 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration-Guided Continual Reinforcement Learning in Dynamic Environments
Dec 21, 2025Reinforcement learning (RL) excels in various applications but struggles in dynamic environments where the underlying Markov decision process evolves. Continual reinforcement learning (CRL) enables RL agents to continually learn and adapt to new tasks, but balancing stability (preserving prior knowledge) and plasticity (acquiring new knowledge) remains challenging. Existing methods primarily address the stability-plasticity dilemma through mechanisms where past knowledge influences optimization but rarely affects the agent's behavior directly, which may hinder effective knowledge reuse and efficient learning. In contrast, we propose demonstration-guided continual reinforcement learning (DGCRL), which stores prior knowledge in an external, self-evolving demonstration repository that directly guides RL exploration and adaptation. For each task, the agent dynamically selects the most relevant demonstration and follows a curriculum-based strategy to accelerate learning, gradually shifting from demonstration-guided exploration to fully self-exploration. Extensive experiments on 2D navigation and MuJoCo locomotion tasks demonstrate its superior average performance, enhanced knowledge transfer, mitigation of forgetting, and training efficiency. The additional sensitivity analysis and ablation study further validate its effectiveness.
Derm-T2IM: Harnessing Synthetic Skin Lesion Data via Stable Diffusion Models for Enhanced Skin Disease Classification using ViT and CNN
Jan 10, 2024

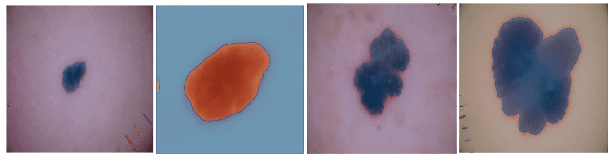

This study explores the utilization of Dermatoscopic synthetic data generated through stable diffusion models as a strategy for enhancing the robustness of machine learning model training. Synthetic data generation plays a pivotal role in mitigating challenges associated with limited labeled datasets, thereby facilitating more effective model training. In this context, we aim to incorporate enhanced data transformation techniques by extending the recent success of few-shot learning and a small amount of data representation in text-to-image latent diffusion models. The optimally tuned model is further used for rendering high-quality skin lesion synthetic data with diverse and realistic characteristics, providing a valuable supplement and diversity to the existing training data. We investigate the impact of incorporating newly generated synthetic data into the training pipeline of state-of-art machine learning models, assessing its effectiveness in enhancing model performance and generalization to unseen real-world data. Our experimental results demonstrate the efficacy of the synthetic data generated through stable diffusion models helps in improving the robustness and adaptability of end-to-end CNN and vision transformer models on two different real-world skin lesion datasets.
A lightweight 3D dense facial landmark estimation model from position map data
Aug 29, 2023



The incorporation of 3D data in facial analysis tasks has gained popularity in recent years. Though it provides a more accurate and detailed representation of the human face, accruing 3D face data is more complex and expensive than 2D face images. Either one has to rely on expensive 3D scanners or depth sensors which are prone to noise. An alternative option is the reconstruction of 3D faces from uncalibrated 2D images in an unsupervised way without any ground truth 3D data. However, such approaches are computationally expensive and the learned model size is not suitable for mobile or other edge device applications. Predicting dense 3D landmarks over the whole face can overcome this issue. As there is no public dataset available containing dense landmarks, we propose a pipeline to create a dense keypoint training dataset containing 520 key points across the whole face from an existing facial position map data. We train a lightweight MobileNet-based regressor model with the generated data. As we do not have access to any evaluation dataset with dense landmarks in it we evaluate our model against the 68 keypoint detection task. Experimental results show that our trained model outperforms many of the existing methods in spite of its lower model size and minimal computational cost. Also, the qualitative evaluation shows the efficiency of our trained models in extreme head pose angles as well as other facial variations and occlusions.
Methodology for Building Synthetic Datasets with Virtual Humans
Jun 21, 2020


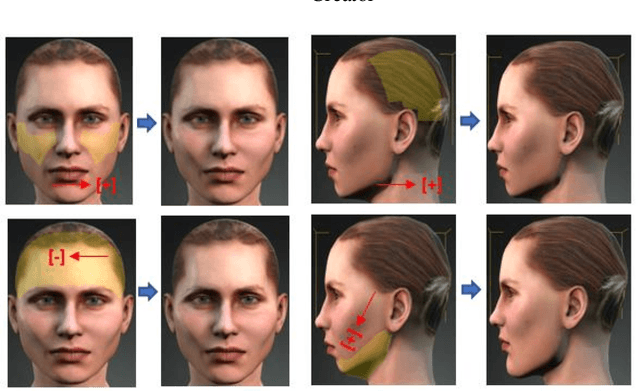
Recent advances in deep learning methods have increased the performance of face detection and recognition systems. The accuracy of these models relies on the range of variation provided in the training data. Creating a dataset that represents all variations of real-world faces is not feasible as the control over the quality of the data decreases with the size of the dataset. Repeatability of data is another challenge as it is not possible to exactly recreate 'real-world' acquisition conditions outside of the laboratory. In this work, we explore a framework to synthetically generate facial data to be used as part of a toolchain to generate very large facial datasets with a high degree of control over facial and environmental variations. Such large datasets can be used for improved, targeted training of deep neural networks. In particular, we make use of a 3D morphable face model for the rendering of multiple 2D images across a dataset of 100 synthetic identities, providing full control over image variations such as pose, illumination, and background.
Deep Reinforcement Learning: An Overview
Jun 23, 2018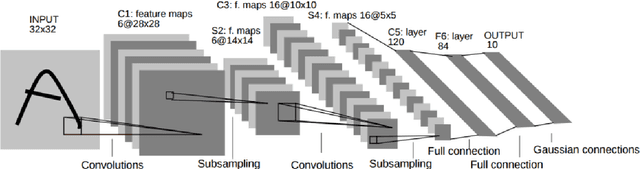
In recent years, a specific machine learning method called deep learning has gained huge attraction, as it has obtained astonishing results in broad applications such as pattern recognition, speech recognition, computer vision, and natural language processing. Recent research has also been shown that deep learning techniques can be combined with reinforcement learning methods to learn useful representations for the problems with high dimensional raw data input. This chapter reviews the recent advances in deep reinforcement learning with a focus on the most used deep architectures such as autoencoders, convolutional neural networks and recurrent neural networks which have successfully been come together with the reinforcement learning framework.
Traffic Light Control Using Deep Policy-Gradient and Value-Function Based Reinforcement Learning
May 27, 2017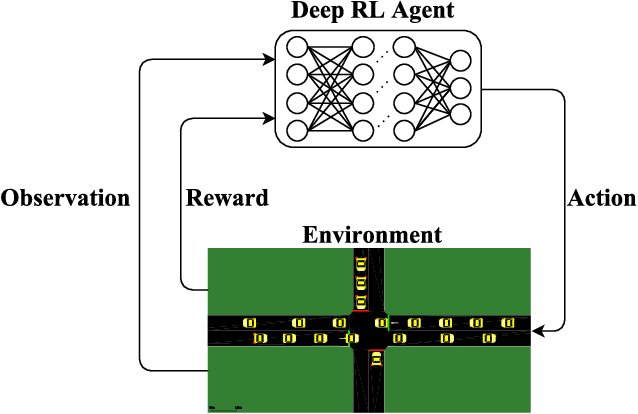
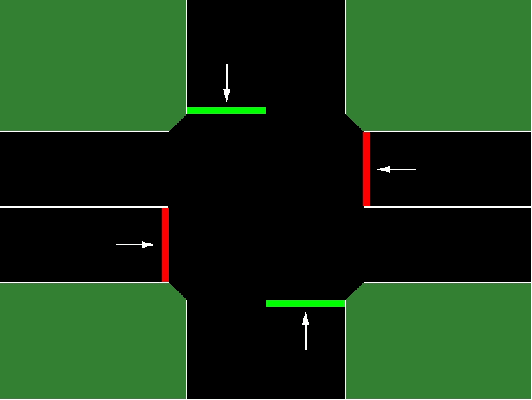
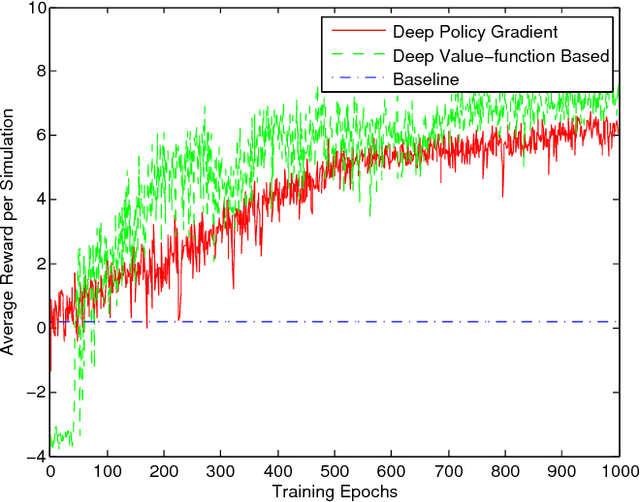
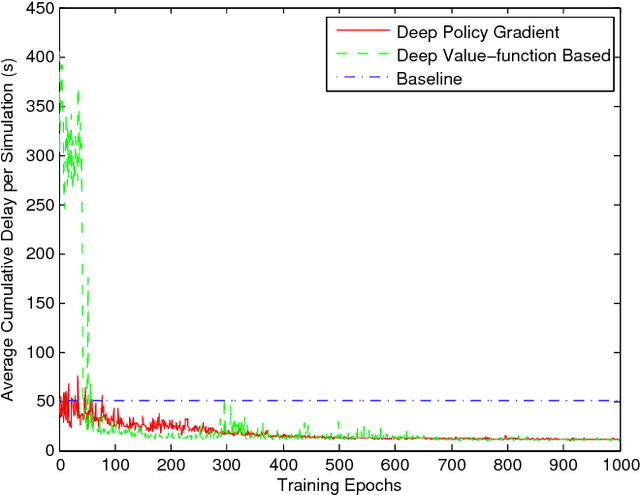
Recent advances in combining deep neural network architectures with reinforcement learning techniques have shown promising potential results in solving complex control problems with high dimensional state and action spaces. Inspired by these successes, in this paper, we build two kinds of reinforcement learning algorithms: deep policy-gradient and value-function based agents which can predict the best possible traffic signal for a traffic intersection. At each time step, these adaptive traffic light control agents receive a snapshot of the current state of a graphical traffic simulator and produce control signals. The policy-gradient based agent maps its observation directly to the control signal, however the value-function based agent first estimates values for all legal control signals. The agent then selects the optimal control action with the highest value. Our methods show promising results in a traffic network simulated in the SUMO traffic simulator, without suffering from instability issues during the training process.
Learning to predict where to look in interactive environments using deep recurrent q-learning
Feb 18, 2017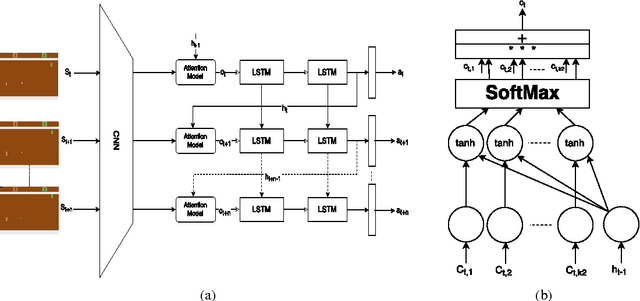
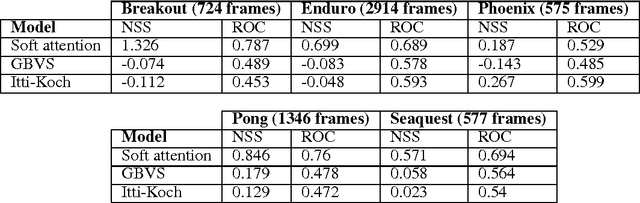


Bottom-Up (BU) saliency models do not perform well in complex interactive environments where humans are actively engaged in tasks (e.g., sandwich making and playing the video games). In this paper, we leverage Reinforcement Learning (RL) to highlight task-relevant locations of input frames. We propose a soft attention mechanism combined with the Deep Q-Network (DQN) model to teach an RL agent how to play a game and where to look by focusing on the most pertinent parts of its visual input. Our evaluations on several Atari 2600 games show that the soft attention based model could predict fixation locations significantly better than bottom-up models such as Itti-Kochs saliency and Graph-Based Visual Saliency (GBVS) models.