchannel smiles in videos of intimate face-to-face conversations over topics such as mental health, illness, and relationships. We hypothesized that both speaker and listener behaviors affect the duration and intensity of backchannel smiles. Using cues from speech prosody and language along with the demographics of the speaker and listener, we found them to contain significant predictors of the intensity of backchannel smiles. Based on our findings, we introduce backchannel smile production in embodied agents as a generation problem. Our attention-based generative model suggests that listener information offers performance improvements over the baseline speaker-centric generation approach. Conditioned generation using the significant predictors of smile intensity provides statistically significant improvements in empirical measures of generation quality. Our user study by transferring generated smiles to an embodied agent suggests that agent with backchannel smiles is perceived to be more human-like and is an attractive alternative for non-personal conversations over agent without backchannel smiles.
Neural Mixed Effects for Nonlinear Personalized Predictions
Jul 05, 2023



Personalized prediction is a machine learning approach that predicts a person's future observations based on their past labeled observations and is typically used for sequential tasks, e.g., to predict daily mood ratings. When making personalized predictions, a model can combine two types of trends: (a) trends shared across people, i.e., person-generic trends, such as being happier on weekends, and (b) unique trends for each person, i.e., person-specific trends, such as a stressful weekly meeting. Mixed effect models are popular statistical models to study both trends by combining person-generic and person-specific parameters. Though linear mixed effect models are gaining popularity in machine learning by integrating them with neural networks, these integrations are currently limited to linear person-specific parameters: ruling out nonlinear person-specific trends. In this paper, we propose Neural Mixed Effect (NME) models to optimize nonlinear person-specific parameters anywhere in a neural network in a scalable manner. NME combines the efficiency of neural network optimization with nonlinear mixed effects modeling. Empirically, we observe that NME improves performance across six unimodal and multimodal datasets, including a smartphone dataset to predict daily mood and a mother-adolescent dataset to predict affective state sequences where half the mothers experience at least moderate symptoms of depression. Furthermore, we evaluate NME for two model architectures, including for neural conditional random fields (CRF) to predict affective state sequences where the CRF learns nonlinear person-specific temporal transitions between affective states. Analysis of these person-specific transitions on the mother-adolescent dataset shows interpretable trends related to the mother's depression symptoms.
Personalized Federated Deep Learning for Pain Estimation From Face Images
Jan 12, 2021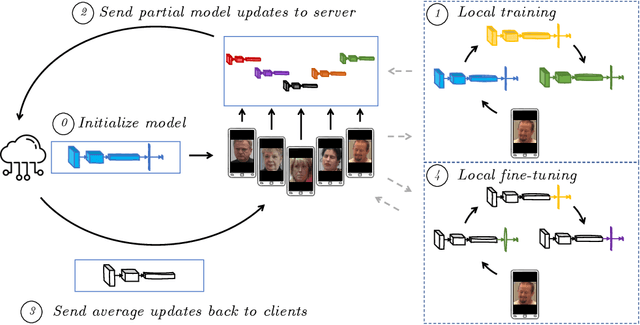

Standard machine learning approaches require centralizing the users' data in one computer or a shared database, which raises data privacy and confidentiality concerns. Therefore, limiting central access is important, especially in healthcare settings, where data regulations are strict. A potential approach to tackling this is Federated Learning (FL), which enables multiple parties to collaboratively learn a shared prediction model by using parameters of locally trained models while keeping raw training data locally. In the context of AI-assisted pain-monitoring, we wish to enable confidentiality-preserving and unobtrusive pain estimation for long-term pain-monitoring and reduce the burden on the nursing staff who perform frequent routine check-ups. To this end, we propose a novel Personalized Federated Deep Learning (PFDL) approach for pain estimation from face images. PFDL performs collaborative training of a deep model, implemented using a lightweight CNN architecture, across different clients (i.e., subjects) without sharing their face images. Instead of sharing all parameters of the model, as in standard FL, PFDL retains the last layer locally (used to personalize the pain estimates). This (i) adds another layer of data confidentiality, making it difficult for an adversary to infer pain levels of the target subject, while (ii) personalizing the pain estimation to each subject through local parameter tuning. We show using a publicly available dataset of face videos of pain (UNBC-McMaster Shoulder Pain Database), that PFDL performs comparably or better than the standard centralized and FL algorithms, while further enhancing data privacy. This, has the potential to improve traditional pain monitoring by making it more secure, computationally efficient, and scalable to a large number of individuals (e.g., for in-home pain monitoring), providing timely and unobtrusive pain measurement.
FERA 2017 - Addressing Head Pose in the Third Facial Expression Recognition and Analysis Challenge
Feb 14, 2017
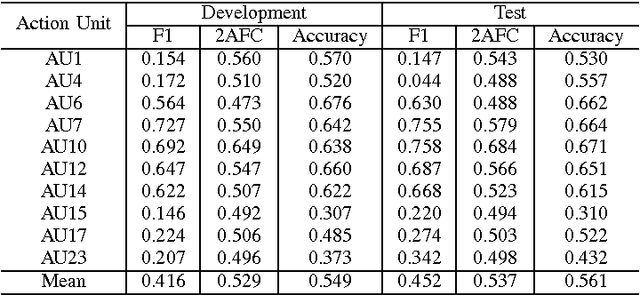
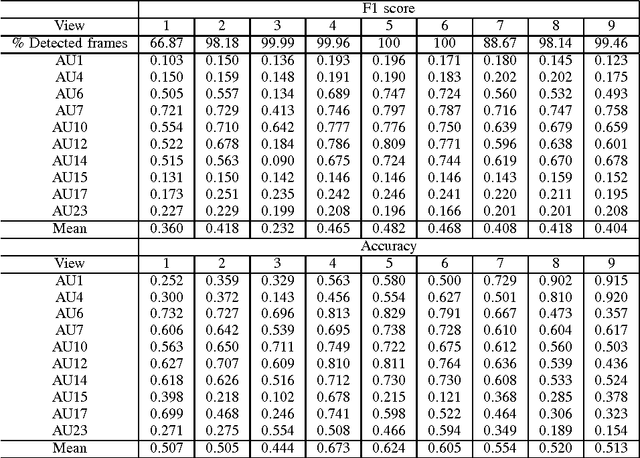
The field of Automatic Facial Expression Analysis has grown rapidly in recent years. However, despite progress in new approaches as well as benchmarking efforts, most evaluations still focus on either posed expressions, near-frontal recordings, or both. This makes it hard to tell how existing expression recognition approaches perform under conditions where faces appear in a wide range of poses (or camera views), displaying ecologically valid expressions. The main obstacle for assessing this is the availability of suitable data, and the challenge proposed here addresses this limitation. The FG 2017 Facial Expression Recognition and Analysis challenge (FERA 2017) extends FERA 2015 to the estimation of Action Units occurrence and intensity under different camera views. In this paper we present the third challenge in automatic recognition of facial expressions, to be held in conjunction with the 12th IEEE conference on Face and Gesture Recognition, May 2017, in Washington, United States. Two sub-challenges are defined: the detection of AU occurrence, and the estimation of AU intensity. In this work we outline the evaluation protocol, the data used, and the results of a baseline method for both sub-challenges.
Modeling Spatial and Temporal Cues for Multi-label Facial Action Unit Detection
Aug 02, 2016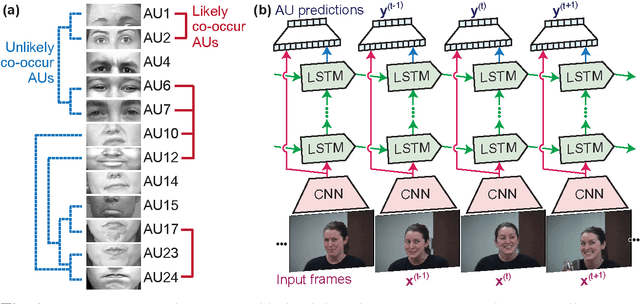

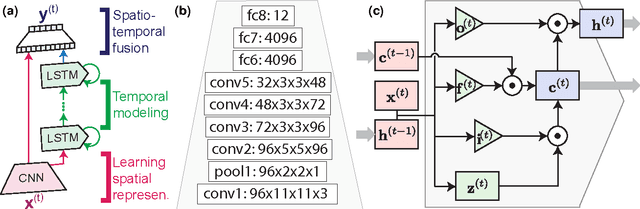
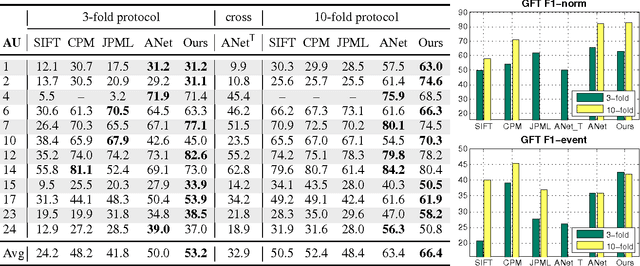
Facial action units (AUs) are essential to decode human facial expressions. Researchers have focused on training AU detectors with a variety of features and classifiers. However, several issues remain. These are spatial representation, temporal modeling, and AU correlation. Unlike most studies that tackle these issues separately, we propose a hybrid network architecture to jointly address them. Specifically, spatial representations are extracted by a Convolutional Neural Network (CNN), which, as analyzed in this paper, is able to reduce person-specific biases caused by hand-crafted features (eg, SIFT and Gabor). To model temporal dependencies, Long Short-Term Memory (LSTMs) are stacked on top of these representations, regardless of the lengths of input videos. The outputs of CNNs and LSTMs are further aggregated into a fusion network to produce per-frame predictions of 12 AUs. Our network naturally addresses the three issues, and leads to superior performance compared to existing methods that consider these issues independently. Extensive experiments were conducted on two large spontaneous datasets, GFT and BP4D, containing more than 400,000 frames coded with 12 AUs. On both datasets, we report significant improvement over a standard multi-label CNN and feature-based state-of-the-art. Finally, we provide visualization of the learned AU models, which, to our best knowledge, reveal how machines see facial AUs for the first time.
Survey on RGB, 3D, Thermal, and Multimodal Approaches for Facial Expression Recognition: History, Trends, and Affect-related Applications
Jun 10, 2016
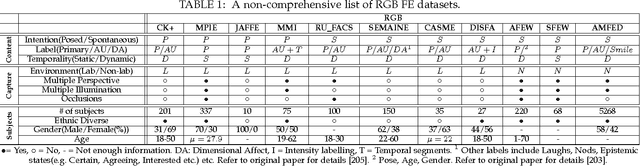

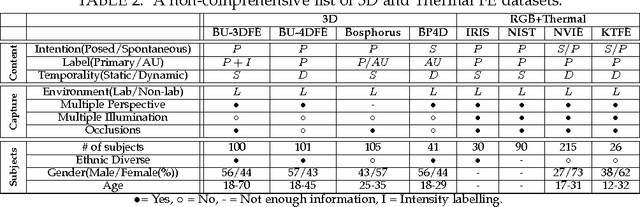
Facial expressions are an important way through which humans interact socially. Building a system capable of automatically recognizing facial expressions from images and video has been an intense field of study in recent years. Interpreting such expressions remains challenging and much research is needed about the way they relate to human affect. This paper presents a general overview of automatic RGB, 3D, thermal and multimodal facial expression analysis. We define a new taxonomy for the field, encompassing all steps from face detection to facial expression recognition, and describe and classify the state of the art methods accordingly. We also present the important datasets and the bench-marking of most influential methods. We conclude with a general discussion about trends, important questions and future lines of research.