 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSGaze: Context-aware Social Gaze Prediction
Nov 14, 2025A person's gaze offers valuable insights into their focus of attention, level of social engagement, and confidence. In this work, we investigate how contextual cues combined with visual scene and facial information can be effectively utilized to predict and interpret social gaze patterns during conversational interactions. We introduce CSGaze, a context aware multimodal approach that leverages facial, scene information as complementary inputs to enhance social gaze pattern prediction from multi-person images. The model also incorporates a fine-grained attention mechanism centered on the principal speaker, which helps in better modeling social gaze dynamics. Experimental results show that CSGaze performs competitively with state-of-the-art methods on GP-Static, UCO-LAEO and AVA-LAEO. Our findings highlight the role of contextual cues in improving social gaze prediction. Additionally, we provide initial explainability through generated attention scores, offering insights into the model's decision-making process. We also demonstrate our model's generalizability by testing our model on open set datasets that demonstrating its robustness across diverse scenarios.
Gems: Group Emotion Profiling Through Multimodal Situational Understanding
Jul 30, 2025Understanding individual, group and event level emotions along with contextual information is crucial for analyzing a multi-person social situation. To achieve this, we frame emotion comprehension as the task of predicting fine-grained individual emotion to coarse grained group and event level emotion. We introduce GEMS that leverages a multimodal swin-transformer and S3Attention based architecture, which processes an input scene, group members, and context information to generate joint predictions. Existing multi-person emotion related benchmarks mainly focus on atomic interactions primarily based on emotion perception over time and group level. To this end, we extend and propose VGAF-GEMS to provide more fine grained and holistic analysis on top of existing group level annotation of VGAF dataset. GEMS aims to predict basic discrete and continuous emotions (including valence and arousal) as well as individual, group and event level perceived emotions. Our benchmarking effort links individual, group and situational emotional responses holistically. The quantitative and qualitative comparisons with adapted state-of-the-art models demonstrate the effectiveness of GEMS framework on VGAF-GEMS benchmarking. We believe that it will pave the way of further research. The code and data is available at: https://github.com/katariaak579/GEMS
MIP-GAF: A MLLM-annotated Benchmark for Most Important Person Localization and Group Context Understanding
Sep 10, 2024Estimating the Most Important Person (MIP) in any social event setup is a challenging problem mainly due to contextual complexity and scarcity of labeled data. Moreover, the causality aspects of MIP estimation are quite subjective and diverse. To this end, we aim to address the problem by annotating a large-scale `in-the-wild' dataset for identifying human perceptions about the `Most Important Person (MIP)' in an image. The paper provides a thorough description of our proposed Multimodal Large Language Model (MLLM) based data annotation strategy, and a thorough data quality analysis. Further, we perform a comprehensive benchmarking of the proposed dataset utilizing state-of-the-art MIP localization methods, indicating a significant drop in performance compared to existing datasets. The performance drop shows that the existing MIP localization algorithms must be more robust with respect to `in-the-wild' situations. We believe the proposed dataset will play a vital role in building the next-generation social situation understanding methods. The code and data is available at https://github.com/surbhimadan92/MIP-GAF.
MAGIC-TBR: Multiview Attention Fusion for Transformer-based Bodily Behavior Recognition in Group Settings
Sep 19, 2023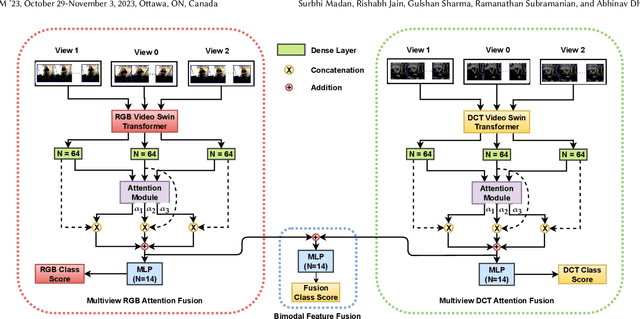



Bodily behavioral language is an important social cue, and its automated analysis helps in enhancing the understanding of artificial intelligence systems. Furthermore, behavioral language cues are essential for active engagement in social agent-based user interactions. Despite the progress made in computer vision for tasks like head and body pose estimation, there is still a need to explore the detection of finer behaviors such as gesturing, grooming, or fumbling. This paper proposes a multiview attention fusion method named MAGIC-TBR that combines features extracted from videos and their corresponding Discrete Cosine Transform coefficients via a transformer-based approach. The experiments are conducted on the BBSI dataset and the results demonstrate the effectiveness of the proposed feature fusion with multiview attention. The code is available at: https://github.com/surbhimadan92/MAGIC-TBR
Explainable Human-centered Traits from Head Motion and Facial Expression Dynamics
Feb 23, 2023



We explore the efficacy of multimodal behavioral cues for explainable prediction of personality and interview-specific traits. We utilize elementary head-motion units named kinemes, atomic facial movements termed action units and speech features to estimate these human-centered traits. Empirical results confirm that kinemes and action units enable discovery of multiple trait-specific behaviors while also enabling explainability in support of the predictions. For fusing cues, we explore decision and feature-level fusion, and an additive attention-based fusion strategy which quantifies the relative importance of the three modalities for trait prediction. Examining various long-short term memory (LSTM) architectures for classification and regression on the MIT Interview and First Impressions Candidate Screening (FICS) datasets, we note that: (1) Multimodal approaches outperform unimodal counterparts; (2) Efficient trait predictions and plausible explanations are achieved with both unimodal and multimodal approaches, and (3) Following the thin-slice approach, effective trait prediction is achieved even from two-second behavioral snippets.
Head Matters: Explainable Human-centered Trait Prediction from Head Motion Dynamics
Dec 15, 2021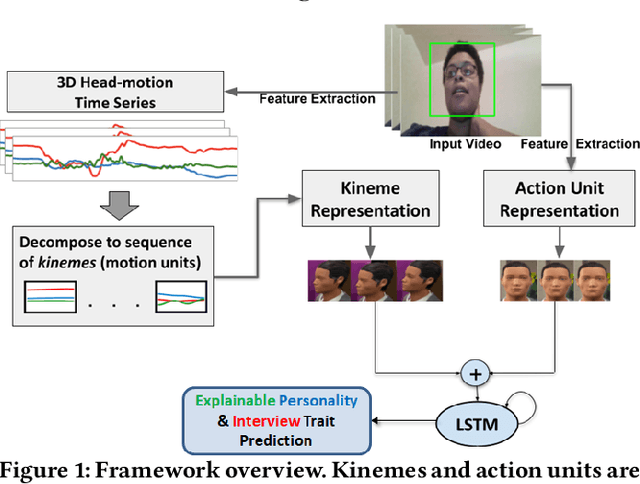
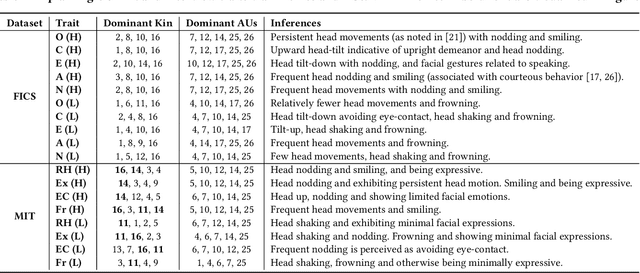

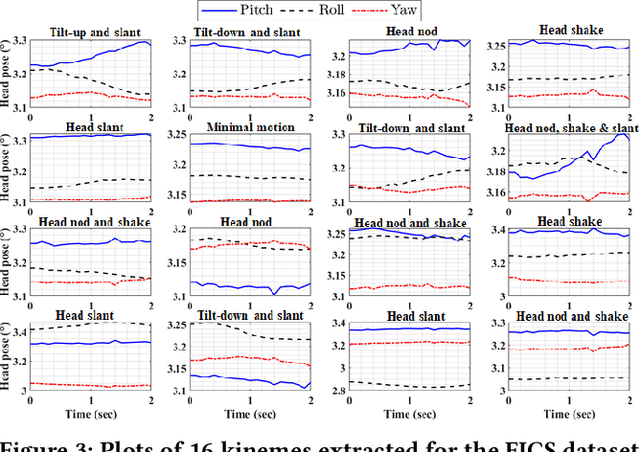
We demonstrate the utility of elementary head-motion units termed kinemes for behavioral analytics to predict personality and interview traits. Transforming head-motion patterns into a sequence of kinemes facilitates discovery of latent temporal signatures characterizing the targeted traits, thereby enabling both efficient and explainable trait prediction. Utilizing Kinemes and Facial Action Coding System (FACS) features to predict (a) OCEAN personality traits on the First Impressions Candidate Screening videos, and (b) Interview traits on the MIT dataset, we note that: (1) A Long-Short Term Memory (LSTM) network trained with kineme sequences performs better than or similar to a Convolutional Neural Network (CNN) trained with facial images; (2) Accurate predictions and explanations are achieved on combining FACS action units (AUs) with kinemes, and (3) Prediction performance is affected by the time-length over which head and facial movements are observed.