 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Auralization for First-Person Vocal Interaction in Immersive Virtual Environments
Apr 05, 2025Multimodal research and applications are becoming more commonplace as Virtual Reality (VR) technology integrates different sensory feedback, enabling the recreation of real spaces in an audio-visual context. Within VR experiences, numerous applications rely on the user's voice as a key element of interaction, including music performances and public speaking applications. Self-perception of our voice plays a crucial role in vocal production. When singing or speaking, our voice interacts with the acoustic properties of the environment, shaping the adjustment of vocal parameters in response to the perceived characteristics of the space. This technical report presents a real-time auralization pipeline that leverages three-dimensional Spatial Impulse Responses (SIRs) for multimodal research applications in VR requiring first-person vocal interaction. It describes the impulse response creation and rendering workflow, the audio-visual integration, and addresses latency and computational considerations. The system enables users to explore acoustic spaces from various positions and orientations within a predefined area, supporting three and five Degrees of Freedom (3Dof and 5DoF) in audio-visual multimodal perception for both research and creative applications in VR.
Towards a GENEA Leaderboard -- an Extended, Living Benchmark for Evaluating and Advancing Conversational Motion Synthesis
Oct 08, 2024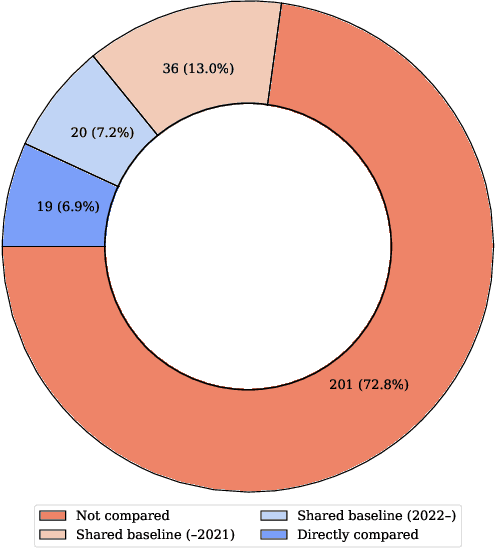

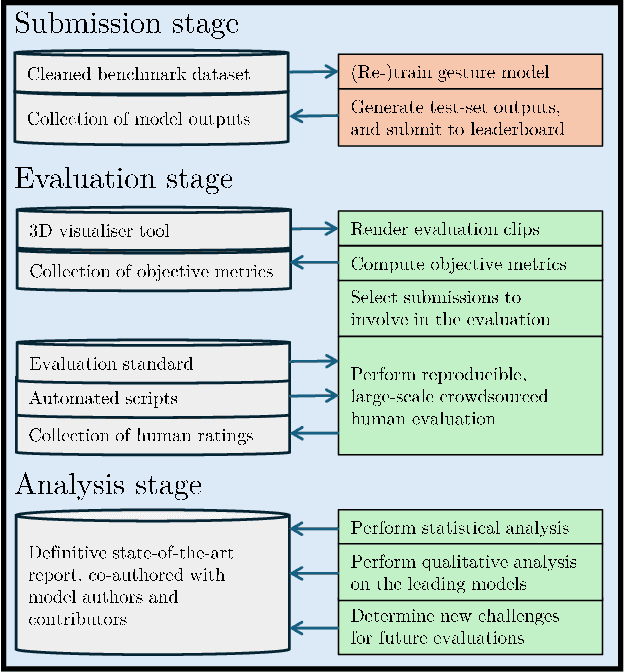

Current evaluation practices in speech-driven gesture generation lack standardisation and focus on aspects that are easy to measure over aspects that actually matter. This leads to a situation where it is impossible to know what is the state of the art, or to know which method works better for which purpose when comparing two publications. In this position paper, we review and give details on issues with existing gesture-generation evaluation, and present a novel proposal for remedying them. Specifically, we announce an upcoming living leaderboard to benchmark progress in conversational motion synthesis. Unlike earlier gesture-generation challenges, the leaderboard will be updated with large-scale user studies of new gesture-generation systems multiple times per year, and systems on the leaderboard can be submitted to any publication venue that their authors prefer. By evolving the leaderboard evaluation data and tasks over time, the effort can keep driving progress towards the most important end goals identified by the community. We actively seek community involvement across the entire evaluation pipeline: from data and tasks for the evaluation, via tooling, to the systems evaluated. In other words, our proposal will not only make it easier for researchers to perform good evaluations, but their collective input and contributions will also help drive the future of gesture-generation research.
A lightweight 3D dense facial landmark estimation model from position map data
Aug 29, 2023



The incorporation of 3D data in facial analysis tasks has gained popularity in recent years. Though it provides a more accurate and detailed representation of the human face, accruing 3D face data is more complex and expensive than 2D face images. Either one has to rely on expensive 3D scanners or depth sensors which are prone to noise. An alternative option is the reconstruction of 3D faces from uncalibrated 2D images in an unsupervised way without any ground truth 3D data. However, such approaches are computationally expensive and the learned model size is not suitable for mobile or other edge device applications. Predicting dense 3D landmarks over the whole face can overcome this issue. As there is no public dataset available containing dense landmarks, we propose a pipeline to create a dense keypoint training dataset containing 520 key points across the whole face from an existing facial position map data. We train a lightweight MobileNet-based regressor model with the generated data. As we do not have access to any evaluation dataset with dense landmarks in it we evaluate our model against the 68 keypoint detection task. Experimental results show that our trained model outperforms many of the existing methods in spite of its lower model size and minimal computational cost. Also, the qualitative evaluation shows the efficiency of our trained models in extreme head pose angles as well as other facial variations and occlusions.
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model
Jan 12, 2023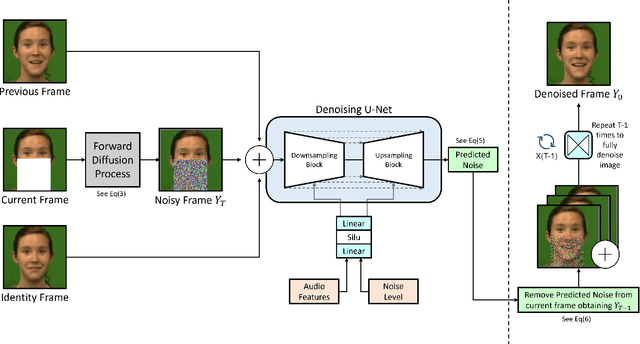
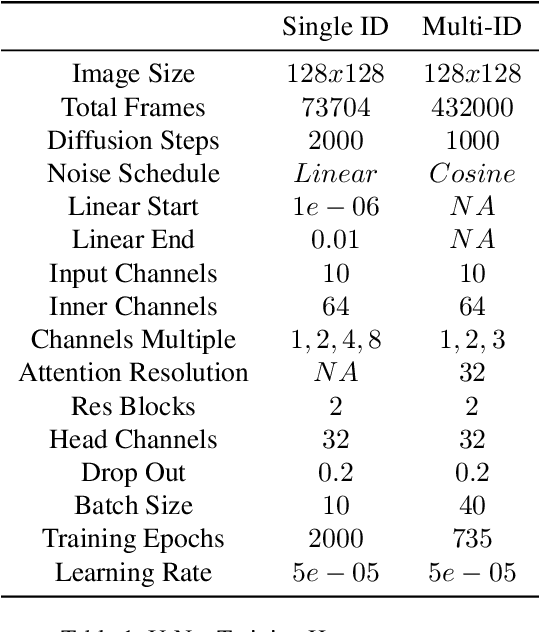


In this paper we propose a method for end-to-end speech driven video editing using a denoising diffusion model. Given a video of a person speaking, we aim to re-synchronise the lip and jaw motion of the person in response to a separate auditory speech recording without relying on intermediate structural representations such as facial landmarks or a 3D face model. We show this is possible by conditioning a denoising diffusion model with audio spectral features to generate synchronised facial motion. We achieve convincing results on the task of unstructured single-speaker video editing, achieving a word error rate of 45% using an off the shelf lip reading model. We further demonstrate how our approach can be extended to the multi-speaker domain. To our knowledge, this is the first work to explore the feasibility of applying denoising diffusion models to the task of audio-driven video editing.
Appearance
Oct 07, 2021
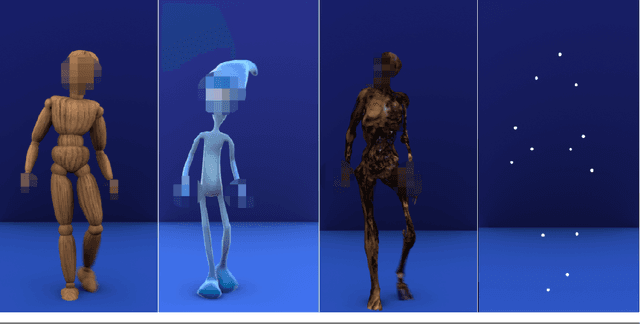

Socially interactive agents (SIAs) are no longer mere visions for future user interfaces, as 20 years of research and technology development has enabled the use of virtual and physical agents in day-to-day interfaces and environments. This chapter of the ACM "The Handbook on Socially Interactive Agents" reviews research on and technologies involving socially interactive agents, including virtually embodied agents and physically embodied robots, focusing particularly on the appearance of socially interactive agents. It covers the history of the development of these technologies; outlines the design space for the appearance of agents, including what appearance comprises, modalities in which agents are presented, and how agents are constructed; and the features that agents use to support social interaction, including facial and bodily features, those that express demographic characteristics, and issues surrounding realism, appeal, and the uncanny valley. The chapter concludes with a brief discussion of open questions surrounding the appearance of socially interactive agents.
* 38 pages, 16 figures, appears in the "The Handbook on Socially Interactive Agents: 20 Years of Research on Embodied Conversational Agents, Intelligent Virtual Agents, and Social Robotics Volume 1: Methods, Behavior, Cognition," published by the ACM
Understanding the Predictability of Gesture Parameters from Speech and their Perceptual Importance
Oct 02, 2020
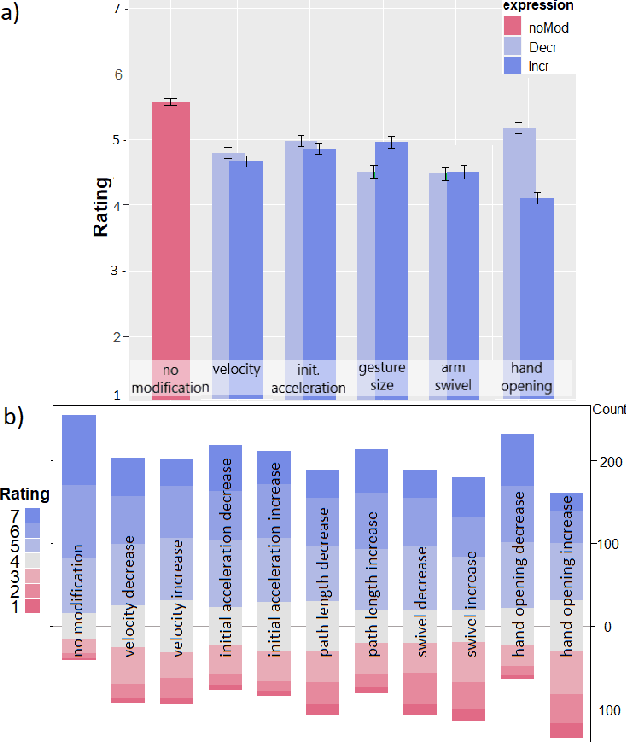
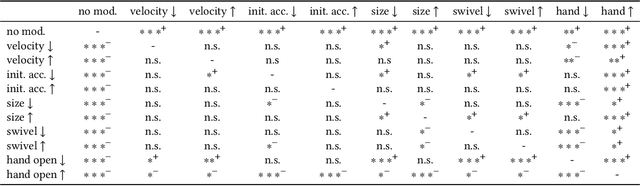
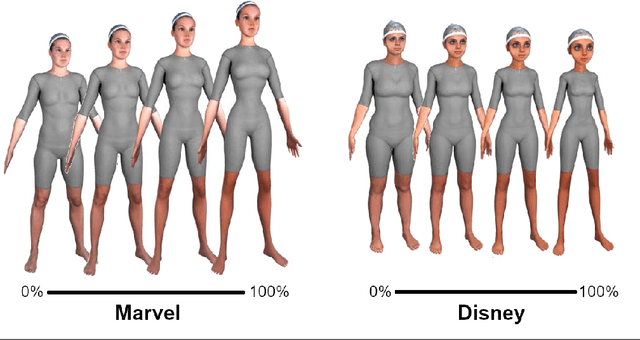
Gesture behavior is a natural part of human conversation. Much work has focused on removing the need for tedious hand-animation to create embodied conversational agents by designing speech-driven gesture generators. However, these generators often work in a black-box manner, assuming a general relationship between input speech and output motion. As their success remains limited, we investigate in more detail how speech may relate to different aspects of gesture motion. We determine a number of parameters characterizing gesture, such as speed and gesture size, and explore their relationship to the speech signal in a two-fold manner. First, we train multiple recurrent networks to predict the gesture parameters from speech to understand how well gesture attributes can be modeled from speech alone. We find that gesture parameters can be partially predicted from speech, and some parameters, such as path length, being predicted more accurately than others, like velocity. Second, we design a perceptual study to assess the importance of each gesture parameter for producing motion that people perceive as appropriate for the speech. Results show that a degradation in any parameter was viewed negatively, but some changes, such as hand shape, are more impactful than others. A video summarization can be found at https://youtu.be/aw6-_5kmLjY.
Methodology for Building Synthetic Datasets with Virtual Humans
Jun 21, 2020


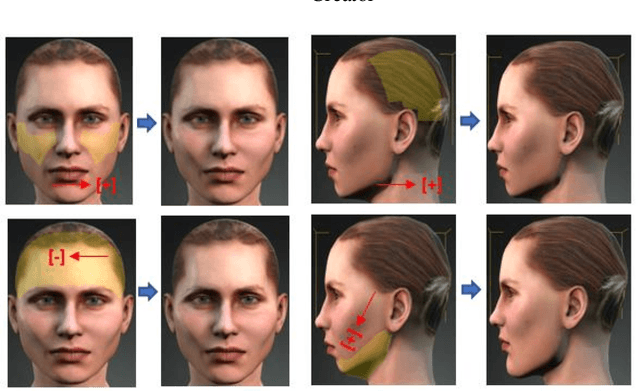
Recent advances in deep learning methods have increased the performance of face detection and recognition systems. The accuracy of these models relies on the range of variation provided in the training data. Creating a dataset that represents all variations of real-world faces is not feasible as the control over the quality of the data decreases with the size of the dataset. Repeatability of data is another challenge as it is not possible to exactly recreate 'real-world' acquisition conditions outside of the laboratory. In this work, we explore a framework to synthetically generate facial data to be used as part of a toolchain to generate very large facial datasets with a high degree of control over facial and environmental variations. Such large datasets can be used for improved, targeted training of deep neural networks. In particular, we make use of a 3D morphable face model for the rendering of multiple 2D images across a dataset of 100 synthetic identities, providing full control over image variations such as pose, illumination, and background.