 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards End-to-End Neural Face Authentication in the Wild -- Quantifying and Compensating for Directional Lighting Effects
Apr 08, 2021


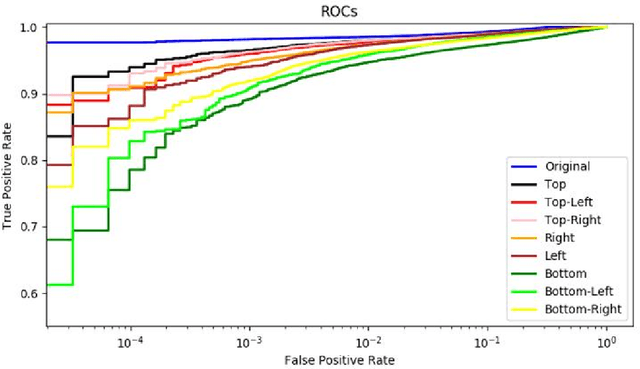
The recent availability of low-power neural accelerator hardware, combined with improvements in end-to-end neural facial recognition algorithms provides, enabling technology for on-device facial authentication. The present research work examines the effects of directional lighting on a State-of-Art(SoA) neural face recognizer. A synthetic re-lighting technique is used to augment data samples due to the lack of public data-sets with sufficient directional lighting variations. Top lighting and its variants (top-left, top-right) are found to have minimal effect on accuracy, while bottom-left or bottom-right directional lighting has the most pronounced effects. Following the fine-tuning of network weights, the face recognition model is shown to achieve close to the original Receiver Operating Characteristic curve (ROC)performance across all lighting conditions and demonstrates an ability to generalize beyond the lighting augmentations used in the fine-tuning data-set. This work shows that an SoA neural face recognition model can be tuned to compensate for directional lighting effects, removing the need for a pre-processing step before applying facial recognition.
Re-Training StyleGAN -- A First Step Towards Building Large, Scalable Synthetic Facial Datasets
Mar 24, 2020



StyleGAN is a state-of-art generative adversarial network architecture that generates random 2D high-quality synthetic facial data samples. In this paper, we recap the StyleGAN architecture and training methodology and present our experiences of retraining it on a number of alternative public datasets. Practical issues and challenges arising from the retraining process are discussed. Tests and validation results are presented and a comparative analysis of several different re-trained StyleGAN weightings is provided 1. The role of this tool in building large, scalable datasets of synthetic facial data is also discussed.
Dataset Cleaning -- A Cross Validation Methodology for Large Facial Datasets using Face Recognition
Mar 24, 2020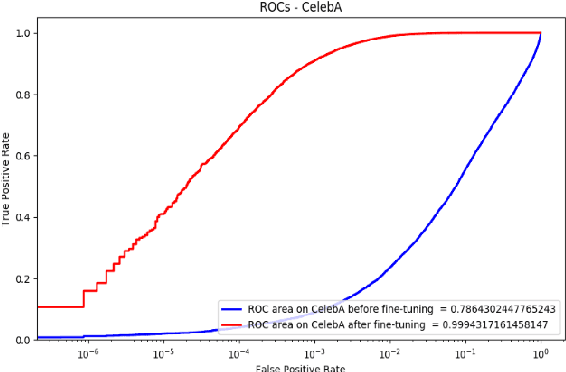
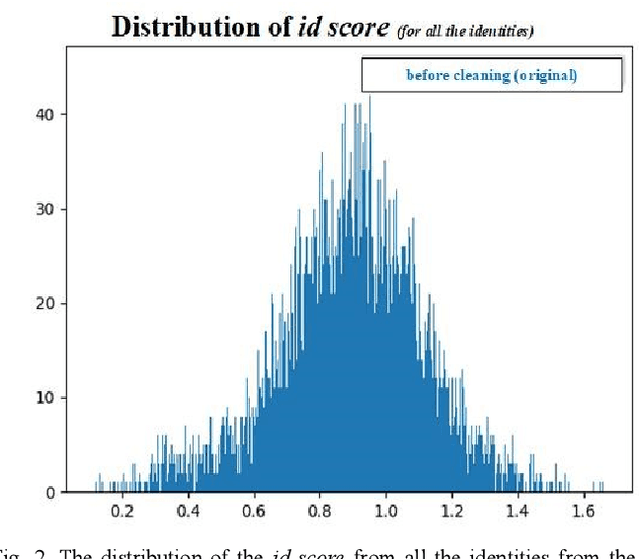


In recent years, large "in the wild" face datasets have been released in an attempt to facilitate progress in tasks such as face detection, face recognition, and other tasks. Most of these datasets are acquired from webpages with automatic procedures. As a consequence, noisy data are often found. Furthermore, in these large face datasets, the annotation of identities is important as they are used for training face recognition algorithms. But due to the automatic way of gathering these datasets and due to their large size, many identities folder contain mislabeled samples which deteriorates the quality of the datasets. In this work, it is presented a semi-automatic method for cleaning the noisy large face datasets with the use of face recognition. This methodology is applied to clean the CelebA dataset and show its effectiveness. Furthermore, the list with the mislabelled samples in the CelebA dataset is made available.
Advanced Deep Learning Methodologies for Skin Cancer Classification in Prodromal Stages
Mar 13, 2020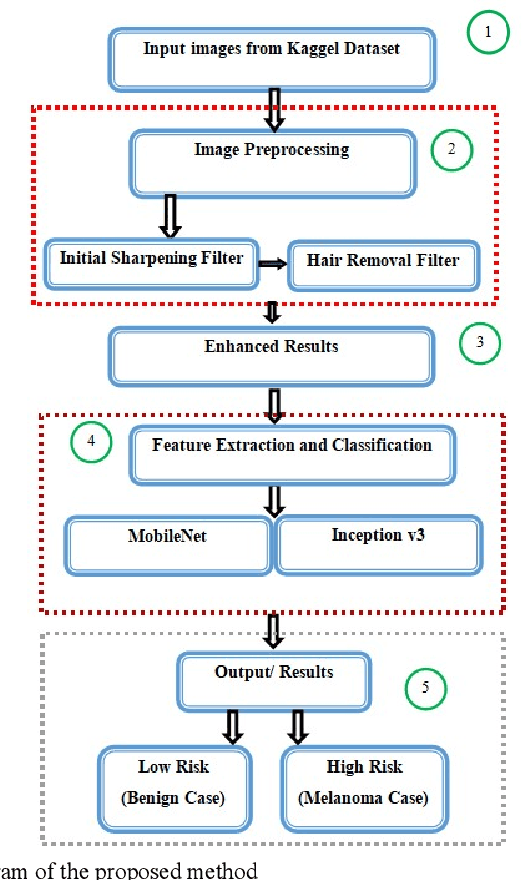
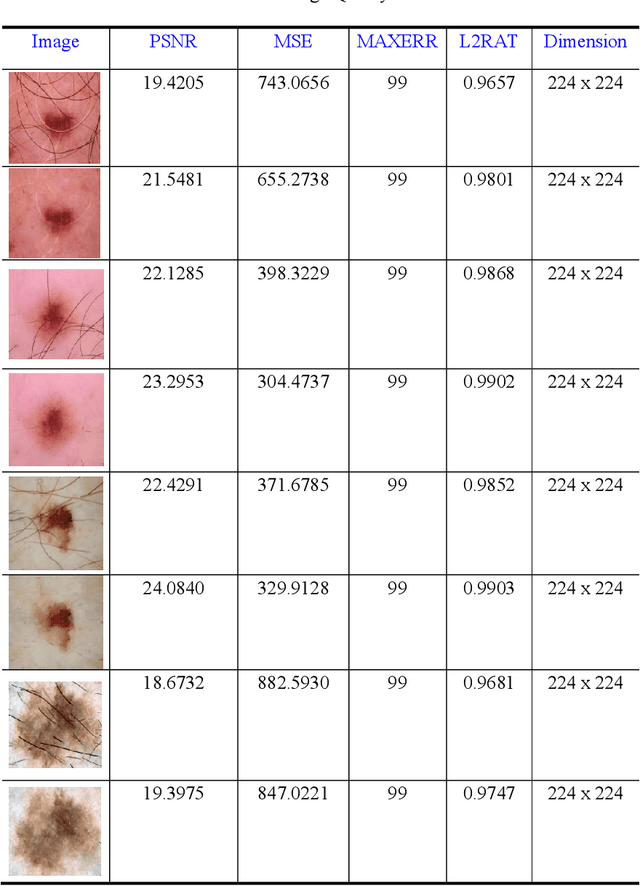
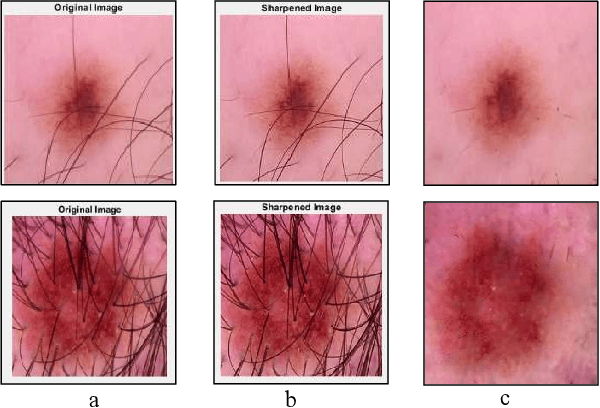
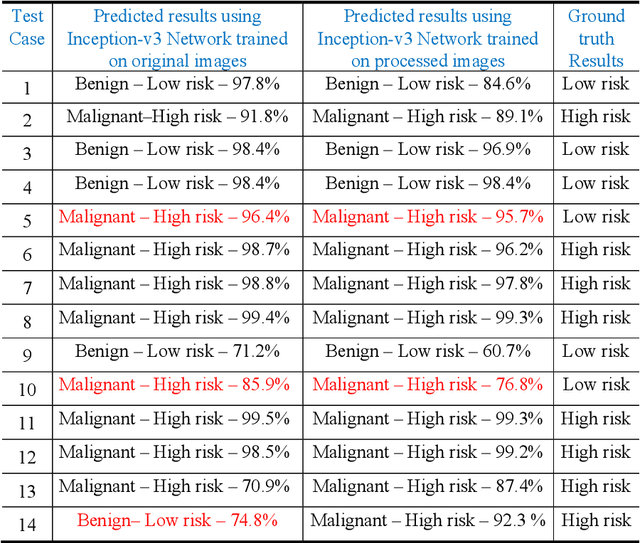
Technology-assisted platforms provide reliable solutions in almost every field these days. One such important application in the medical field is the skin cancer classification in preliminary stages that need sensitive and precise data analysis. For the proposed study the Kaggle skin cancer dataset is utilized. The proposed study consists of two main phases. In the first phase, the images are preprocessed to remove the clutters thus producing a refined version of training images. To achieve that, a sharpening filter is applied followed by a hair removal algorithm. Different image quality measurement metrics including Peak Signal to Noise (PSNR), Mean Square Error (MSE), Maximum Absolute Squared Deviation (MXERR) and Energy Ratio/ Ratio of Squared Norms (L2RAT) are used to compare the overall image quality before and after applying preprocessing operations. The results from the aforementioned image quality metrics prove that image quality is not compromised however it is upgraded by applying the preprocessing operations. The second phase of the proposed research work incorporates deep learning methodologies that play an imperative role in accurate, precise and robust classification of the lesion mole. This has been reflected by using two state of the art deep learning models: Inception-v3 and MobileNet. The experimental results demonstrate notable improvement in train and validation accuracy by using the refined version of images of both the networks, however, the Inception-v3 network was able to achieve better validation accuracy thus it was finally selected to evaluate it on test data. The final test accuracy using state of art Inception-v3 network was 86%.
Deep Neural Network and Data Augmentation Methodology for off-axis iris segmentation in wearable headsets
Mar 01, 2019
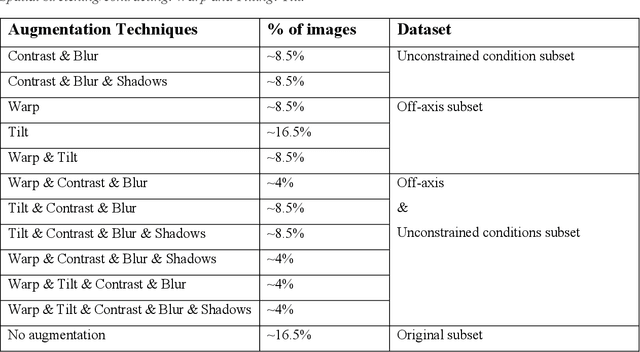

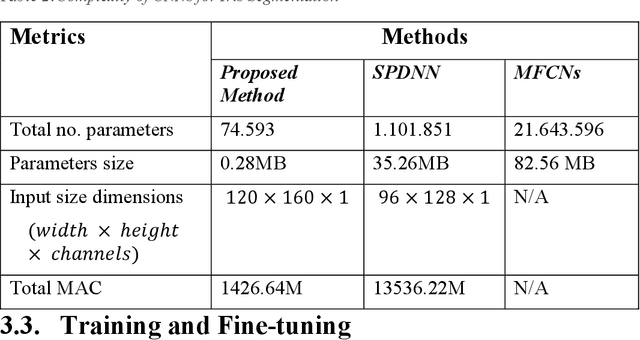
A data augmentation methodology is presented and applied to generate a large dataset of off-axis iris regions and train a low-complexity deep neural network. Although of low complexity the resulting network achieves a high level of accuracy in iris region segmentation for challenging off-axis eye-patches. Interestingly, this network is also shown to achieve high levels of performance for regular, frontal, segmentation of iris regions, comparing favorably with state-of-the-art techniques of significantly higher complexity. Due to its lower complexity, this network is well suited for deployment in embedded applications such as augmented and mixed reality headsets.