 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Review to Design: Ethical Multimodal Driver Monitoring Systems for Risk Mitigation, Incident Response, and Accountability in Automated Vehicles
May 07, 2026As vehicles transition toward higher levels of automation, Driver Monitoring Systems (DMS) have become essential for ensuring human oversight, safety, and regulatory compliance in a vehicle. These systems rely on multimodal sensing and AI-driven inference to assess driver attention, cognitive state, and readiness to take control. While technologically promising, their deployment introduces a complex set of ethical and legal challenges - ranging from privacy and consent to data ownership and algorithmic fairness. While overarching frameworks such as the GDPR, EU AI Act, and IEEE standards offer important guidance, they lack the specificity required for addressing the unique risks posed by in-cabin sensing technologies. This paper adopts a review-to-design perspective, critically examining existing regulatory instruments and ethical frameworks -- such as the GDPR, the EU AI Act, and IEEE guidelines -- and identifying gaps in their applicability to the distinctive risks posed by multimodal, AI-enabled in-cabin monitoring. Building on this review, we propose a modular ethical design framework tailored specifically to Driver Monitoring Systems. The framework translates high-level principles into actionable design and deployment guidance, including user-configurable consent mechanisms, fairness-aware model development, transparency and explainability tools, and safeguards for driver emotional well-being. Finally, the paper outlines a risk analysis and failure mitigation strategy, emphasizing proactive incident response and accountability mechanisms tailored to the DMS context. Together, these contributions aim to inform the development of transparent, trustworthy, and human-centered driver monitoring systems for next-generation autonomous vehicles.
ChildDiffusion: Unlocking the Potential of Generative AI and Controllable Augmentations for Child Facial Data using Stable Diffusion and Large Language Models
Jun 17, 2024
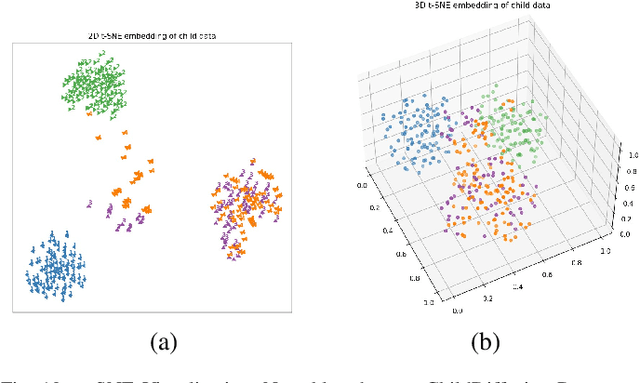


In this research work we have proposed high-level ChildDiffusion framework capable of generating photorealistic child facial samples and further embedding several intelligent augmentations on child facial data using short text prompts, detailed textual guidance from LLMs, and further image to image transformation using text guidance control conditioning thus providing an opportunity to curate fully synthetic large scale child datasets. The framework is validated by rendering high-quality child faces representing ethnicity data, micro expressions, face pose variations, eye blinking effects, facial accessories, different hair colours and styles, aging, multiple and different child gender subjects in a single frame. Addressing privacy concerns regarding child data acquisition requires a comprehensive approach that involves legal, ethical, and technological considerations. Keeping this in view this framework can be adapted to synthesise child facial data which can be effectively used for numerous downstream machine learning tasks. The proposed method circumvents common issues encountered in generative AI tools, such as temporal inconsistency and limited control over the rendered outputs. As an exemplary use case we have open-sourced child ethnicity data consisting of 2.5k child facial samples of five different classes which includes African, Asian, White, South Asian/ Indian, and Hispanic races by deploying the model in production inference phase. The rendered data undergoes rigorous qualitative as well as quantitative tests to cross validate its efficacy and further fine-tuning Yolo architecture for detecting and classifying child ethnicity as an exemplary downstream machine learning task.
Synthetic Face Ageing: Evaluation, Analysis and Facilitation of Age-Robust Facial Recognition Algorithms
Jun 10, 2024



The ability to accurately recognize an individual's face with respect to human aging factor holds significant importance for various private as well as government sectors such as customs and public security bureaus, passport office, and national database systems. Therefore, developing a robust age-invariant face recognition system is of crucial importance to address the challenges posed by ageing and maintain the reliability and accuracy of facial recognition technology. In this research work, the focus is to explore the feasibility of utilizing synthetic ageing data to improve the robustness of face recognition models that can eventually help in recognizing people at broader age intervals. To achieve this, we first design set of experiments to evaluate state-of-the-art synthetic ageing methods. In the next stage we explore the effect of age intervals on a current deep learning-based face recognition algorithm by using synthetic ageing data as well as real ageing data to perform rigorous training and validation. Moreover, these synthetic age data have been used in facilitating face recognition algorithms. Experimental results show that the recognition rate of the model trained on synthetic ageing images is 3.33% higher than the results of the baseline model when tested on images with an age gap of 40 years, which prove the potential of synthetic age data which has been quantified to enhance the performance of age-invariant face recognition systems.
Synthesizing CTA Image Data for Type-B Aortic Dissection using Stable Diffusion Models
Feb 10, 2024Stable Diffusion (SD) has gained a lot of attention in recent years in the field of Generative AI thus helping in synthesizing medical imaging data with distinct features. The aim is to contribute to the ongoing effort focused on overcoming the limitations of data scarcity and improving the capabilities of ML algorithms for cardiovascular image processing. Therefore, in this study, the possibility of generating synthetic cardiac CTA images was explored by fine-tuning stable diffusion models based on user defined text prompts, using only limited number of CTA images as input. A comprehensive evaluation of the synthetic data was conducted by incorporating both quantitative analysis and qualitative assessment, where a clinician assessed the quality of the generated data. It has been shown that Cardiac CTA images can be successfully generated using using Text to Image (T2I) stable diffusion model. The results demonstrate that the tuned T2I CTA diffusion model was able to generate images with features that are typically unique to acute type B aortic dissection (TBAD) medical conditions.
Derm-T2IM: Harnessing Synthetic Skin Lesion Data via Stable Diffusion Models for Enhanced Skin Disease Classification using ViT and CNN
Jan 10, 2024

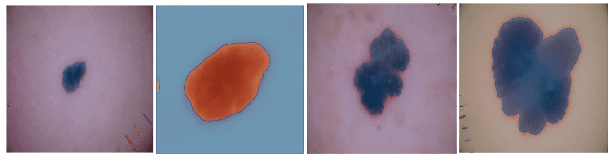

This study explores the utilization of Dermatoscopic synthetic data generated through stable diffusion models as a strategy for enhancing the robustness of machine learning model training. Synthetic data generation plays a pivotal role in mitigating challenges associated with limited labeled datasets, thereby facilitating more effective model training. In this context, we aim to incorporate enhanced data transformation techniques by extending the recent success of few-shot learning and a small amount of data representation in text-to-image latent diffusion models. The optimally tuned model is further used for rendering high-quality skin lesion synthetic data with diverse and realistic characteristics, providing a valuable supplement and diversity to the existing training data. We investigate the impact of incorporating newly generated synthetic data into the training pipeline of state-of-art machine learning models, assessing its effectiveness in enhancing model performance and generalization to unseen real-world data. Our experimental results demonstrate the efficacy of the synthetic data generated through stable diffusion models helps in improving the robustness and adaptability of end-to-end CNN and vision transformer models on two different real-world skin lesion datasets.
Synthetic Speaking Children -- Why We Need Them and How to Make Them
Nov 08, 2023



Contemporary Human Computer Interaction (HCI) research relies primarily on neural network models for machine vision and speech understanding of a system user. Such models require extensively annotated training datasets for optimal performance and when building interfaces for users from a vulnerable population such as young children, GDPR introduces significant complexities in data collection, management, and processing. Motivated by the training needs of an Edge AI smart toy platform this research explores the latest advances in generative neural technologies and provides a working proof of concept of a controllable data generation pipeline for speech driven facial training data at scale. In this context, we demonstrate how StyleGAN2 can be finetuned to create a gender balanced dataset of children's faces. This dataset includes a variety of controllable factors such as facial expressions, age variations, facial poses, and even speech-driven animations with realistic lip synchronization. By combining generative text to speech models for child voice synthesis and a 3D landmark based talking heads pipeline, we can generate highly realistic, entirely synthetic, talking child video clips. These video clips can provide valuable, and controllable, synthetic training data for neural network models, bridging the gap when real data is scarce or restricted due to privacy regulations.
Will your Doorbell Camera still recognize you as you grow old
Aug 08, 2023



Robust authentication for low-power consumer devices such as doorbell cameras poses a valuable and unique challenge. This work explores the effect of age and aging on the performance of facial authentication methods. Two public age datasets, AgeDB and Morph-II have been used as baselines in this work. A photo-realistic age transformation method has been employed to augment a set of high-quality facial images with various age effects. Then the effect of these synthetic aging data on the high-performance deep-learning-based face recognition model is quantified by using various metrics including Receiver Operating Characteristic (ROC) curves and match score distributions. Experimental results demonstrate that long-term age effects are still a significant challenge for the state-of-the-art facial authentication method.
A Comparative Study of Image-to-Image Translation Using GANs for Synthetic Child Race Data
Aug 08, 2023The lack of ethnic diversity in data has been a limiting factor of face recognition techniques in the literature. This is particularly the case for children where data samples are scarce and presents a challenge when seeking to adapt machine vision algorithms that are trained on adult data to work on children. This work proposes the utilization of image-to-image transformation to synthesize data of different races and thus adjust the ethnicity of children's face data. We consider ethnicity as a style and compare three different Image-to-Image neural network based methods, specifically pix2pix, CycleGAN, and CUT networks to implement Caucasian child data and Asian child data conversion. Experimental validation results on synthetic data demonstrate the feasibility of using image-to-image transformation methods to generate various synthetic child data samples with broader ethnic diversity.
Decisive Data using Multi-Modality Optical Sensors for Advanced Vehicular Systems
Jul 25, 2023



Optical sensors have played a pivotal role in acquiring real world data for critical applications. This data, when integrated with advanced machine learning algorithms provides meaningful information thus enhancing human vision. This paper focuses on various optical technologies for design and development of state-of-the-art out-cabin forward vision systems and in-cabin driver monitoring systems. The focused optical sensors include Longwave Thermal Imaging (LWIR) cameras, Near Infrared (NIR), Neuromorphic/ event cameras, Visible CMOS cameras and Depth cameras. Further the paper discusses different potential applications which can be employed using the unique strengths of each these optical modalities in real time environment.
ChildGAN: Large Scale Synthetic Child Facial Data Using Domain Adaptation in StyleGAN
Jul 25, 2023In this research work, we proposed a novel ChildGAN, a pair of GAN networks for generating synthetic boys and girls facial data derived from StyleGAN2. ChildGAN is built by performing smooth domain transfer using transfer learning. It provides photo-realistic, high-quality data samples. A large-scale dataset is rendered with a variety of smart facial transformations: facial expressions, age progression, eye blink effects, head pose, skin and hair color variations, and variable lighting conditions. The dataset comprises more than 300k distinct data samples. Further, the uniqueness and characteristics of the rendered facial features are validated by running different computer vision application tests which include CNN-based child gender classifier, face localization and facial landmarks detection test, identity similarity evaluation using ArcFace, and lastly running eye detection and eye aspect ratio tests. The results demonstrate that synthetic child facial data of high quality offers an alternative to the cost and complexity of collecting a large-scale dataset from real children.