 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGIC-TBR: Multiview Attention Fusion for Transformer-based Bodily Behavior Recognition in Group Settings
Sep 19, 2023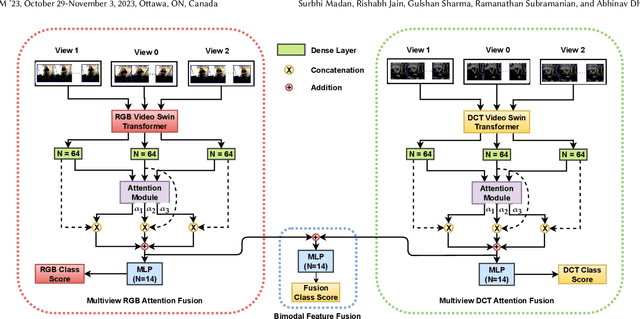



Bodily behavioral language is an important social cue, and its automated analysis helps in enhancing the understanding of artificial intelligence systems. Furthermore, behavioral language cues are essential for active engagement in social agent-based user interactions. Despite the progress made in computer vision for tasks like head and body pose estimation, there is still a need to explore the detection of finer behaviors such as gesturing, grooming, or fumbling. This paper proposes a multiview attention fusion method named MAGIC-TBR that combines features extracted from videos and their corresponding Discrete Cosine Transform coefficients via a transformer-based approach. The experiments are conducted on the BBSI dataset and the results demonstrate the effectiveness of the proposed feature fusion with multiview attention. The code is available at: https://github.com/surbhimadan92/MAGIC-TBR
Modelling Errors in X-ray Fluoroscopic Imaging Systems Using Photogrammetric Bundle Adjustment With a Data-Driven Self-Calibration Approach
Oct 19, 2018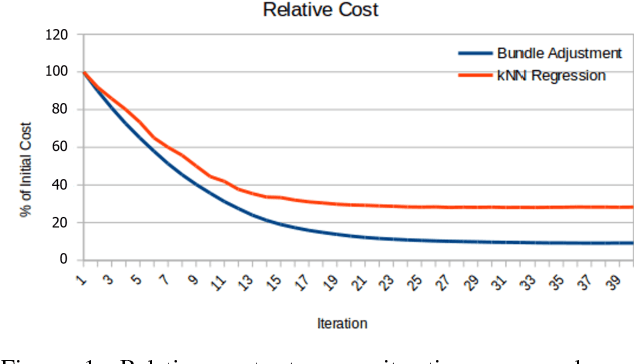
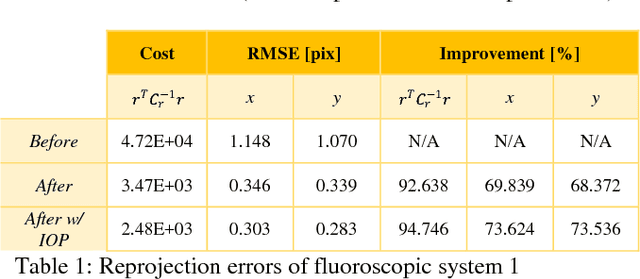

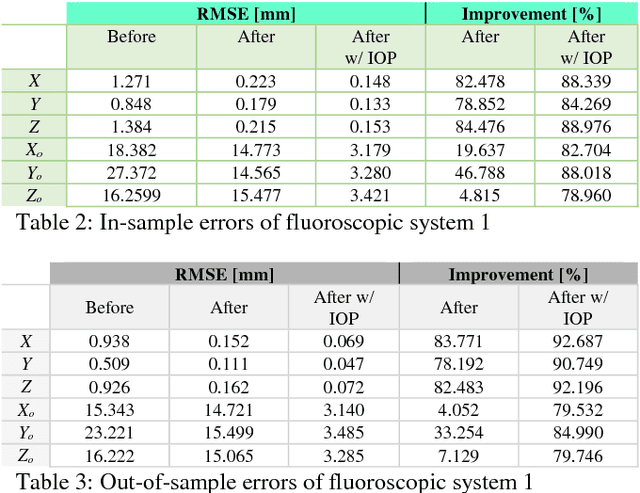
X-ray imaging is a fundamental tool of routine clinical diagnosis. Fluoroscopic imaging can further acquire X-ray images at video frame rates, thus enabling non-invasive in-vivo motion studies of joints, gastrointestinal tract, etc. For both the qualitative and quantitative analysis of static and dynamic X-ray images, the data should be free of systematic biases. Besides precise fabrication of hardware, software-based calibration solutions are commonly used for modelling the distortions. In this primary research study, a robust photogrammetric bundle adjustment was used to model the projective geometry of two fluoroscopic X-ray imaging systems. However, instead of relying on an expert photogrammetrist's knowledge and judgement to decide on a parametric model for describing the systematic errors, a self-tuning data-driven approach is used to model the complex non-linear distortion profile of the sensors. Quality control from the experiment showed that 0.06 mm to 0.09 mm 3D reconstruction accuracy was achievable post-calibration using merely 15 X-ray images. As part of the bundle adjustment, the location of the virtual fluoroscopic system relative to the target field can also be spatially resected with an RMSE between 3.10 mm and 3.31 mm.
* ISPRS TC I Mid-term Symposium "Innovative Sensing - From Sensors to Methods and Applications", 10-12 October 2018. Karlsruhe, Germany