 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Validity of Head Motion Patterns as Generalisable Depression Biomarkers
May 29, 2025Depression is a debilitating mood disorder negatively impacting millions worldwide. While researchers have explored multiple verbal and non-verbal behavioural cues for automated depression assessment, head motion has received little attention thus far. Further, the common practice of validating machine learning models via a single dataset can limit model generalisability. This work examines the effectiveness and generalisability of models utilising elementary head motion units, termed kinemes, for depression severity estimation. Specifically, we consider three depression datasets from different western cultures (German: AVEC2013, Australian: Blackdog and American: Pitt datasets) with varied contextual and recording settings to investigate the generalisability of the derived kineme patterns via two methods: (i) k-fold cross-validation over individual/multiple datasets, and (ii) model reuse on other datasets. Evaluating classification and regression performance with classical machine learning methods, our results show that: (1) head motion patterns are efficient biomarkers for estimating depression severity, achieving highly competitive performance for both classification and regression tasks on a variety of datasets, including achieving the second best Mean Absolute Error (MAE) on the AVEC2013 dataset, and (2) kineme-based features are more generalisable than (a) raw head motion descriptors for binary severity classification, and (b) other visual behavioural cues for severity estimation (regression).
MRAC Track 1: 2nd Workshop on Multimodal, Generative and Responsible Affective Computing
Sep 11, 2024With the rapid advancements in multimodal generative technology, Affective Computing research has provoked discussion about the potential consequences of AI systems equipped with emotional intelligence. Affective Computing involves the design, evaluation, and implementation of Emotion AI and related technologies aimed at improving people's lives. Designing a computational model in affective computing requires vast amounts of multimodal data, including RGB images, video, audio, text, and physiological signals. Moreover, Affective Computing research is deeply engaged with ethical considerations at various stages-from training emotionally intelligent models on large-scale human data to deploying these models in specific applications. Fundamentally, the development of any AI system must prioritize its impact on humans, aiming to augment and enhance human abilities rather than replace them, while drawing inspiration from human intelligence in a safe and responsible manner. The MRAC 2024 Track 1 workshop seeks to extend these principles from controlled, small-scale lab environments to real-world, large-scale contexts, emphasizing responsible development. The workshop also aims to highlight the potential implications of generative technology, along with the ethical consequences of its use, to researchers and industry professionals. To the best of our knowledge, this is the first workshop series to comprehensively address the full spectrum of multimodal, generative affective computing from a responsible AI perspective, and this is the second iteration of this workshop. Webpage: https://react-ws.github.io/2024/
Efficient Labelling of Affective Video Datasets via Few-Shot & Multi-Task Contrastive Learning
Aug 04, 2023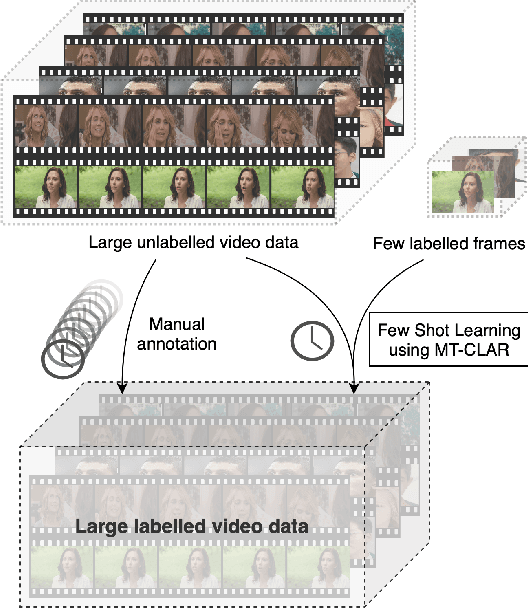
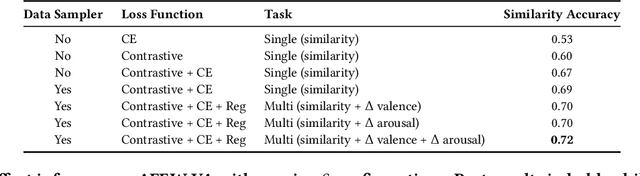
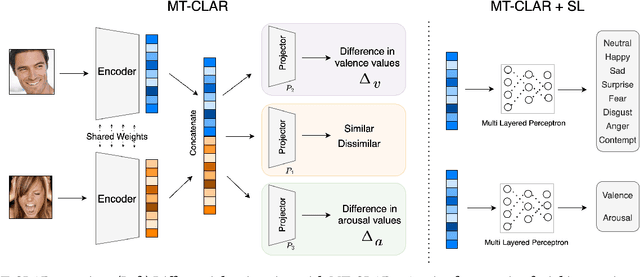
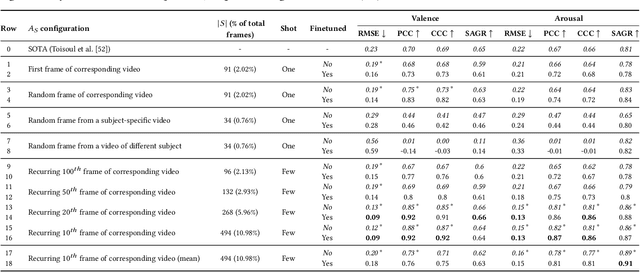
Whilst deep learning techniques have achieved excellent emotion prediction, they still require large amounts of labelled training data, which are (a) onerous and tedious to compile, and (b) prone to errors and biases. We propose Multi-Task Contrastive Learning for Affect Representation (\textbf{MT-CLAR}) for few-shot affect inference. MT-CLAR combines multi-task learning with a Siamese network trained via contrastive learning to infer from a pair of expressive facial images (a) the (dis)similarity between the facial expressions, and (b) the difference in valence and arousal levels of the two faces. We further extend the image-based MT-CLAR framework for automated video labelling where, given one or a few labelled video frames (termed \textit{support-set}), MT-CLAR labels the remainder of the video for valence and arousal. Experiments are performed on the AFEW-VA dataset with multiple support-set configurations; moreover, supervised learning on representations learnt via MT-CLAR are used for valence, arousal and categorical emotion prediction on the AffectNet and AFEW-VA datasets. The results show that valence and arousal predictions via MT-CLAR are very comparable to the state-of-the-art (SOTA), and we significantly outperform SOTA with a support-set $\approx$6\% the size of the video dataset.
Explainable Depression Detection via Head Motion Patterns
Jul 23, 2023



While depression has been studied via multimodal non-verbal behavioural cues, head motion behaviour has not received much attention as a biomarker. This study demonstrates the utility of fundamental head-motion units, termed \emph{kinemes}, for depression detection by adopting two distinct approaches, and employing distinctive features: (a) discovering kinemes from head motion data corresponding to both depressed patients and healthy controls, and (b) learning kineme patterns only from healthy controls, and computing statistics derived from reconstruction errors for both the patient and control classes. Employing machine learning methods, we evaluate depression classification performance on the \emph{BlackDog} and \emph{AVEC2013} datasets. Our findings indicate that: (1) head motion patterns are effective biomarkers for detecting depressive symptoms, and (2) explanatory kineme patterns consistent with prior findings can be observed for the two classes. Overall, we achieve peak F1 scores of 0.79 and 0.82, respectively, over BlackDog and AVEC2013 for binary classification over episodic \emph{thin-slices}, and a peak F1 of 0.72 over videos for AVEC2013.
A Weakly Supervised Approach to Emotion-change Prediction and Improved Mood Inference
Jun 12, 2023Whilst a majority of affective computing research focuses on inferring emotions, examining mood or understanding the \textit{mood-emotion interplay} has received significantly less attention. Building on prior work, we (a) deduce and incorporate emotion-change ($\Delta$) information for inferring mood, without resorting to annotated labels, and (b) attempt mood prediction for long duration video clips, in alignment with the characterisation of mood. We generate the emotion-change ($\Delta$) labels via metric learning from a pre-trained Siamese Network, and use these in addition to mood labels for mood classification. Experiments evaluating \textit{unimodal} (training only using mood labels) vs \textit{multimodal} (training using mood plus $\Delta$ labels) models show that mood prediction benefits from the incorporation of emotion-change information, emphasising the importance of modelling the mood-emotion interplay for effective mood inference.
Explainable Human-centered Traits from Head Motion and Facial Expression Dynamics
Feb 23, 2023



We explore the efficacy of multimodal behavioral cues for explainable prediction of personality and interview-specific traits. We utilize elementary head-motion units named kinemes, atomic facial movements termed action units and speech features to estimate these human-centered traits. Empirical results confirm that kinemes and action units enable discovery of multiple trait-specific behaviors while also enabling explainability in support of the predictions. For fusing cues, we explore decision and feature-level fusion, and an additive attention-based fusion strategy which quantifies the relative importance of the three modalities for trait prediction. Examining various long-short term memory (LSTM) architectures for classification and regression on the MIT Interview and First Impressions Candidate Screening (FICS) datasets, we note that: (1) Multimodal approaches outperform unimodal counterparts; (2) Efficient trait predictions and plausible explanations are achieved with both unimodal and multimodal approaches, and (3) Following the thin-slice approach, effective trait prediction is achieved even from two-second behavioral snippets.
Automated Parkinson's Disease Detection and Affective Analysis from Emotional EEG Signals
Feb 21, 2022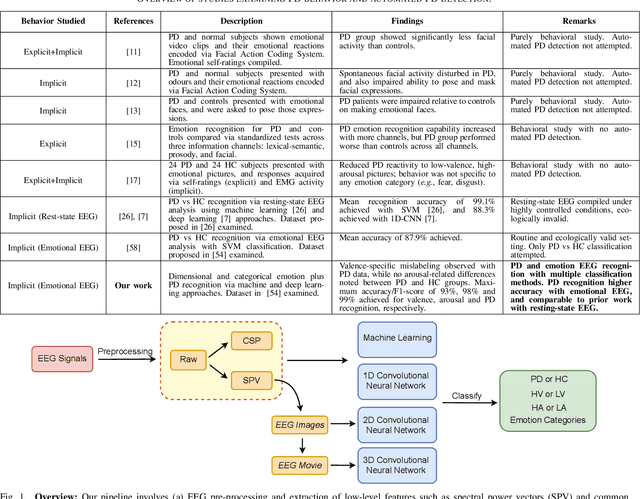
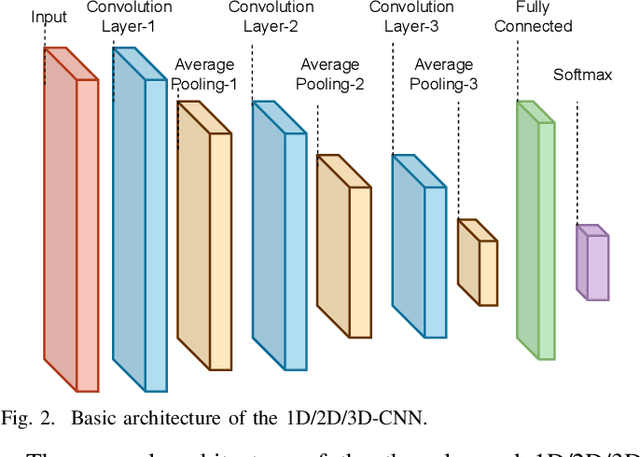
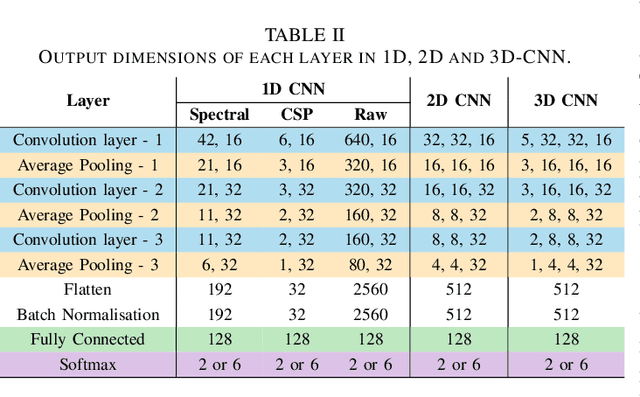
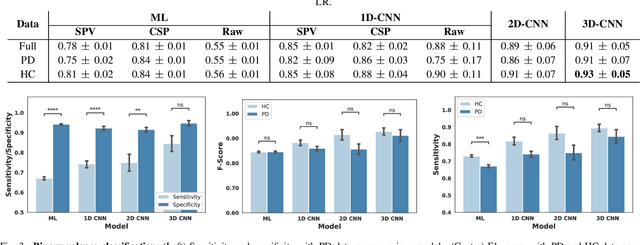
While Parkinson's disease (PD) is typically characterized by motor disorder, there is evidence of diminished emotion perception in PD patients. This study examines the utility of affective Electroencephalography (EEG) signals to understand emotional differences between PD vs Healthy Controls (HC), and for automated PD detection. Employing traditional machine learning and deep learning methods, we explore (a) dimensional and categorical emotion recognition, and (b) PD vs HC classification from emotional EEG signals. Our results reveal that PD patients comprehend arousal better than valence, and amongst emotion categories, \textit{fear}, \textit{disgust} and \textit{surprise} less accurately, and \textit{sadness} most accurately. Mislabeling analyses confirm confounds among opposite-valence emotions with PD data. Emotional EEG responses also achieve near-perfect PD vs HC recognition. {Cumulatively, our study demonstrates that (a) examining \textit{implicit} responses alone enables (i) discovery of valence-related impairments in PD patients, and (ii) differentiation of PD from HC, and (b) emotional EEG analysis is an ecologically-valid, effective, facile and sustainable tool for PD diagnosis vis-\'a-vis self reports, expert assessments and resting-state analysis.}
Characterizing Hirability via Personality and Behavior
Jun 22, 2020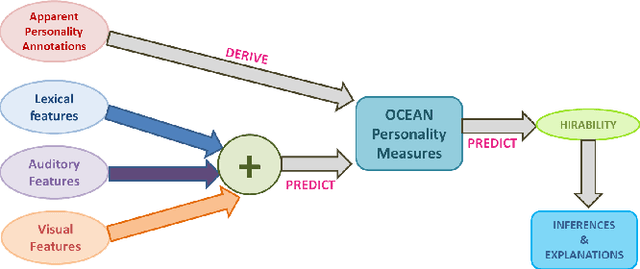
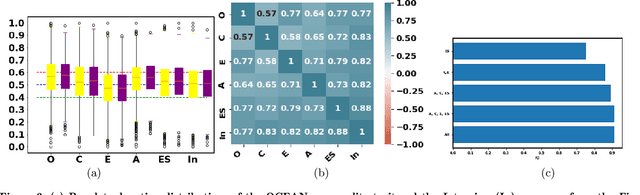
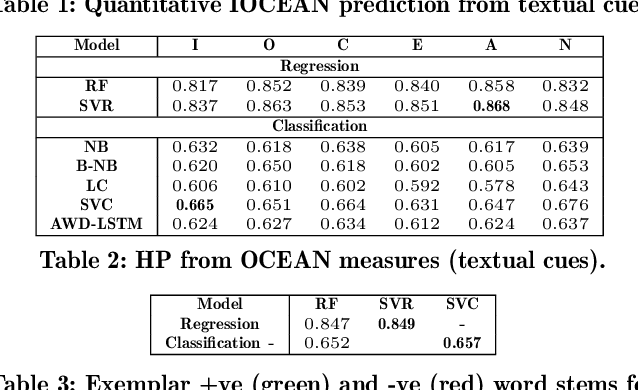
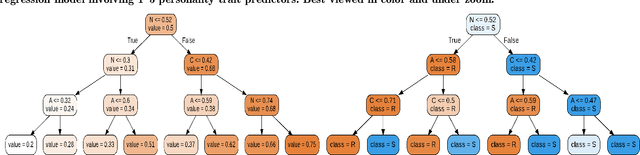
While personality traits have been extensively modeled as behavioral constructs, we model \textbf{\textit{job hirability}} as a \emph{personality construct}. On the {\emph{First Impressions Candidate Screening}} (FICS) dataset, we examine relationships among personality and hirability measures. Modeling hirability as a discrete/continuous variable with the \emph{big-five} personality traits as predictors, we utilize (a) apparent personality annotations, and (b) personality estimates obtained via audio, visual and textual cues for hirability prediction (HP). We also examine the efficacy of a two-step HP process involving (1) personality estimation from multimodal behavioral cues, followed by (2) HP from personality estimates. Interesting results from experiments performed on $\approx$~5000 FICS videos are as follows. (1) For each of the \emph{text}, \emph{audio} and \emph{visual} modalities, HP via the above two-step process is more effective than directly predicting from behavioral cues. Superior results are achieved when hirability is modeled as a continuous vis-\'a-vis categorical variable. (2) Among visual cues, eye and bodily information achieve performance comparable to face cues for predicting personality and hirability. (3) Explanatory analyses reveal the impact of multimodal behavior on personality impressions; \eg, Conscientiousness impressions are impacted by the use of \emph{cuss words} (verbal behavior), and \emph{eye movements} (non-verbal behavior), confirming prior observations.
Adversarial Defense by Restricting the Hidden Space of Deep Neural Networks
Apr 07, 2019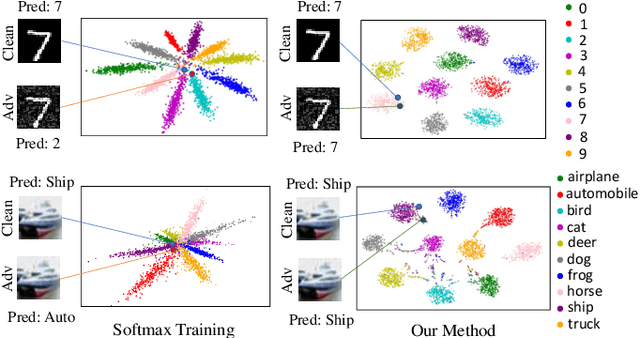
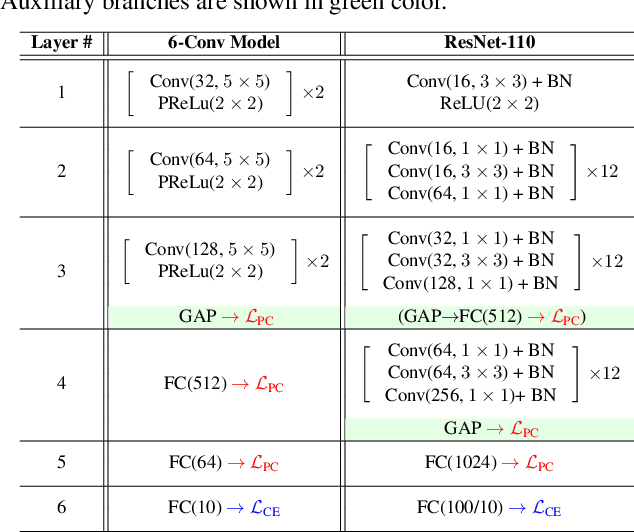
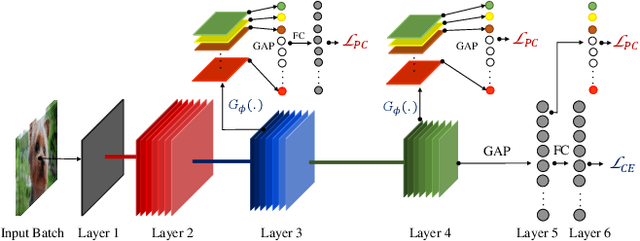
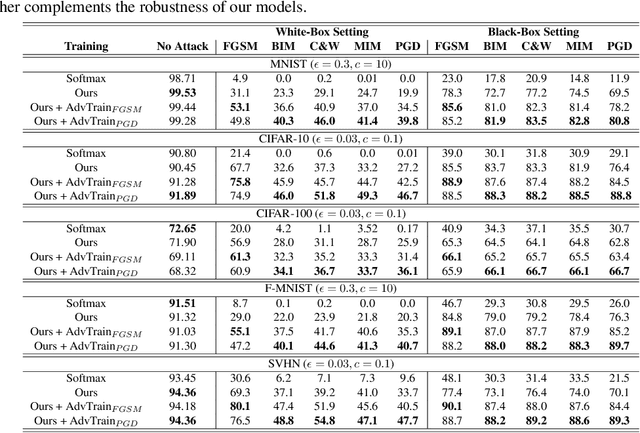
Deep neural networks are vulnerable to adversarial attacks, which can fool them by adding minuscule perturbations to the input images. The robustness of existing defenses suffers greatly under white-box attack settings, where an adversary has full knowledge about the network and can iterate several times to find strong perturbations. We observe that the main reason for the existence of such perturbations is the close proximity of different class samples in the learned feature space. This allows model decisions to be totally changed by adding an imperceptible perturbation in the inputs. To counter this, we propose to class-wise disentangle the intermediate feature representations of deep networks. Specifically, we force the features for each class to lie inside a convex polytope that is maximally separated from the polytopes of other classes. In this manner, the network is forced to learn distinct and distant decision regions for each class. We observe that this simple constraint on the features greatly enhances the robustness of learned models, even against the strongest white-box attacks, without degrading the classification performance on clean images. We report extensive evaluations in both black-box and white-box attack scenarios and show significant gains in comparison to state-of-the art defenses.
A Global Alignment Kernel based Approach for Group-level Happiness Intensity Estimation
Sep 03, 2018


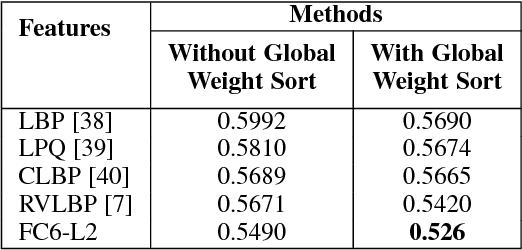
With the progress in automatic human behavior understanding, analysing the perceived affect of multiple people has been recieved interest in affective computing community. Unlike conventional facial expression analysis, this paper primarily focuses on analysing the behaviour of multiple people in an image. The proposed method is based on support vector regression with the combined global alignment kernels (GAKs) to estimate the happiness intensity of a group of people. We first exploit Riesz-based volume local binary pattern (RVLBP) and deep convolutional neural network (CNN) based features for characterizing facial images. Furthermore, we propose to use the GAK for RVLBP and deep CNN features, respectively for explicitly measuring the similarity of two group-level images. Specifically, we exploit the global weight sort scheme to sort the face images from group-level image according to their spatial weights, making an efficient data structure to GAK. Lastly, we propose Multiple kernel learning based on three combination strategies for combining two respective GAKs based on RVLBP and deep CNN features, such that enhancing the discriminative ability of each GAK. Intensive experiments are performed on the challenging group-level happiness intensity database, namely HAPPEI. Our experimental results demonstrate that the proposed approach achieves promising performance for group happiness intensity analysis, when compared with the recent state-of-the-art methods.