 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSGaze: Context-aware Social Gaze Prediction
Nov 14, 2025A person's gaze offers valuable insights into their focus of attention, level of social engagement, and confidence. In this work, we investigate how contextual cues combined with visual scene and facial information can be effectively utilized to predict and interpret social gaze patterns during conversational interactions. We introduce CSGaze, a context aware multimodal approach that leverages facial, scene information as complementary inputs to enhance social gaze pattern prediction from multi-person images. The model also incorporates a fine-grained attention mechanism centered on the principal speaker, which helps in better modeling social gaze dynamics. Experimental results show that CSGaze performs competitively with state-of-the-art methods on GP-Static, UCO-LAEO and AVA-LAEO. Our findings highlight the role of contextual cues in improving social gaze prediction. Additionally, we provide initial explainability through generated attention scores, offering insights into the model's decision-making process. We also demonstrate our model's generalizability by testing our model on open set datasets that demonstrating its robustness across diverse scenarios.
On the Validity of Head Motion Patterns as Generalisable Depression Biomarkers
May 29, 2025Depression is a debilitating mood disorder negatively impacting millions worldwide. While researchers have explored multiple verbal and non-verbal behavioural cues for automated depression assessment, head motion has received little attention thus far. Further, the common practice of validating machine learning models via a single dataset can limit model generalisability. This work examines the effectiveness and generalisability of models utilising elementary head motion units, termed kinemes, for depression severity estimation. Specifically, we consider three depression datasets from different western cultures (German: AVEC2013, Australian: Blackdog and American: Pitt datasets) with varied contextual and recording settings to investigate the generalisability of the derived kineme patterns via two methods: (i) k-fold cross-validation over individual/multiple datasets, and (ii) model reuse on other datasets. Evaluating classification and regression performance with classical machine learning methods, our results show that: (1) head motion patterns are efficient biomarkers for estimating depression severity, achieving highly competitive performance for both classification and regression tasks on a variety of datasets, including achieving the second best Mean Absolute Error (MAE) on the AVEC2013 dataset, and (2) kineme-based features are more generalisable than (a) raw head motion descriptors for binary severity classification, and (b) other visual behavioural cues for severity estimation (regression).
EditIQ: Automated Cinematic Editing of Static Wide-Angle Videos via Dialogue Interpretation and Saliency Cues
Feb 04, 2025We present EditIQ, a completely automated framework for cinematically editing scenes captured via a stationary, large field-of-view and high-resolution camera. From the static camera feed, EditIQ initially generates multiple virtual feeds, emulating a team of cameramen. These virtual camera shots termed rushes are subsequently assembled using an automated editing algorithm, whose objective is to present the viewer with the most vivid scene content. To understand key scene elements and guide the editing process, we employ a two-pronged approach: (1) a large language model (LLM)-based dialogue understanding module to analyze conversational flow, coupled with (2) visual saliency prediction to identify meaningful scene elements and camera shots therefrom. We then formulate cinematic video editing as an energy minimization problem over shot selection, where cinematic constraints determine shot choices, transitions, and continuity. EditIQ synthesizes an aesthetically and visually compelling representation of the original narrative while maintaining cinematic coherence and a smooth viewing experience. Efficacy of EditIQ against competing baselines is demonstrated via a psychophysical study involving twenty participants on the BBC Old School dataset plus eleven theatre performance videos. Video samples from EditIQ can be found at https://editiq-ave.github.io/.
MIP-GAF: A MLLM-annotated Benchmark for Most Important Person Localization and Group Context Understanding
Sep 10, 2024Estimating the Most Important Person (MIP) in any social event setup is a challenging problem mainly due to contextual complexity and scarcity of labeled data. Moreover, the causality aspects of MIP estimation are quite subjective and diverse. To this end, we aim to address the problem by annotating a large-scale `in-the-wild' dataset for identifying human perceptions about the `Most Important Person (MIP)' in an image. The paper provides a thorough description of our proposed Multimodal Large Language Model (MLLM) based data annotation strategy, and a thorough data quality analysis. Further, we perform a comprehensive benchmarking of the proposed dataset utilizing state-of-the-art MIP localization methods, indicating a significant drop in performance compared to existing datasets. The performance drop shows that the existing MIP localization algorithms must be more robust with respect to `in-the-wild' situations. We believe the proposed dataset will play a vital role in building the next-generation social situation understanding methods. The code and data is available at https://github.com/surbhimadan92/MIP-GAF.
MAGIC-TBR: Multiview Attention Fusion for Transformer-based Bodily Behavior Recognition in Group Settings
Sep 19, 2023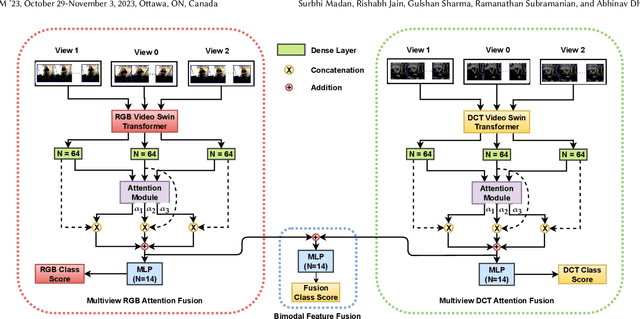



Bodily behavioral language is an important social cue, and its automated analysis helps in enhancing the understanding of artificial intelligence systems. Furthermore, behavioral language cues are essential for active engagement in social agent-based user interactions. Despite the progress made in computer vision for tasks like head and body pose estimation, there is still a need to explore the detection of finer behaviors such as gesturing, grooming, or fumbling. This paper proposes a multiview attention fusion method named MAGIC-TBR that combines features extracted from videos and their corresponding Discrete Cosine Transform coefficients via a transformer-based approach. The experiments are conducted on the BBSI dataset and the results demonstrate the effectiveness of the proposed feature fusion with multiview attention. The code is available at: https://github.com/surbhimadan92/MAGIC-TBR
Efficient Labelling of Affective Video Datasets via Few-Shot & Multi-Task Contrastive Learning
Aug 04, 2023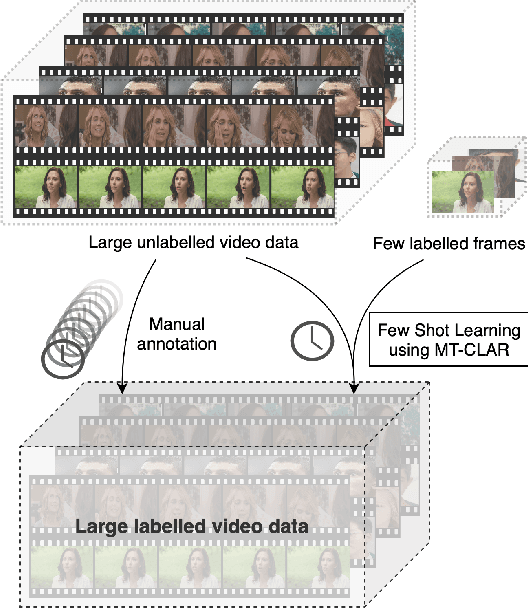
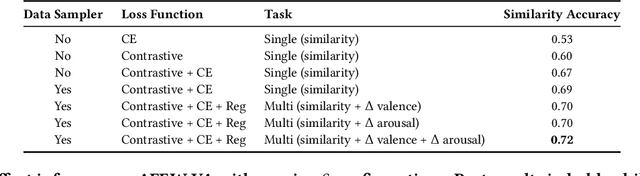
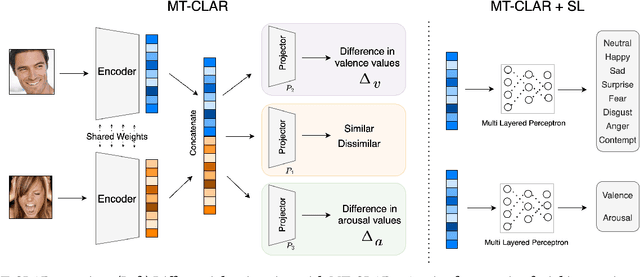
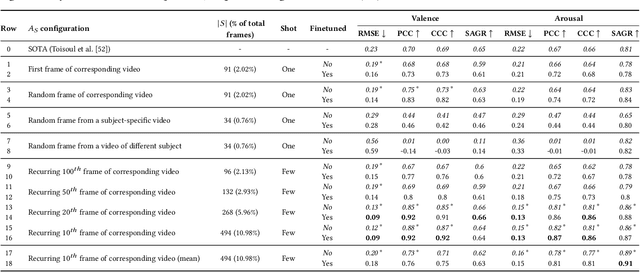
Whilst deep learning techniques have achieved excellent emotion prediction, they still require large amounts of labelled training data, which are (a) onerous and tedious to compile, and (b) prone to errors and biases. We propose Multi-Task Contrastive Learning for Affect Representation (\textbf{MT-CLAR}) for few-shot affect inference. MT-CLAR combines multi-task learning with a Siamese network trained via contrastive learning to infer from a pair of expressive facial images (a) the (dis)similarity between the facial expressions, and (b) the difference in valence and arousal levels of the two faces. We further extend the image-based MT-CLAR framework for automated video labelling where, given one or a few labelled video frames (termed \textit{support-set}), MT-CLAR labels the remainder of the video for valence and arousal. Experiments are performed on the AFEW-VA dataset with multiple support-set configurations; moreover, supervised learning on representations learnt via MT-CLAR are used for valence, arousal and categorical emotion prediction on the AffectNet and AFEW-VA datasets. The results show that valence and arousal predictions via MT-CLAR are very comparable to the state-of-the-art (SOTA), and we significantly outperform SOTA with a support-set $\approx$6\% the size of the video dataset.
Explainable Depression Detection via Head Motion Patterns
Jul 23, 2023



While depression has been studied via multimodal non-verbal behavioural cues, head motion behaviour has not received much attention as a biomarker. This study demonstrates the utility of fundamental head-motion units, termed \emph{kinemes}, for depression detection by adopting two distinct approaches, and employing distinctive features: (a) discovering kinemes from head motion data corresponding to both depressed patients and healthy controls, and (b) learning kineme patterns only from healthy controls, and computing statistics derived from reconstruction errors for both the patient and control classes. Employing machine learning methods, we evaluate depression classification performance on the \emph{BlackDog} and \emph{AVEC2013} datasets. Our findings indicate that: (1) head motion patterns are effective biomarkers for detecting depressive symptoms, and (2) explanatory kineme patterns consistent with prior findings can be observed for the two classes. Overall, we achieve peak F1 scores of 0.79 and 0.82, respectively, over BlackDog and AVEC2013 for binary classification over episodic \emph{thin-slices}, and a peak F1 of 0.72 over videos for AVEC2013.
A Weakly Supervised Approach to Emotion-change Prediction and Improved Mood Inference
Jun 12, 2023Whilst a majority of affective computing research focuses on inferring emotions, examining mood or understanding the \textit{mood-emotion interplay} has received significantly less attention. Building on prior work, we (a) deduce and incorporate emotion-change ($\Delta$) information for inferring mood, without resorting to annotated labels, and (b) attempt mood prediction for long duration video clips, in alignment with the characterisation of mood. We generate the emotion-change ($\Delta$) labels via metric learning from a pre-trained Siamese Network, and use these in addition to mood labels for mood classification. Experiments evaluating \textit{unimodal} (training only using mood labels) vs \textit{multimodal} (training using mood plus $\Delta$ labels) models show that mood prediction benefits from the incorporation of emotion-change information, emphasising the importance of modelling the mood-emotion interplay for effective mood inference.
Explainable Human-centered Traits from Head Motion and Facial Expression Dynamics
Feb 23, 2023



We explore the efficacy of multimodal behavioral cues for explainable prediction of personality and interview-specific traits. We utilize elementary head-motion units named kinemes, atomic facial movements termed action units and speech features to estimate these human-centered traits. Empirical results confirm that kinemes and action units enable discovery of multiple trait-specific behaviors while also enabling explainability in support of the predictions. For fusing cues, we explore decision and feature-level fusion, and an additive attention-based fusion strategy which quantifies the relative importance of the three modalities for trait prediction. Examining various long-short term memory (LSTM) architectures for classification and regression on the MIT Interview and First Impressions Candidate Screening (FICS) datasets, we note that: (1) Multimodal approaches outperform unimodal counterparts; (2) Efficient trait predictions and plausible explanations are achieved with both unimodal and multimodal approaches, and (3) Following the thin-slice approach, effective trait prediction is achieved even from two-second behavioral snippets.
Outlier-based Autism Detection using Longitudinal Structural MRI
Mar 10, 2022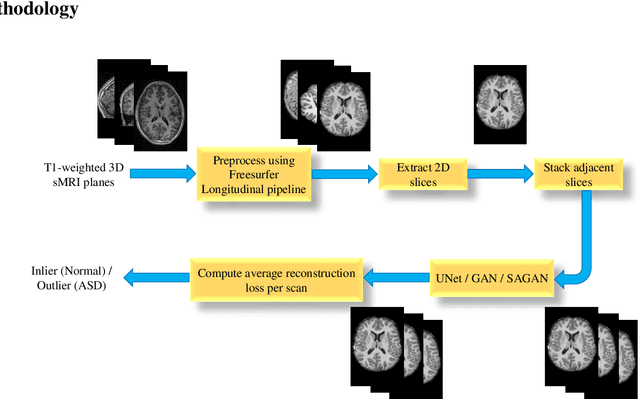
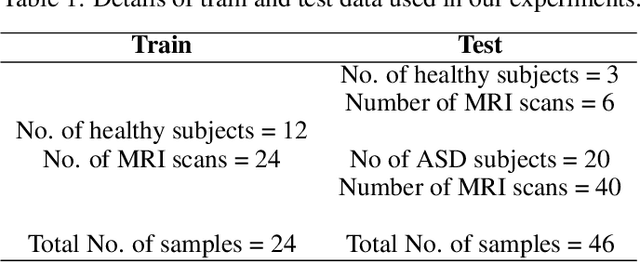
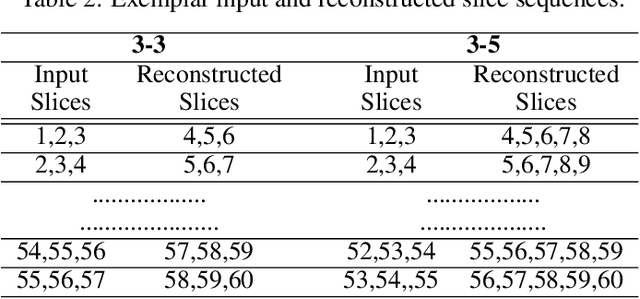
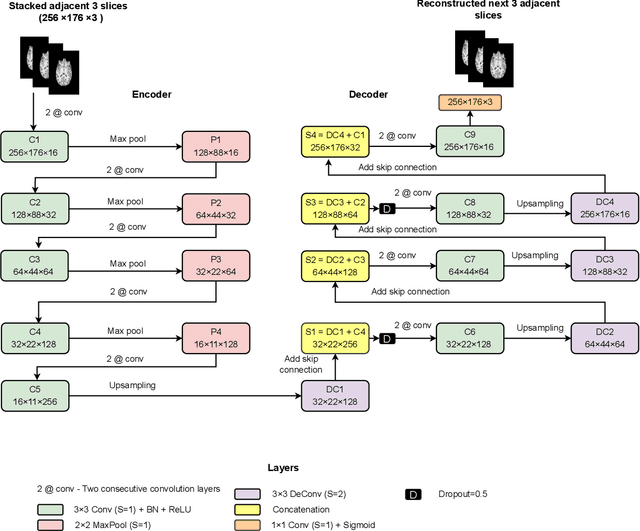
Diagnosis of Autism Spectrum Disorder (ASD) using clinical evaluation (cognitive tests) is challenging due to wide variations amongst individuals. Since no effective treatment exists, prompt and reliable ASD diagnosis can enable the effective preparation of treatment regimens. This paper proposes structural Magnetic Resonance Imaging (sMRI)-based ASD diagnosis via an outlier detection approach. To learn Spatio-temporal patterns in structural brain connectivity, a Generative Adversarial Network (GAN) is trained exclusively with sMRI scans of healthy subjects. Given a stack of three adjacent slices as input, the GAN generator reconstructs the next three adjacent slices; the GAN discriminator then identifies ASD sMRI scan reconstructions as outliers. This model is compared against two other baselines -- a simpler UNet and a sophisticated Self-Attention GAN. Axial, Coronal, and Sagittal sMRI slices from the multi-site ABIDE II dataset are used for evaluation. Extensive experiments reveal that our ASD detection framework performs comparably with the state-of-the-art with far fewer training data. Furthermore, longitudinal data (two scans per subject over time) achieve 17-28% higher accuracy than cross-sectional data (one scan per subject). Among other findings, metrics employed for model training as well as reconstruction loss computation impact detection performance, and the coronal modality is found to best encode structural information for ASD detection.