 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-DPRP: A Differentially Private Approach for Visual Privacy-Preserving Video Human Activity Recognition
Mar 03, 2025Considerable effort has been made in privacy-preserving video human activity recognition (HAR). Two primary approaches to ensure privacy preservation in Video HAR are differential privacy (DP) and visual privacy. Techniques enforcing DP during training provide strong theoretical privacy guarantees but offer limited capabilities for visual privacy assessment. Conversely methods, such as low-resolution transformations, data obfuscation and adversarial networks, emphasize visual privacy but lack clear theoretical privacy assurances. In this work, we focus on two main objectives: (1) leveraging DP properties to develop a model-free approach for visual privacy in videos and (2) evaluating our proposed technique using both differential privacy and visual privacy assessments on HAR tasks. To achieve goal (1), we introduce Video-DPRP: a Video-sample-wise Differentially Private Random Projection framework for privacy-preserved video reconstruction for HAR. By using random projections, noise matrices and right singular vectors derived from the singular value decomposition of videos, Video-DPRP reconstructs DP videos using privacy parameters ($\epsilon,\delta$) while enabling visual privacy assessment. For goal (2), using UCF101 and HMDB51 datasets, we compare Video-DPRP's performance on activity recognition with traditional DP methods, and state-of-the-art (SOTA) visual privacy-preserving techniques. Additionally, we assess its effectiveness in preserving privacy-related attributes such as facial features, gender, and skin color, using the PA-HMDB and VISPR datasets. Video-DPRP combines privacy-preservation from both a DP and visual privacy perspective unlike SOTA methods that typically address only one of these aspects.
Explaining Deep Learning Models for Structured Data using Layer-Wise Relevance Propagation
Nov 26, 2020

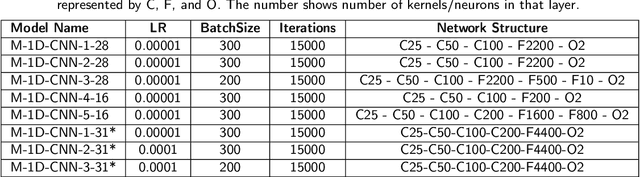
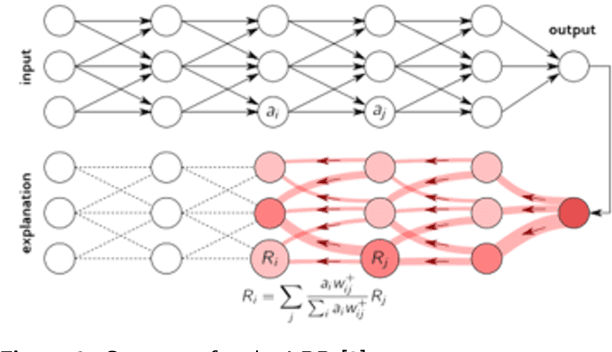
Trust and credibility in machine learning models is bolstered by the ability of a model to explain itsdecisions. While explainability of deep learning models is a well-known challenge, a further chal-lenge is clarity of the explanation itself, which must be interpreted by downstream users. Layer-wiseRelevance Propagation (LRP), an established explainability technique developed for deep models incomputer vision, provides intuitive human-readable heat maps of input images. We present the novelapplication of LRP for the first time with structured datasets using a deep neural network (1D-CNN),for Credit Card Fraud detection and Telecom Customer Churn prediction datasets. We show how LRPis more effective than traditional explainability concepts of Local Interpretable Model-agnostic Ex-planations (LIME) and Shapley Additive Explanations (SHAP) for explainability. This effectivenessis both local to a sample level and holistic over the whole testing set. We also discuss the significantcomputational time advantage of LRP (1-2s) over LIME (22s) and SHAP (108s), and thus its poten-tial for real time application scenarios. In addition, our validation of LRP has highlighted features forenhancing model performance, thus opening up a new area of research of using XAI as an approachfor feature subset selection