 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lipreading Gap: Do VSR Models Perceive Visual Speech Like Human Lipreaders?
Jun 05, 2026Visual speech recognition (VSR) models now surpass human lipreaders on benchmarks, but do such gains establish human-like visual speech perception? To explore this, we compare three VSR systems with human baselines on the MaFI word-level lipreading dataset using word, character, phoneme, and viseme-level metrics. Although models achieve higher overall accuracy, they succeed and fail on different words than humans. A text-only n-gram baseline given only a few initial phonemes rivals human lipreading. VSR word-level errors are consistently better explained by training word frequency than by the visual informativeness of words. Viseme accuracies, confusion matrices and human-model correlations further show that models gain most on visemes humans find hardest, and show much weaker dependence on visual clarity. Our work demonstrates that VSR systems rely primarily on language cues from training data rather than visual perception, failing to bind visual features into meaningful words.
VisG AV-HuBERT: Viseme-Guided AV-HuBERT
Apr 01, 2026Audio-Visual Speech Recognition (AVSR) systems nowadays integrate Large Language Model (LLM) decoders with transformer-based encoders, achieving state-of-the-art results. However, the relative contributions of improved language modelling versus enhanced audiovisual encoding remain unclear. We propose Viseme-Guided AV-HuBERT (VisG AV-HuBERT), a multi-task fine-tuning framework that incorporates auxiliary viseme classification to strengthen the model's reliance on visual articulatory features. By extending AV-HuBERT with a lightweight viseme prediction sub-network, this method explicitly guides the encoder to preserve visual speech information. Evaluated on LRS3, VisG AV-HuBERT achieves comparable or improved performance over the baseline AV-HuBERT, with notable gains under heavy noise conditions. WER reduces from 13.59% to 6.60% (51.4% relative improvement) at -10 dB Signal-to-Noise Ratio (SNR) for Speech noise. Deeper analysis reveals substantial reductions in substitution errors across noise types, demonstrating improved speech unit discrimination. Evaluation on LRS2 confirms generalization capability. Our results demonstrate that explicit viseme modelling enhances encoder representations, and provides a foundation for enhancing noise-robust AVSR through encoder-level improvements.
Pairwise is Not Enough: Hypergraph Neural Networks for Multi-Agent Pathfinding
Feb 06, 2026Multi-Agent Path Finding (MAPF) is a representative multi-agent coordination problem, where multiple agents are required to navigate to their respective goals without collisions. Solving MAPF optimally is known to be NP-hard, leading to the adoption of learning-based approaches to alleviate the online computational burden. Prevailing approaches, such as Graph Neural Networks (GNNs), are typically constrained to pairwise message passing between agents. However, this limitation leads to suboptimal behaviours and critical issues, such as attention dilution, particularly in dense environments where group (i.e. beyond just two agents) coordination is most critical. Despite the importance of such higher-order interactions, existing approaches have not been able to fully explore them. To address this representational bottleneck, we introduce HMAGAT (Hypergraph Multi-Agent Attention Network), a novel architecture that leverages attentional mechanisms over directed hypergraphs to explicitly capture group dynamics. Empirically, HMAGAT establishes a new state-of-the-art among learning-based MAPF solvers: e.g., despite having just 1M parameters and being trained on 100$\times$ less data, it outperforms the current SoTA 85M parameter model. Through detailed analysis of HMAGAT's attention values, we demonstrate how hypergraph representations mitigate the attention dilution inherent in GNNs and capture complex interactions where pairwise methods fail. Our results illustrate that appropriate inductive biases are often more critical than the training data size or sheer parameter count for multi-agent problems.
A Super-Learner with Large Language Models for Medical Emergency Advising
Nov 15, 2025Medical decision-support and advising systems are critical for emergency physicians to quickly and accurately assess patients' conditions and make diagnosis. Artificial Intelligence (AI) has emerged as a transformative force in healthcare in recent years and Large Language Models (LLMs) have been employed in various fields of medical decision-support systems. We studied responses of a group of different LLMs to real cases in emergency medicine. The results of our study on five most renown LLMs showed significant differences in capabilities of Large Language Models for diagnostics acute diseases in medical emergencies with accuracy ranging between 58% and 65%. This accuracy significantly exceeds the reported accuracy of human doctors. We built a super-learner MEDAS (Medical Emergency Diagnostic Advising System) of five major LLMs - Gemini, Llama, Grok, GPT, and Claude). The super-learner produces higher diagnostic accuracy, 70%, even with a quite basic meta-learner. However, at least one of the integrated LLMs in the same super-learner produces 85% correct diagnoses. The super-learner integrates a cluster of LLMs using a meta-learner capable of learning different capabilities of each LLM to leverage diagnostic accuracy of the model by collective capabilities of all LLMs in the cluster. The results of our study showed that aggregated diagnostic accuracy provided by a meta-learning approach exceeds that of any individual LLM, suggesting that the super-learner can take advantage of the combined knowledge of the medical datasets used to train the group of LLMs.
Princeton365: A Diverse Dataset with Accurate Camera Pose
Jun 10, 2025We introduce Princeton365, a large-scale diverse dataset of 365 videos with accurate camera pose. Our dataset bridges the gap between accuracy and data diversity in current SLAM benchmarks by introducing a novel ground truth collection framework that leverages calibration boards and a 360-camera. We collect indoor, outdoor, and object scanning videos with synchronized monocular and stereo RGB video outputs as well as IMU. We further propose a new scene scale-aware evaluation metric for SLAM based on the the optical flow induced by the camera pose estimation error. In contrast to the current metrics, our new metric allows for comparison between the performance of SLAM methods across scenes as opposed to existing metrics such as Average Trajectory Error (ATE), allowing researchers to analyze the failure modes of their methods. We also propose a challenging Novel View Synthesis benchmark that covers cases not covered by current NVS benchmarks, such as fully non-Lambertian scenes with 360-degree camera trajectories. Please visit https://princeton365.cs.princeton.edu for the dataset, code, videos, and submission.
EOPose : Exemplar-based object reposing using Generalized Pose Correspondences
May 06, 2025



Reposing objects in images has a myriad of applications, especially for e-commerce where several variants of product images need to be produced quickly. In this work, we leverage the recent advances in unsupervised keypoint correspondence detection between different object images of the same class to propose an end-to-end framework for generic object reposing. Our method, EOPose, takes a target pose-guidance image as input and uses its keypoint correspondence with the source object image to warp and re-render the latter into the target pose using a novel three-step approach. Unlike generative approaches, our method also preserves the fine-grained details of the object such as its exact colors, textures, and brand marks. We also prepare a new dataset of paired objects based on the Objaverse dataset to train and test our network. EOPose produces high-quality reposing output as evidenced by different image quality metrics (PSNR, SSIM and FID). Besides a description of the method and the dataset, the paper also includes detailed ablation and user studies to indicate the efficacy of the proposed method
Pushing the Performance Envelope of DNN-based Recommendation Systems Inference on GPUs
Oct 29, 2024

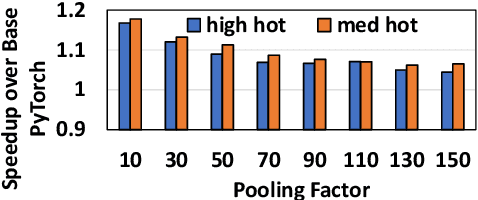

Personalized recommendation is a ubiquitous application on the internet, with many industries and hyperscalers extensively leveraging Deep Learning Recommendation Models (DLRMs) for their personalization needs (like ad serving or movie suggestions). With growing model and dataset sizes pushing computation and memory requirements, GPUs are being increasingly preferred for executing DLRM inference. However, serving newer DLRMs, while meeting acceptable latencies, continues to remain challenging, making traditional deployments increasingly more GPU-hungry, resulting in higher inference serving costs. In this paper, we show that the embedding stage continues to be the primary bottleneck in the GPU inference pipeline, leading up to a 3.2x embedding-only performance slowdown. To thoroughly grasp the problem, we conduct a detailed microarchitecture characterization and highlight the presence of low occupancy in the standard embedding kernels. By leveraging direct compiler optimizations, we achieve optimal occupancy, pushing the performance by up to 53%. Yet, long memory latency stalls continue to exist. To tackle this challenge, we propose specialized plug-and-play-based software prefetching and L2 pinning techniques, which help in hiding and decreasing the latencies. Further, we propose combining them, as they complement each other. Experimental evaluations using A100 GPUs with large models and datasets show that our proposed techniques improve performance by up to 103% for the embedding stage, and up to 77% for the overall DLRM inference pipeline.
A Perspective on Foundation Models for the Electric Power Grid
Jul 12, 2024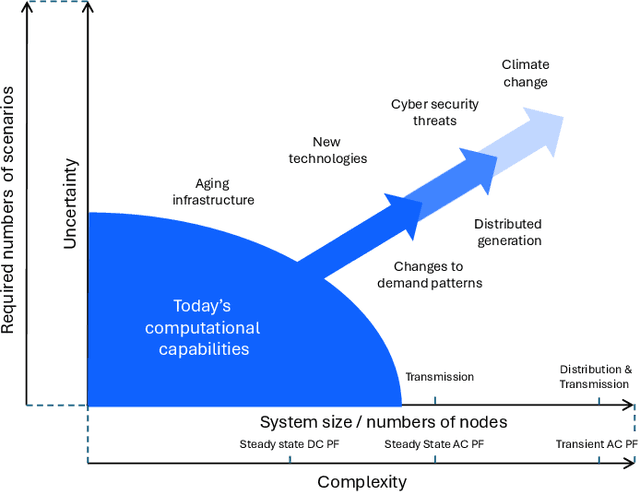
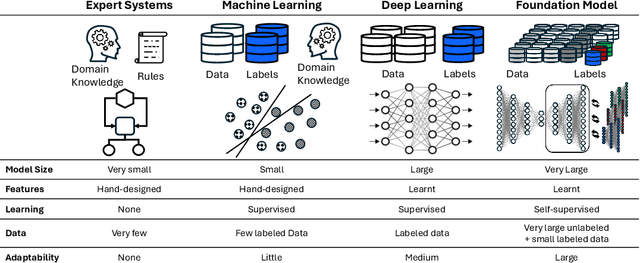
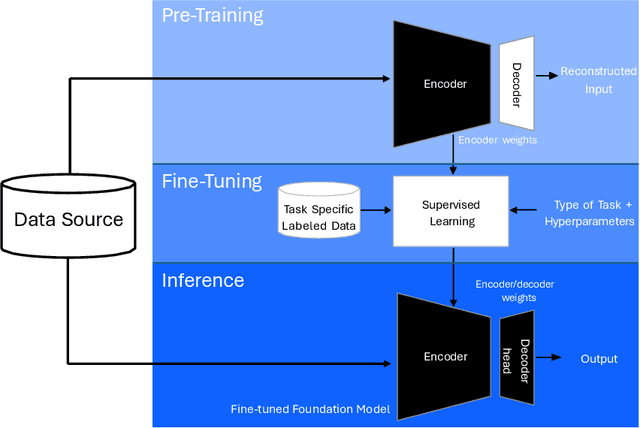
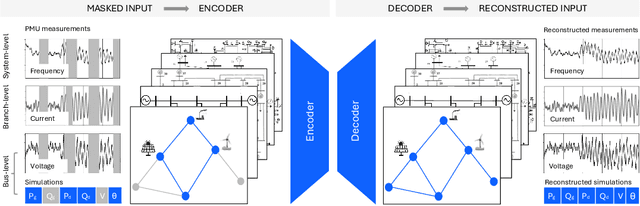
Foundation models (FMs) currently dominate news headlines. They employ advanced deep learning architectures to extract structural information autonomously from vast datasets through self-supervision. The resulting rich representations of complex systems and dynamics can be applied to many downstream applications. Therefore, FMs can find uses in electric power grids, challenged by the energy transition and climate change. In this paper, we call for the development of, and state why we believe in, the potential of FMs for electric grids. We highlight their strengths and weaknesses amidst the challenges of a changing grid. We argue that an FM learning from diverse grid data and topologies could unlock transformative capabilities, pioneering a new approach in leveraging AI to redefine how we manage complexity and uncertainty in the electric grid. Finally, we discuss a power grid FM concept, namely GridFM, based on graph neural networks and show how different downstream tasks benefit.
Shotluck Holmes: A Family of Efficient Small-Scale Large Language Vision Models For Video Captioning and Summarization
May 31, 2024Video is an increasingly prominent and information-dense medium, yet it poses substantial challenges for language models. A typical video consists of a sequence of shorter segments, or shots, that collectively form a coherent narrative. Each shot is analogous to a word in a sentence where multiple data streams of information (such as visual and auditory data) must be processed simultaneously. Comprehension of the entire video requires not only understanding the visual-audio information of each shot but also requires that the model links the ideas between each shot to generate a larger, all-encompassing story. Despite significant progress in the field, current works often overlook videos' more granular shot-by-shot semantic information. In this project, we propose a family of efficient large language vision models (LLVMs) to boost video summarization and captioning called Shotluck Holmes. By leveraging better pretraining and data collection strategies, we extend the abilities of existing small LLVMs from being able to understand a picture to being able to understand a sequence of frames. Specifically, we show that Shotluck Holmes achieves better performance than state-of-the-art results on the Shot2Story video captioning and summary task with significantly smaller and more computationally efficient models.
Data Center Audio/Video Intelligence on Device (DAVID) -- An Edge-AI Platform for Smart-Toys
Nov 18, 2023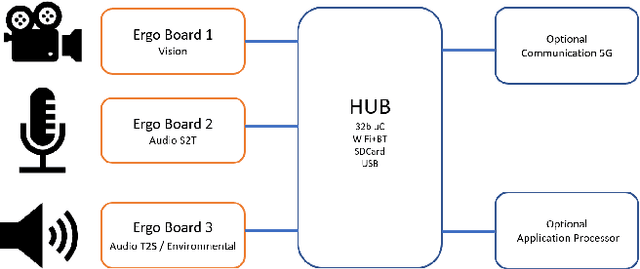
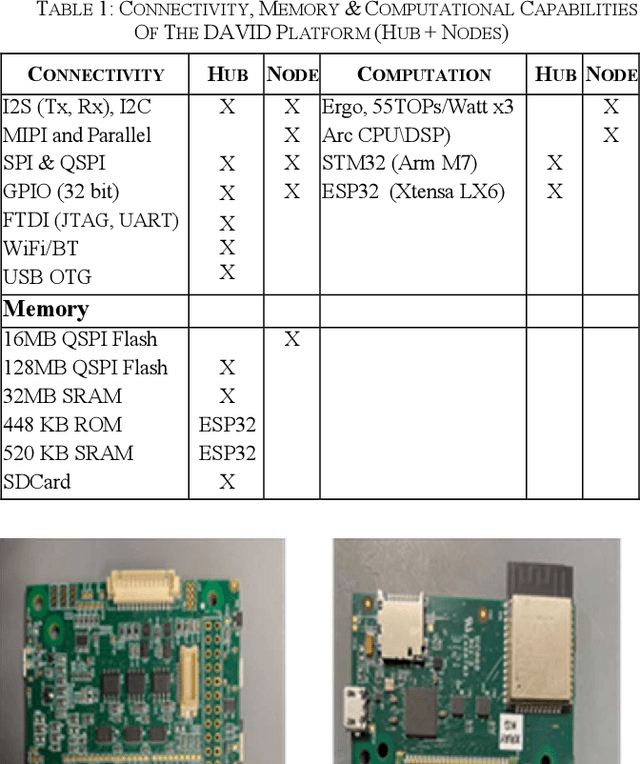

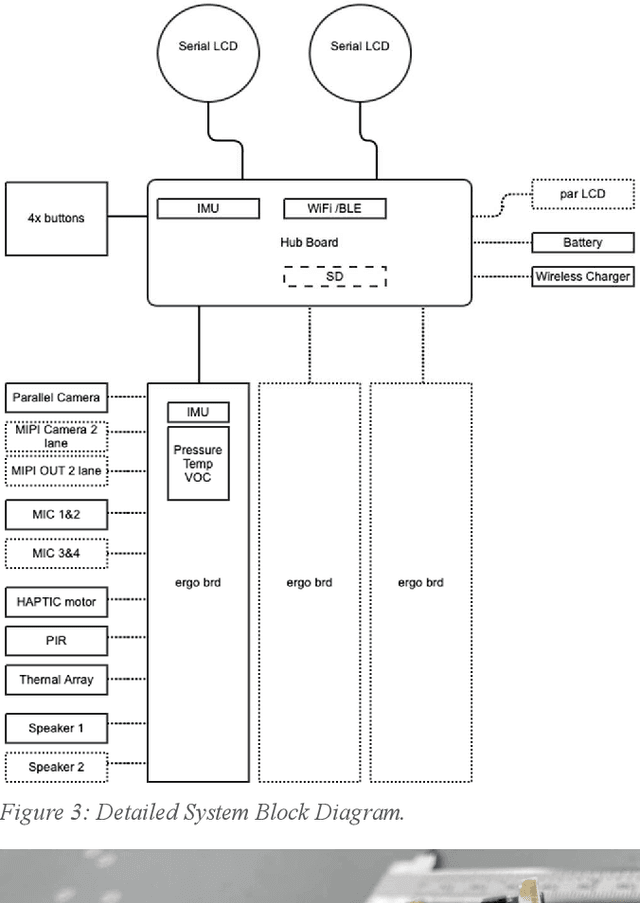
An overview is given of the DAVID Smart-Toy platform, one of the first Edge AI platform designs to incorporate advanced low-power data processing by neural inference models co-located with the relevant image or audio sensors. There is also on-board capability for in-device text-to-speech generation. Two alternative embodiments are presented: a smart Teddy-bear, and a roving dog-like robot. The platform offers a speech-driven user interface and can observe and interpret user actions and facial expressions via its computer vision sensor node. A particular benefit of this design is that no personally identifiable information passes beyond the neural inference nodes thus providing inbuilt compliance with data protection regulations.