 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Review to Design: Ethical Multimodal Driver Monitoring Systems for Risk Mitigation, Incident Response, and Accountability in Automated Vehicles
May 07, 2026As vehicles transition toward higher levels of automation, Driver Monitoring Systems (DMS) have become essential for ensuring human oversight, safety, and regulatory compliance in a vehicle. These systems rely on multimodal sensing and AI-driven inference to assess driver attention, cognitive state, and readiness to take control. While technologically promising, their deployment introduces a complex set of ethical and legal challenges - ranging from privacy and consent to data ownership and algorithmic fairness. While overarching frameworks such as the GDPR, EU AI Act, and IEEE standards offer important guidance, they lack the specificity required for addressing the unique risks posed by in-cabin sensing technologies. This paper adopts a review-to-design perspective, critically examining existing regulatory instruments and ethical frameworks -- such as the GDPR, the EU AI Act, and IEEE guidelines -- and identifying gaps in their applicability to the distinctive risks posed by multimodal, AI-enabled in-cabin monitoring. Building on this review, we propose a modular ethical design framework tailored specifically to Driver Monitoring Systems. The framework translates high-level principles into actionable design and deployment guidance, including user-configurable consent mechanisms, fairness-aware model development, transparency and explainability tools, and safeguards for driver emotional well-being. Finally, the paper outlines a risk analysis and failure mitigation strategy, emphasizing proactive incident response and accountability mechanisms tailored to the DMS context. Together, these contributions aim to inform the development of transparent, trustworthy, and human-centered driver monitoring systems for next-generation autonomous vehicles.
Locally Adaptive Decay Surfaces for High-Speed Face and Landmark Detection with Event Cameras
Feb 26, 2026Event cameras record luminance changes with microsecond resolution, but converting their sparse, asynchronous output into dense tensors that neural networks can exploit remains a core challenge. Conventional histograms or globally-decayed time-surface representations apply fixed temporal parameters across the entire image plane, which in practice creates a trade-off between preserving spatial structure during still periods and retaining sharp edges during rapid motion. We introduce Locally Adaptive Decay Surfaces (LADS), a family of event representations in which the temporal decay at each location is modulated according to local signal dynamics. Three strategies are explored, based on event rate, Laplacian-of-Gaussian response, and high-frequency spectral energy. These adaptive schemes preserve detail in quiescent regions while reducing blur in regions of dense activity. Extensive experiments on the public data show that LADS consistently improves both face detection and facial landmark accuracy compared to standard non-adaptive representations. At 30 Hz, LADS achieves higher detection accuracy and lower landmark error than either baseline, and at 240 Hz it mitigates the accuracy decline typically observed at higher frequencies, sustaining 2.44 % normalized mean error for landmarks and 0.966 mAP50 in face detection. These high-frequency results even surpass the accuracy reported in prior works operating at 30 Hz, setting new benchmarks for event-based face analysis. Moreover, by preserving spatial structure at the representation stage, LADS supports the use of much lighter network architectures while still retaining real-time performance. These results highlight the importance of context-aware temporal integration for neuromorphic vision and point toward real-time, high-frequency human-computer interaction systems that exploit the unique advantages of event cameras.
A Lightweight 3D-CNN for Event-Based Human Action Recognition with Privacy-Preserving Potential
Nov 05, 2025

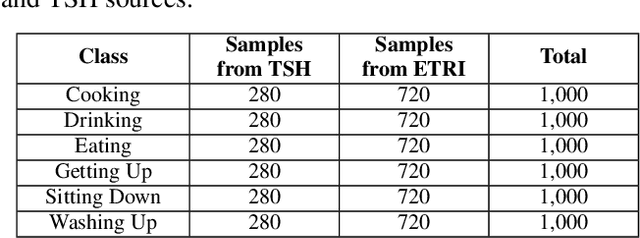

This paper presents a lightweight three-dimensional convolutional neural network (3DCNN) for human activity recognition (HAR) using event-based vision data. Privacy preservation is a key challenge in human monitoring systems, as conventional frame-based cameras capture identifiable personal information. In contrast, event cameras record only changes in pixel intensity, providing an inherently privacy-preserving sensing modality. The proposed network effectively models both spatial and temporal dynamics while maintaining a compact design suitable for edge deployment. To address class imbalance and enhance generalization, focal loss with class reweighting and targeted data augmentation strategies are employed. The model is trained and evaluated on a composite dataset derived from the Toyota Smart Home and ETRI datasets. Experimental results demonstrate an F1-score of 0.9415 and an overall accuracy of 94.17%, outperforming benchmark 3D-CNN architectures such as C3D, ResNet3D, and MC3_18 by up to 3%. These results highlight the potential of event-based deep learning for developing accurate, efficient, and privacy-aware human action recognition systems suitable for real-world edge applications.
Differential Analysis of Pseudo Haptic Feedback: Novel Comparative Study of Visual and Auditory Cue Integration for Psychophysical Evaluation
Oct 10, 2025Pseudo-haptics exploit carefully crafted visual or auditory cues to trick the brain into "feeling" forces that are never physically applied, offering a low-cost alternative to traditional haptic hardware. Here, we present a comparative psychophysical study that quantifies how visual and auditory stimuli combine to evoke pseudo-haptic pressure sensations on a commodity tablet. Using a Unity-based Rollball game, participants (n = 4) guided a virtual ball across three textured terrains while their finger forces were captured in real time with a Robotous RFT40 force-torque sensor. Each terrain was paired with a distinct rolling-sound profile spanning 440 Hz - 4.7 kHz, 440 Hz - 13.1 kHz, or 440 Hz - 8.9 kHz; crevice collisions triggered additional "knocking" bursts to heighten realism. Average tactile forces increased systematically with cue intensity: 0.40 N, 0.79 N and 0.88 N for visual-only trials and 0.41 N, 0.81 N and 0.90 N for audio-only trials on Terrains 1-3, respectively. Higher audio frequencies and denser visual textures both elicited stronger muscle activation, and their combination further reduced the force needed to perceive surface changes, confirming multisensory integration. These results demonstrate that consumer-grade isometric devices can reliably induce and measure graded pseudo-haptic feedback without specialized actuators, opening a path toward affordable rehabilitation tools, training simulators and assistive interfaces.
Contactless Cardiac Pulse Monitoring Using Event Cameras
May 14, 2025Time event cameras are a novel technology for recording scene information at extremely low latency and with low power consumption. Event cameras output a stream of events that encapsulate pixel-level light intensity changes within the scene, capturing information with a higher dynamic range and temporal resolution than traditional cameras. This study investigates the contact-free reconstruction of an individual's cardiac pulse signal from time event recording of their face using a supervised convolutional neural network (CNN) model. An end-to-end model is trained to extract the cardiac signal from a two-dimensional representation of the event stream, with model performance evaluated based on the accuracy of the calculated heart rate. The experimental results confirm that physiological cardiac information in the facial region is effectively preserved within the event stream, showcasing the potential of this novel sensor for remote heart rate monitoring. The model trained on event frames achieves a root mean square error (RMSE) of 3.32 beats per minute (bpm) compared to the RMSE of 2.92 bpm achieved by the baseline model trained on standard camera frames. Furthermore, models trained on event frames generated at 60 and 120 FPS outperformed the 30 FPS standard camera results, achieving an RMSE of 2.54 and 2.13 bpm, respectively.
Video-DPRP: A Differentially Private Approach for Visual Privacy-Preserving Video Human Activity Recognition
Mar 03, 2025Considerable effort has been made in privacy-preserving video human activity recognition (HAR). Two primary approaches to ensure privacy preservation in Video HAR are differential privacy (DP) and visual privacy. Techniques enforcing DP during training provide strong theoretical privacy guarantees but offer limited capabilities for visual privacy assessment. Conversely methods, such as low-resolution transformations, data obfuscation and adversarial networks, emphasize visual privacy but lack clear theoretical privacy assurances. In this work, we focus on two main objectives: (1) leveraging DP properties to develop a model-free approach for visual privacy in videos and (2) evaluating our proposed technique using both differential privacy and visual privacy assessments on HAR tasks. To achieve goal (1), we introduce Video-DPRP: a Video-sample-wise Differentially Private Random Projection framework for privacy-preserved video reconstruction for HAR. By using random projections, noise matrices and right singular vectors derived from the singular value decomposition of videos, Video-DPRP reconstructs DP videos using privacy parameters ($\epsilon,\delta$) while enabling visual privacy assessment. For goal (2), using UCF101 and HMDB51 datasets, we compare Video-DPRP's performance on activity recognition with traditional DP methods, and state-of-the-art (SOTA) visual privacy-preserving techniques. Additionally, we assess its effectiveness in preserving privacy-related attributes such as facial features, gender, and skin color, using the PA-HMDB and VISPR datasets. Video-DPRP combines privacy-preservation from both a DP and visual privacy perspective unlike SOTA methods that typically address only one of these aspects.
Autobiasing Event Cameras
Nov 01, 2024



This paper presents an autonomous method to address challenges arising from severe lighting conditions in machine vision applications that use event cameras. To manage these conditions, the research explores the built in potential of these cameras to adjust pixel functionality, named bias settings. As cars are driven at various times and locations, shifts in lighting conditions are unavoidable. Consequently, this paper utilizes the neuromorphic YOLO-based face tracking module of a driver monitoring system as the event-based application to study. The proposed method uses numerical metrics to continuously monitor the performance of the event-based application in real-time. When the application malfunctions, the system detects this through a drop in the metrics and automatically adjusts the event cameras bias values. The Nelder-Mead simplex algorithm is employed to optimize this adjustment, with finetuning continuing until performance returns to a satisfactory level. The advantage of bias optimization lies in its ability to handle conditions such as flickering or darkness without requiring additional hardware or software. To demonstrate the capabilities of the proposed system, it was tested under conditions where detecting human faces with default bias values was impossible. These severe conditions were simulated using dim ambient light and various flickering frequencies. Following the automatic and dynamic process of bias modification, the metrics for face detection significantly improved under all conditions. Autobiasing resulted in an increase in the YOLO confidence indicators by more than 33 percent for object detection and 37 percent for face detection highlighting the effectiveness of the proposed method.
ControlCol: Controllability in Automatic Speaker Video Colorization
Aug 21, 2024Adding color to black-and-white speaker videos automatically is a highly desirable technique. It is an artistic process that requires interactivity with humans for the best results. Many existing automatic video colorization systems provide little opportunity for the user to guide the colorization process. In this work, we introduce a novel automatic speaker video colorization system which provides controllability to the user while also maintaining high colorization quality relative to state-of-the-art techniques. We name this system ControlCol. ControlCol performs 3.5% better than the previous state-of-the-art DeOldify on the Grid and Lombard Grid datasets when PSNR, SSIM, FID and FVD are used as metrics. This result is also supported by our human evaluation, where in a head-to-head comparison, ControlCol is preferred 90% of the time to DeOldify. Example videos can be seen in the supplementary material.
Event-Stream Super Resolution using Sigma-Delta Neural Network
Aug 13, 2024This study introduces a novel approach to enhance the spatial-temporal resolution of time-event pixels based on luminance changes captured by event cameras. These cameras present unique challenges due to their low resolution and the sparse, asynchronous nature of the data they collect. Current event super-resolution algorithms are not fully optimized for the distinct data structure produced by event cameras, resulting in inefficiencies in capturing the full dynamism and detail of visual scenes with improved computational complexity. To bridge this gap, our research proposes a method that integrates binary spikes with Sigma Delta Neural Networks (SDNNs), leveraging spatiotemporal constraint learning mechanism designed to simultaneously learn the spatial and temporal distributions of the event stream. The proposed network is evaluated using widely recognized benchmark datasets, including N-MNIST, CIFAR10-DVS, ASL-DVS, and Event-NFS. A comprehensive evaluation framework is employed, assessing both the accuracy, through root mean square error (RMSE), and the computational efficiency of our model. The findings demonstrate significant improvements over existing state-of-the-art methods, specifically, the proposed method outperforms state-of-the-art performance in computational efficiency, achieving a 17.04-fold improvement in event sparsity and a 32.28-fold increase in synaptic operation efficiency over traditional artificial neural networks, alongside a two-fold better performance over spiking neural networks.
Spiking-DD: Neuromorphic Event Camera based Driver Distraction Detection with Spiking Neural Network
Jul 30, 2024Event camera-based driver monitoring is emerging as a pivotal area of research, driven by its significant advantages such as rapid response, low latency, power efficiency, enhanced privacy, and prevention of undersampling. Effective detection of driver distraction is crucial in driver monitoring systems to enhance road safety and reduce accident rates. The integration of an optimized sensor such as Event Camera with an optimized network is essential for maximizing these benefits. This paper introduces the innovative concept of sensing without seeing to detect driver distraction, leveraging computationally efficient spiking neural networks (SNN). To the best of our knowledge, this study is the first to utilize event camera data with spiking neural networks for driver distraction. The proposed Spiking-DD network not only achieve state of the art performance but also exhibit fewer parameters and provides greater accuracy than current event-based methodologies.