 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentColorization: Latent Diffusion-Based Speaker Video Colorization
May 09, 2024While current research predominantly focuses on image-based colorization, the domain of video-based colorization remains relatively unexplored. Most existing video colorization techniques operate on a frame-by-frame basis, often overlooking the critical aspect of temporal coherence between successive frames. This approach can result in inconsistencies across frames, leading to undesirable effects like flickering or abrupt color transitions between frames. To address these challenges, we harness the generative capabilities of a fine-tuned latent diffusion model designed specifically for video colorization, introducing a novel solution for achieving temporal consistency in video colorization, as well as demonstrating strong improvements on established image quality metrics compared to other existing methods. Furthermore, we perform a subjective study, where users preferred our approach to the existing state of the art. Our dataset encompasses a combination of conventional datasets and videos from television/movies. In short, by leveraging the power of a fine-tuned latent diffusion-based colorization system with a temporal consistency mechanism, we can improve the performance of automatic video colorization by addressing the challenges of temporal inconsistency. A short demonstration of our results can be seen in some example videos available at https://youtu.be/vDbzsZdFuxM.
A lightweight 3D dense facial landmark estimation model from position map data
Aug 29, 2023



The incorporation of 3D data in facial analysis tasks has gained popularity in recent years. Though it provides a more accurate and detailed representation of the human face, accruing 3D face data is more complex and expensive than 2D face images. Either one has to rely on expensive 3D scanners or depth sensors which are prone to noise. An alternative option is the reconstruction of 3D faces from uncalibrated 2D images in an unsupervised way without any ground truth 3D data. However, such approaches are computationally expensive and the learned model size is not suitable for mobile or other edge device applications. Predicting dense 3D landmarks over the whole face can overcome this issue. As there is no public dataset available containing dense landmarks, we propose a pipeline to create a dense keypoint training dataset containing 520 key points across the whole face from an existing facial position map data. We train a lightweight MobileNet-based regressor model with the generated data. As we do not have access to any evaluation dataset with dense landmarks in it we evaluate our model against the 68 keypoint detection task. Experimental results show that our trained model outperforms many of the existing methods in spite of its lower model size and minimal computational cost. Also, the qualitative evaluation shows the efficiency of our trained models in extreme head pose angles as well as other facial variations and occlusions.
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model
Jan 12, 2023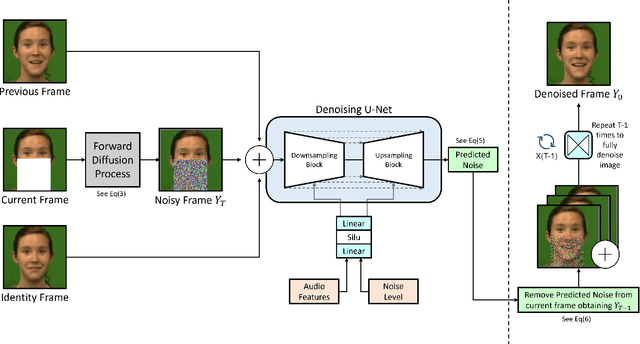
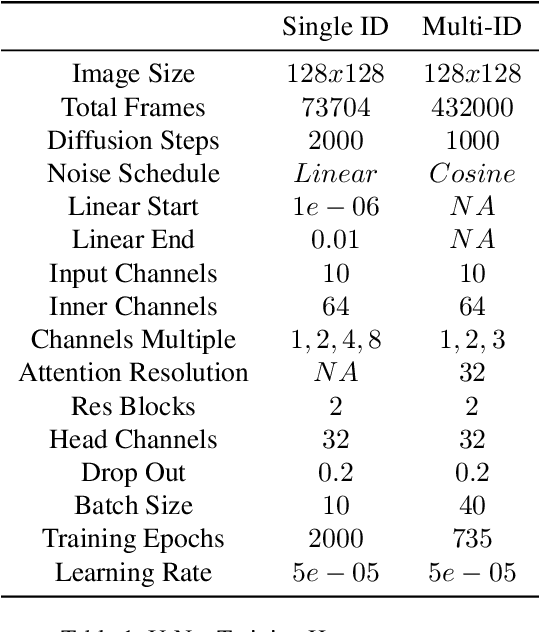


In this paper we propose a method for end-to-end speech driven video editing using a denoising diffusion model. Given a video of a person speaking, we aim to re-synchronise the lip and jaw motion of the person in response to a separate auditory speech recording without relying on intermediate structural representations such as facial landmarks or a 3D face model. We show this is possible by conditioning a denoising diffusion model with audio spectral features to generate synchronised facial motion. We achieve convincing results on the task of unstructured single-speaker video editing, achieving a word error rate of 45% using an off the shelf lip reading model. We further demonstrate how our approach can be extended to the multi-speaker domain. To our knowledge, this is the first work to explore the feasibility of applying denoising diffusion models to the task of audio-driven video editing.
Methodology for Building Synthetic Datasets with Virtual Humans
Jun 21, 2020


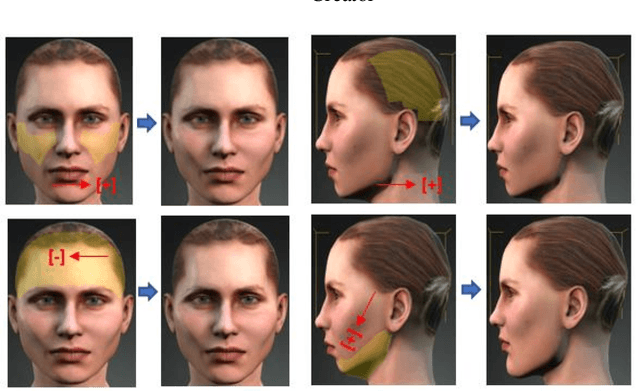
Recent advances in deep learning methods have increased the performance of face detection and recognition systems. The accuracy of these models relies on the range of variation provided in the training data. Creating a dataset that represents all variations of real-world faces is not feasible as the control over the quality of the data decreases with the size of the dataset. Repeatability of data is another challenge as it is not possible to exactly recreate 'real-world' acquisition conditions outside of the laboratory. In this work, we explore a framework to synthetically generate facial data to be used as part of a toolchain to generate very large facial datasets with a high degree of control over facial and environmental variations. Such large datasets can be used for improved, targeted training of deep neural networks. In particular, we make use of a 3D morphable face model for the rendering of multiple 2D images across a dataset of 100 synthetic identities, providing full control over image variations such as pose, illumination, and background.