 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyWorld: Polygonal Building Extraction with Graph Neural Networks in Satellite Images
Dec 07, 2021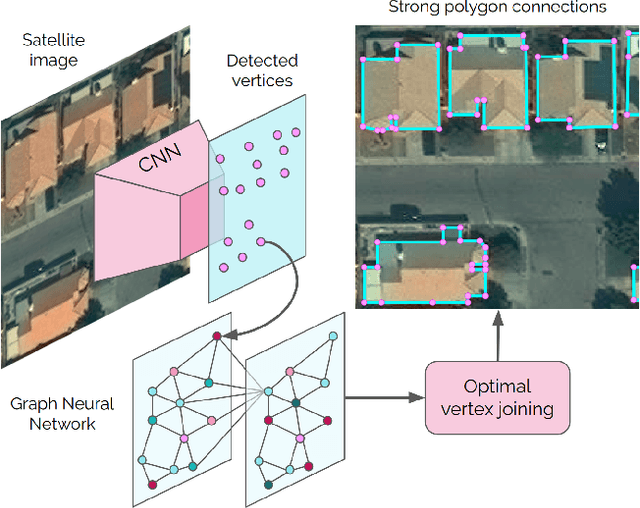
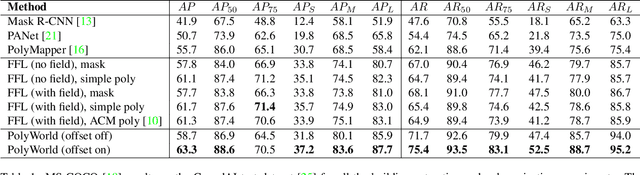
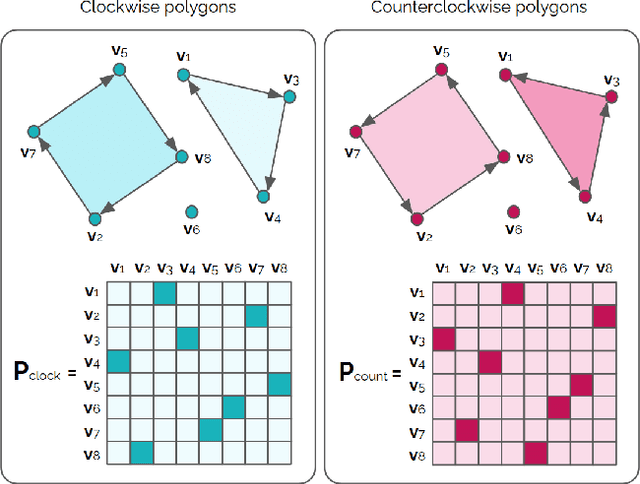
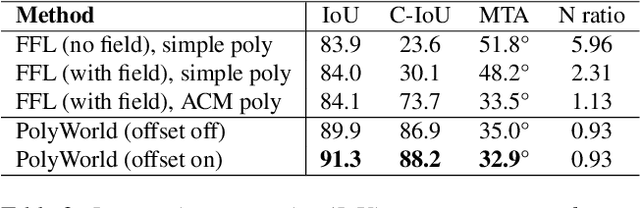
Most state-of-the-art instance segmentation methods produce binary segmentation masks, however, geographic and cartographic applications typically require precise vector polygons of extracted objects instead of rasterized output. This paper introduces PolyWorld, a neural network that directly extracts building vertices from an image and connects them correctly to create precise polygons. The model predicts the connection strength between each pair of vertices using a graph neural network and estimates the assignments by solving a differentiable optimal transport problem. Moreover, the vertex positions are optimized by minimizing a combined segmentation and polygonal angle difference loss. PolyWorld significantly outperforms the state-of-the-art in building polygonization and achieves not only notable quantitative results, but also produces visually pleasing building polygons. Code and trained weights will be soon available on github.
Re-Training StyleGAN -- A First Step Towards Building Large, Scalable Synthetic Facial Datasets
Mar 24, 2020



StyleGAN is a state-of-art generative adversarial network architecture that generates random 2D high-quality synthetic facial data samples. In this paper, we recap the StyleGAN architecture and training methodology and present our experiences of retraining it on a number of alternative public datasets. Practical issues and challenges arising from the retraining process are discussed. Tests and validation results are presented and a comparative analysis of several different re-trained StyleGAN weightings is provided 1. The role of this tool in building large, scalable datasets of synthetic facial data is also discussed.
Deep Learning Based Computed Tomography Whys and Wherefores
Apr 08, 2019
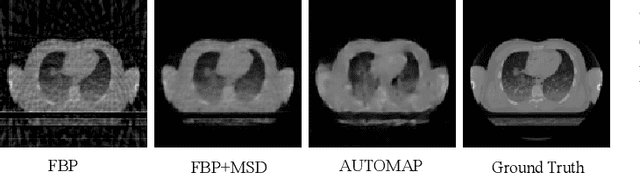
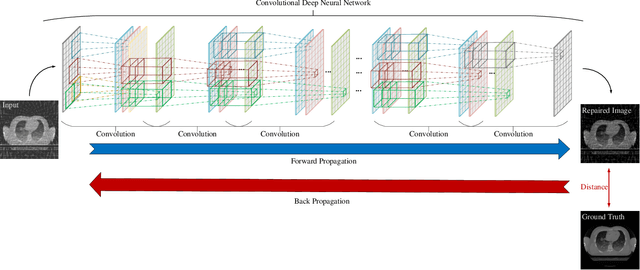
This is an article about the Computed Tomography (CT) and how Deep Learning influences CT reconstruction pipeline, especially in low dose scenarios.
Deep Neural Network and Data Augmentation Methodology for off-axis iris segmentation in wearable headsets
Mar 01, 2019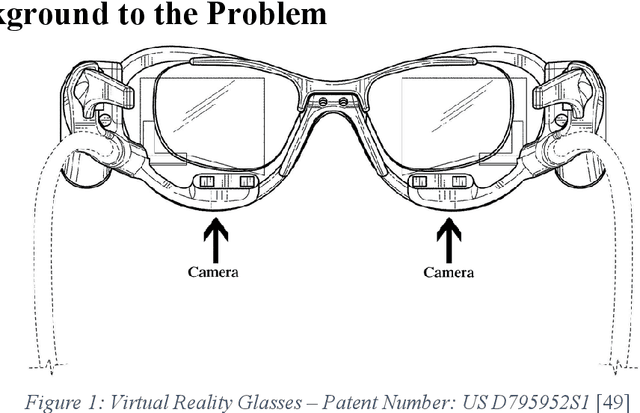
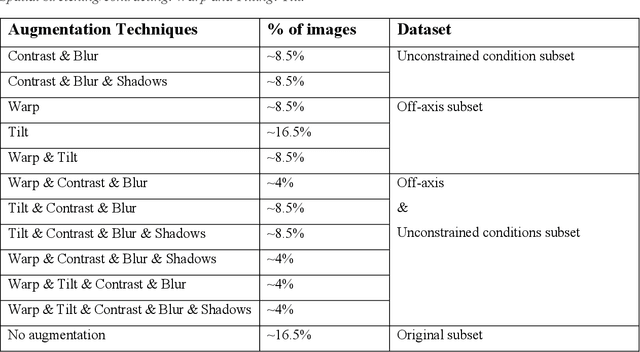

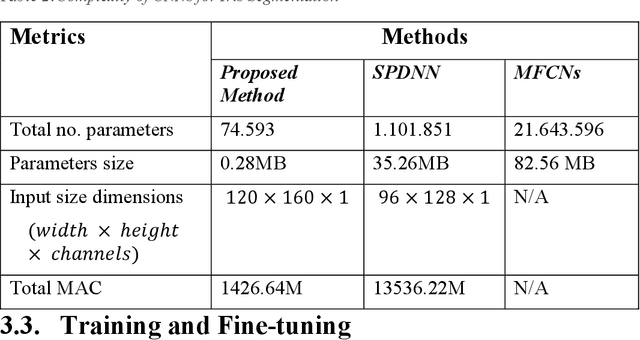
A data augmentation methodology is presented and applied to generate a large dataset of off-axis iris regions and train a low-complexity deep neural network. Although of low complexity the resulting network achieves a high level of accuracy in iris region segmentation for challenging off-axis eye-patches. Interestingly, this network is also shown to achieve high levels of performance for regular, frontal, segmentation of iris regions, comparing favorably with state-of-the-art techniques of significantly higher complexity. Due to its lower complexity, this network is well suited for deployment in embedded applications such as augmented and mixed reality headsets.
Versatile Auxiliary Classifier with Generative Adversarial Network (VAC+GAN), Multi Class Scenarios
Jun 19, 2018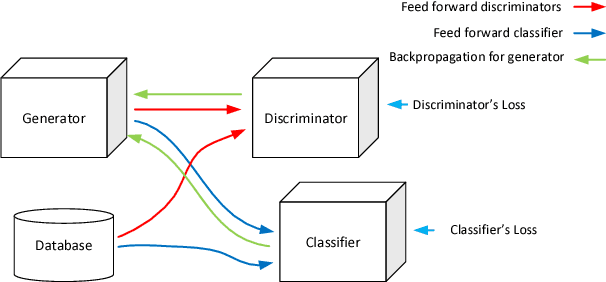
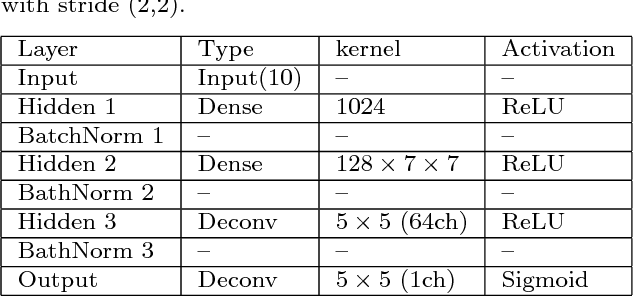

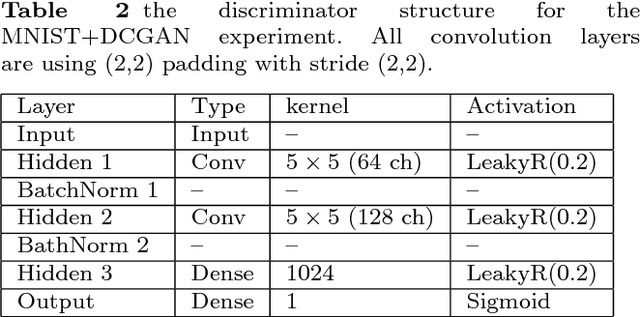
Conditional generators learn the data distribution for each class in a multi-class scenario and generate samples for a specific class given the right input from the latent space. In this work, a method known as "Versatile Auxiliary Classifier with Generative Adversarial Network" for multi-class scenarios is presented. In this technique, the Generative Adversarial Networks (GAN)'s generator is turned into a conditional generator by placing a multi-class classifier in parallel with the discriminator network and backpropagate the classification error through the generator. This technique is versatile enough to be applied to any GAN implementation. The results on two databases and comparisons with other method are provided as well.
Versatile Auxiliary Classifier with Generative Adversarial Network
Jun 18, 2018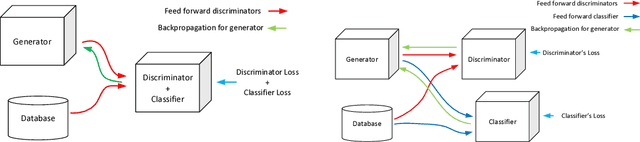



One of the most interesting challenges in Artificial Intelligence is to train conditional generators which are able to provide labeled adversarial samples drawn from a specific distribution. In this work, a new framework is presented to train a deep conditional generator by placing a classifier in parallel with the discriminator and back propagate the classification error through the generator network. The method is versatile and is applicable to any variations of Generative Adversarial Network (GAN) implementation, and also gives superior results compared to similar methods.
Versatile Auxiliary Regressor with Generative Adversarial network (VAR+GAN)
May 28, 2018
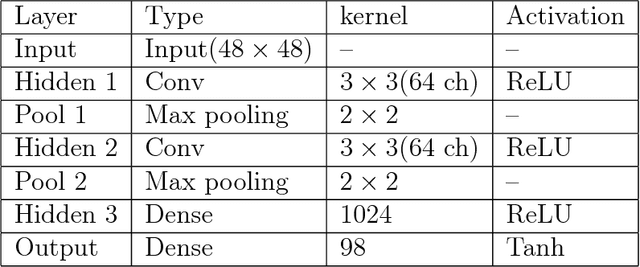
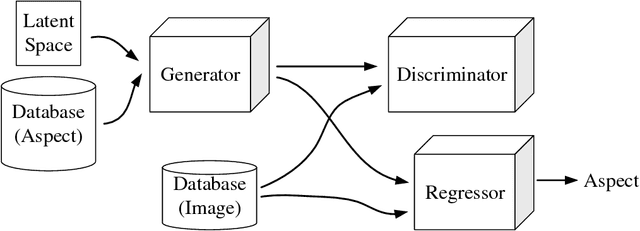
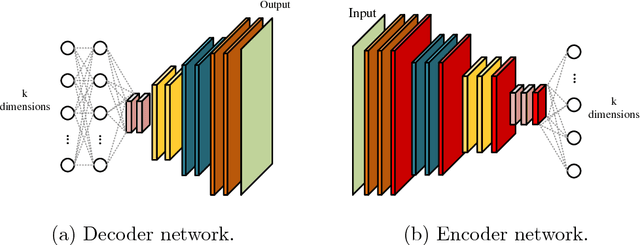
Being able to generate constrained samples is one of the most appealing applications of the deep generators. Conditional generators are one of the successful implementations of such models wherein the created samples are constrained to a specific class. In this work, the application of these networks is extended to regression problems wherein the conditional generator is restrained to any continuous aspect of the data. A new loss function is presented for the regression network and also implementations for generating faces with any particular set of landmarks is provided.
An End to End Deep Neural Network for Iris Segmentation in Unconstraint Scenarios
Dec 07, 2017

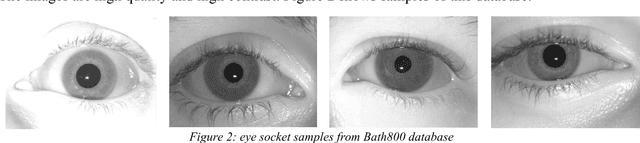
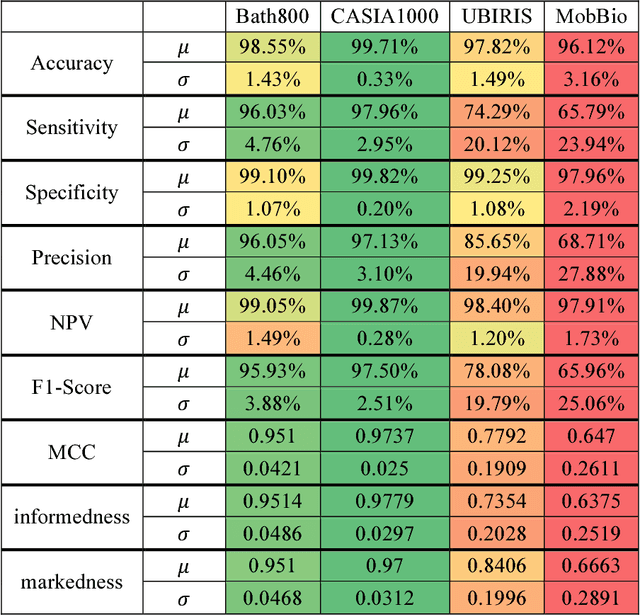
With the increasing imaging and processing capabilities of today's mobile devices, user authentication using iris biometrics has become feasible. However, as the acquisition conditions become more unconstrained and as image quality is typically lower than dedicated iris acquisition systems, the accurate segmentation of iris regions is crucial for these devices. In this work, an end to end Fully Convolutional Deep Neural Network (FCDNN) design is proposed to perform the iris segmentation task for lower-quality iris images. The network design process is explained in detail, and the resulting network is trained and tuned using several large public iris datasets. A set of methods to generate and augment suitable lower quality iris images from the high-quality public databases are provided. The network is trained on Near InfraRed (NIR) images initially and later tuned on additional datasets derived from visible images. Comprehensive inter-database comparisons are provided together with results from a selection of experiments detailing the effects of different tunings of the network. Finally, the proposed model is compared with SegNet-basic, and a near-optimal tuning of the network is compared to a selection of other state-of-art iris segmentation algorithms. The results show very promising performance from the optimized Deep Neural Networks design when compared with state-of-art techniques applied to the same lower quality datasets.
Smart Augmentation - Learning an Optimal Data Augmentation Strategy
Mar 24, 2017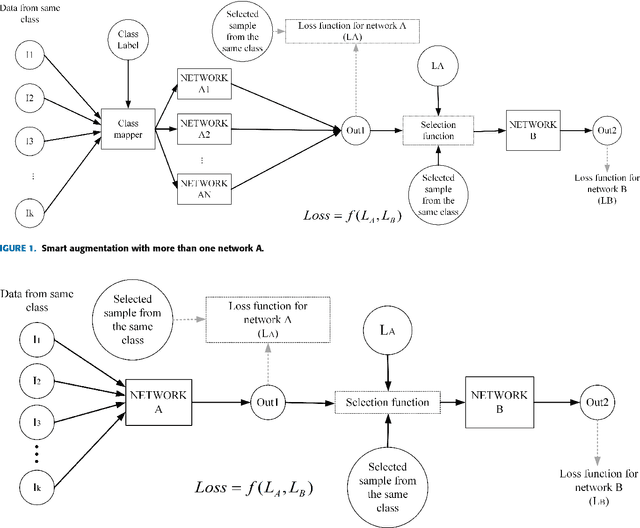


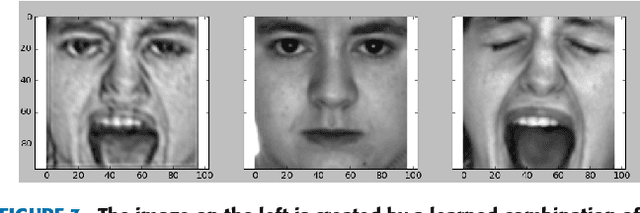
A recurring problem faced when training neural networks is that there is typically not enough data to maximize the generalization capability of deep neural networks(DNN). There are many techniques to address this, including data augmentation, dropout, and transfer learning. In this paper, we introduce an additional method which we call Smart Augmentation and we show how to use it to increase the accuracy and reduce overfitting on a target network. Smart Augmentation works by creating a network that learns how to generate augmented data during the training process of a target network in a way that reduces that networks loss. This allows us to learn augmentations that minimize the error of that network. Smart Augmentation has shown the potential to increase accuracy by demonstrably significant measures on all datasets tested. In addition, it has shown potential to achieve similar or improved performance levels with significantly smaller network sizes in a number of tested cases.