 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Sections: An Atlas-Native Feature Ontology for Obstructed Representation Spaces
Mar 21, 2026Recent interpretability work often treats a feature as a single global direction, dictionary atom, or latent coordinate shared across contexts. We argue that this ontology can fail in obstructed representation spaces, where locally coherent meanings need not assemble into one globally consistent feature. We introduce an atlas-native replacement object, the semantic section: a transport-compatible family of local feature representatives defined over a context atlas. We formalize semantic sections, prove that tree-supported propagation is always pathwise realizable, and show that cycle consistency is the key criterion for genuine globalization. This yields a distinction between tree-local, globalizable, and twisted sections, with twisted sections capturing locally coherent but holonomy-obstructed meanings. We then develop a discovery-and-certification pipeline based on seeded propagation, synchronization across overlaps, defect-based pruning, cycle-aware taxonomy, and deduplication. Across layer-16 atlases for Llama 3.2 3B Instruct, Qwen 2.5 3B Instruct, and Gemma 2 2B IT, we find nontrivial populations of semantic sections, including cycle-supported globalizable and twisted regimes after deduplication. Most importantly, semantic identity is not recovered by raw global-vector similarity. Even certified globalizable sections show low cross-chart signed cosine similarity, and raw similarity baselines recover only a small fraction of true within-section pairs, often collapsing at moderate thresholds. By contrast, section-based identity recovery is perfect on certified supports. These results support semantic sections as a better feature ontology in obstructed regimes.
A Gauge Theory of Superposition: Toward a Sheaf-Theoretic Atlas of Neural Representations
Feb 28, 2026We develop a discrete gauge-theoretic framework for superposition in large language models (LLMs) that replaces the single-global-dictionary premise with a sheaf-theoretic atlas of local semantic charts. Contexts are clustered into a stratified context complex; each chart carries a local feature space and a local information-geometric metric (Fisher/Gauss--Newton) identifying predictively consequential feature interactions. This yields a Fisher-weighted interference energy and three measurable obstructions to global interpretability: (O1) local jamming (active load exceeds Fisher bandwidth), (O2) proxy shearing (mismatch between geometric transport and a fixed correspondence proxy), and (O3) nontrivial holonomy (path-dependent transport around loops). We prove and instantiate four results on a frozen open LLM (Llama~3.2~3B Instruct) using WikiText-103, a C4-derived English web-text subset, and \texttt{the-stack-smol}. (A) After constructive gauge fixing on a spanning tree, each chord residual equals the holonomy of its fundamental cycle, making holonomy computable and gauge-invariant. (B) Shearing lower-bounds a data-dependent transfer mismatch energy, turning $D_{\mathrm{shear}}$ into an unavoidable failure bound. (C) We obtain non-vacuous certified jamming/interference bounds with high coverage and zero violations across seeds/hyperparameters. (D) Bootstrap and sample-size experiments show stable estimation of $D_{\mathrm{shear}}$ and $D_{\mathrm{hol}}$, with improved concentration on well-conditioned subsystems.
Multi-scale Attention-Guided Intrinsic Decomposition and Rendering Pass Prediction for Facial Images
Dec 18, 2025

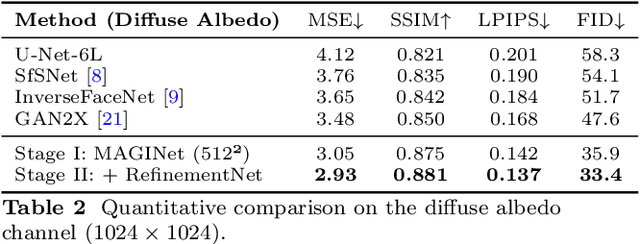

Accurate intrinsic decomposition of face images under unconstrained lighting is a prerequisite for photorealistic relighting, high-fidelity digital doubles, and augmented-reality effects. This paper introduces MAGINet, a Multi-scale Attention-Guided Intrinsics Network that predicts a $512\times512$ light-normalized diffuse albedo map from a single RGB portrait. MAGINet employs hierarchical residual encoding, spatial-and-channel attention in a bottleneck, and adaptive multi-scale feature fusion in the decoder, yielding sharper albedo boundaries and stronger lighting invariance than prior U-Net variants. The initial albedo prediction is upsampled to $1024\times1024$ and refined by a lightweight three-layer CNN (RefinementNet). Conditioned on this refined albedo, a Pix2PixHD-based translator then predicts a comprehensive set of five additional physically based rendering passes: ambient occlusion, surface normal, specular reflectance, translucency, and raw diffuse colour (with residual lighting). Together with the refined albedo, these six passes form the complete intrinsic decomposition. Trained with a combination of masked-MSE, VGG, edge, and patch-LPIPS losses on the FFHQ-UV-Intrinsics dataset, the full pipeline achieves state-of-the-art performance for diffuse albedo estimation and demonstrates significantly improved fidelity for the complete rendering stack compared to prior methods. The resulting passes enable high-quality relighting and material editing of real faces.
High Fidelity Synthetic Face Generation for Rosacea Skin Condition from Limited Data
Mar 08, 2023



Similar to the majority of deep learning applications, diagnosing skin diseases using computer vision and deep learning often requires a large volume of data. However, obtaining sufficient data for particular types of facial skin conditions can be difficult due to privacy concerns. As a result, conditions like Rosacea are often understudied in computer-aided diagnosis. The limited availability of data for facial skin conditions has led to the investigation of alternative methods for computer-aided diagnosis. In recent years, Generative Adversarial Networks (GANs), mainly variants of StyleGANs, have demonstrated promising results in generating synthetic facial images. In this study, for the first time, a small dataset of Rosacea with 300 full-face images is utilized to further investigate the possibility of generating synthetic data. The preliminary experiments show how fine-tuning the model and varying experimental settings significantly affect the fidelity of the Rosacea features. It is demonstrated that $R_1$ Regularization strength helps achieve high-fidelity details. Additionally, this study presents qualitative evaluations of synthetic/generated faces by expert dermatologists and non-specialist participants. The quantitative evaluation is presented using a few validation metric(s). Furthermore a number of limitations and future directions are discussed. Code and generated dataset are available at: \url{https://github.com/thinkercache/stylegan2-ada-pytorch}
An Advert Creation System for 3D Product Placements
Jun 26, 2020
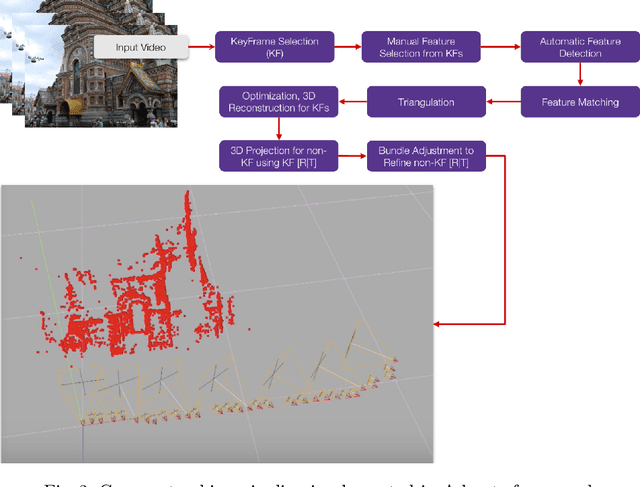

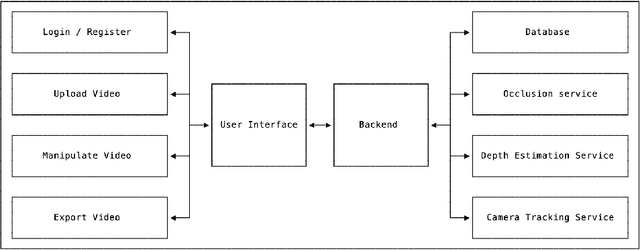
Over the past decade, the evolution of video-sharing platforms has attracted a significant amount of investments on contextual advertising. The common contextual advertising platforms utilize the information provided by users to integrate 2D visual ads into videos. The existing platforms face many technical challenges such as ad integration with respect to occluding objects and 3D ad placement. This paper presents a Video Advertisement Placement & Integration (Adverts) framework, which is capable of perceiving the 3D geometry of the scene and camera motion to blend 3D virtual objects in videos and create the illusion of reality. The proposed framework contains several modules such as monocular depth estimation, object segmentation, background-foreground separation, alpha matting and camera tracking. Our experiments conducted using Adverts framework indicates the significant potential of this system in contextual ad integration, and pushing the limits of advertising industry using mixed reality technologies.
Methodology for Building Synthetic Datasets with Virtual Humans
Jun 21, 2020


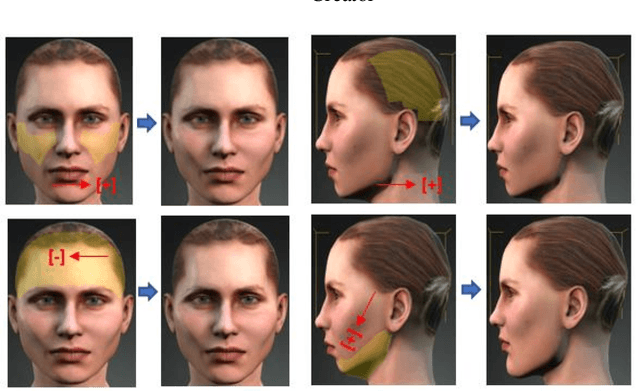
Recent advances in deep learning methods have increased the performance of face detection and recognition systems. The accuracy of these models relies on the range of variation provided in the training data. Creating a dataset that represents all variations of real-world faces is not feasible as the control over the quality of the data decreases with the size of the dataset. Repeatability of data is another challenge as it is not possible to exactly recreate 'real-world' acquisition conditions outside of the laboratory. In this work, we explore a framework to synthetically generate facial data to be used as part of a toolchain to generate very large facial datasets with a high degree of control over facial and environmental variations. Such large datasets can be used for improved, targeted training of deep neural networks. In particular, we make use of a 3D morphable face model for the rendering of multiple 2D images across a dataset of 100 synthetic identities, providing full control over image variations such as pose, illumination, and background.
Background Matting
Feb 11, 2020
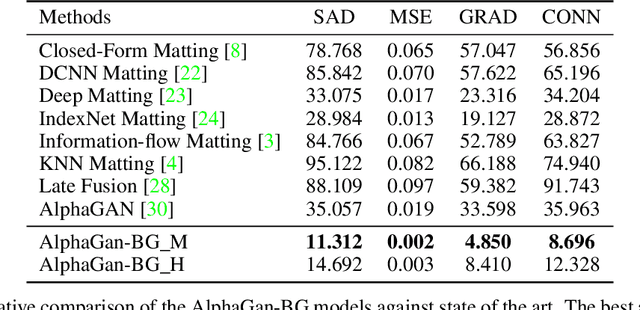


The current state of the art alpha matting methods mainly rely on the trimap as the secondary and only guidance to estimate alpha. This paper investigates the effects of utilising the background information as well as trimap in the process of alpha calculation. To achieve this goal, a state of the art method, AlphaGan is adopted and modified to process the background information as an extra input channel. Extensive experiments are performed to analyse the effect of the background information in image and video matting such as training with mildly and heavily distorted backgrounds. Based on the quantitative evaluations performed on Adobe Composition-1k dataset, the proposed pipeline significantly outperforms the state of the art methods using AlphaMatting benchmark metrics.
Identifying Candidate Spaces for Advert Implantation
Oct 08, 2019
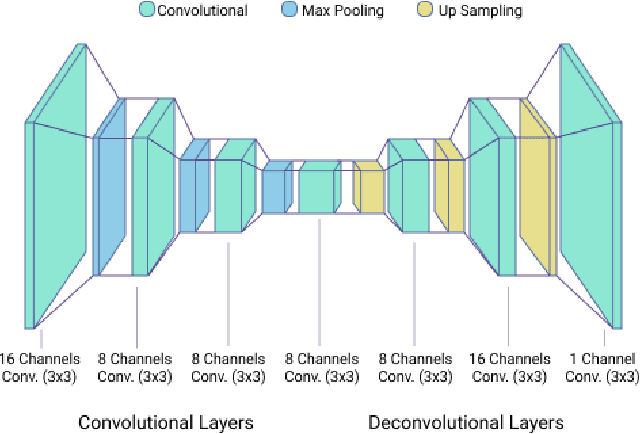

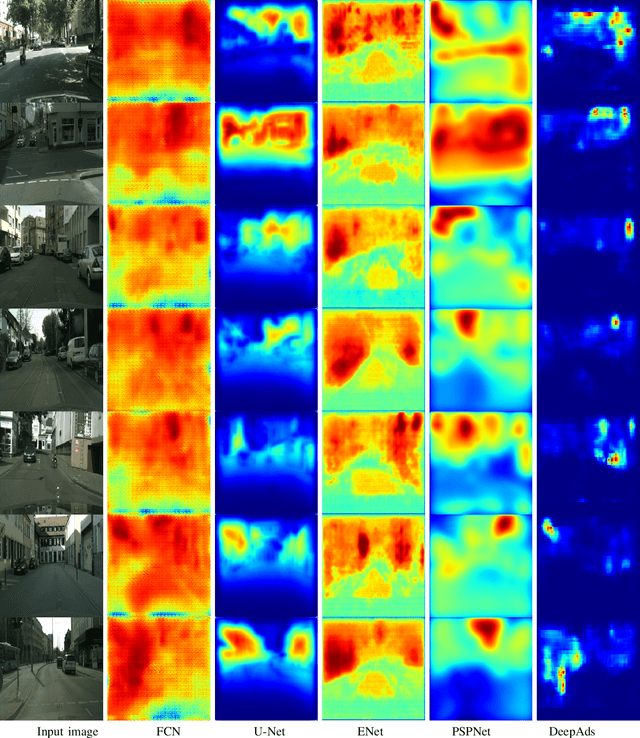
Virtual advertising is an important and promising feature in the area of online advertising. It involves integrating adverts onto live or recorded videos for product placements and targeted advertisements. Such integration of adverts is primarily done by video editors in the post-production stage, which is cumbersome and time-consuming. Therefore, it is important to automatically identify candidate spaces in a video frame, wherein new adverts can be implanted. The candidate space should match the scene perspective, and also have a high quality of experience according to human subjective judgment. In this paper, we propose the use of a bespoke neural net that can assist the video editors in identifying candidate spaces. We benchmark our approach against several deep-learning architectures on a large-scale image dataset of candidate spaces of outdoor scenes. Our work is the first of its kind in this area of multimedia and augmented reality applications, and achieves the best results.
Versatile Auxiliary Classifier with Generative Adversarial Network
Jun 18, 2018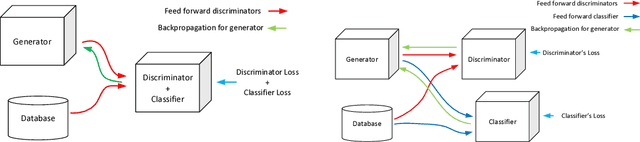



One of the most interesting challenges in Artificial Intelligence is to train conditional generators which are able to provide labeled adversarial samples drawn from a specific distribution. In this work, a new framework is presented to train a deep conditional generator by placing a classifier in parallel with the discriminator and back propagate the classification error through the generator network. The method is versatile and is applicable to any variations of Generative Adversarial Network (GAN) implementation, and also gives superior results compared to similar methods.
The Application of Preconditioned Alternating Direction Method of Multipliers in Depth from Focal Stack
Nov 21, 2017Post capture refocusing effect in smartphone cameras is achievable by using focal stacks. However, the accuracy of this effect is totally dependent on the combination of the depth layers in the stack. The accuracy of the extended depth of field effect in this application can be improved significantly by computing an accurate depth map which has been an open issue for decades. To tackle this issue, in this paper, a framework is proposed based on Preconditioned Alternating Direction Method of Multipliers (PADMM) for depth from the focal stack and synthetic defocus application. In addition to its ability to provide high structural accuracy and occlusion handling, the optimization function of the proposed method can, in fact, converge faster and better than state of the art methods. The evaluation has been done on 21 sets of focal stacks and the optimization function has been compared against 5 other methods. Preliminary results indicate that the proposed method has a better performance in terms of structural accuracy and optimization in comparison to the current state of the art methods.
* 15 pages, 8 figures