 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a GENEA Leaderboard -- an Extended, Living Benchmark for Evaluating and Advancing Conversational Motion Synthesis
Oct 08, 2024

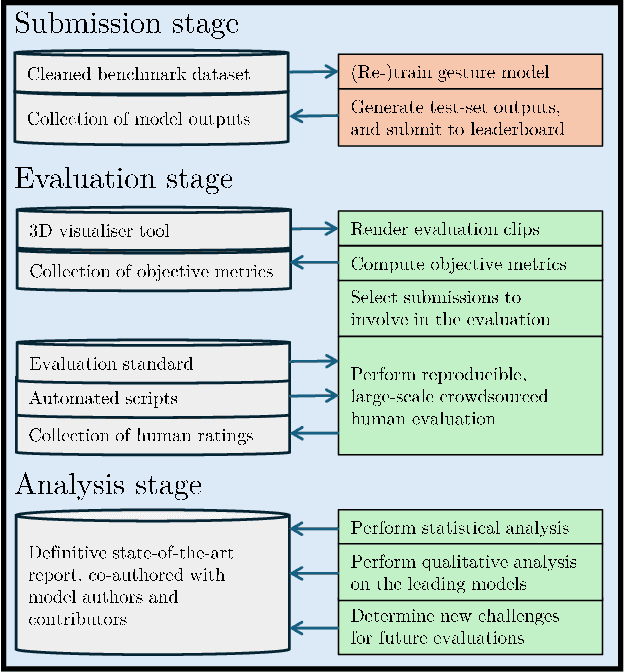

Current evaluation practices in speech-driven gesture generation lack standardisation and focus on aspects that are easy to measure over aspects that actually matter. This leads to a situation where it is impossible to know what is the state of the art, or to know which method works better for which purpose when comparing two publications. In this position paper, we review and give details on issues with existing gesture-generation evaluation, and present a novel proposal for remedying them. Specifically, we announce an upcoming living leaderboard to benchmark progress in conversational motion synthesis. Unlike earlier gesture-generation challenges, the leaderboard will be updated with large-scale user studies of new gesture-generation systems multiple times per year, and systems on the leaderboard can be submitted to any publication venue that their authors prefer. By evolving the leaderboard evaluation data and tasks over time, the effort can keep driving progress towards the most important end goals identified by the community. We actively seek community involvement across the entire evaluation pipeline: from data and tasks for the evaluation, via tooling, to the systems evaluated. In other words, our proposal will not only make it easier for researchers to perform good evaluations, but their collective input and contributions will also help drive the future of gesture-generation research.
AdaptNet: Policy Adaptation for Physics-Based Character Control
Oct 09, 2023
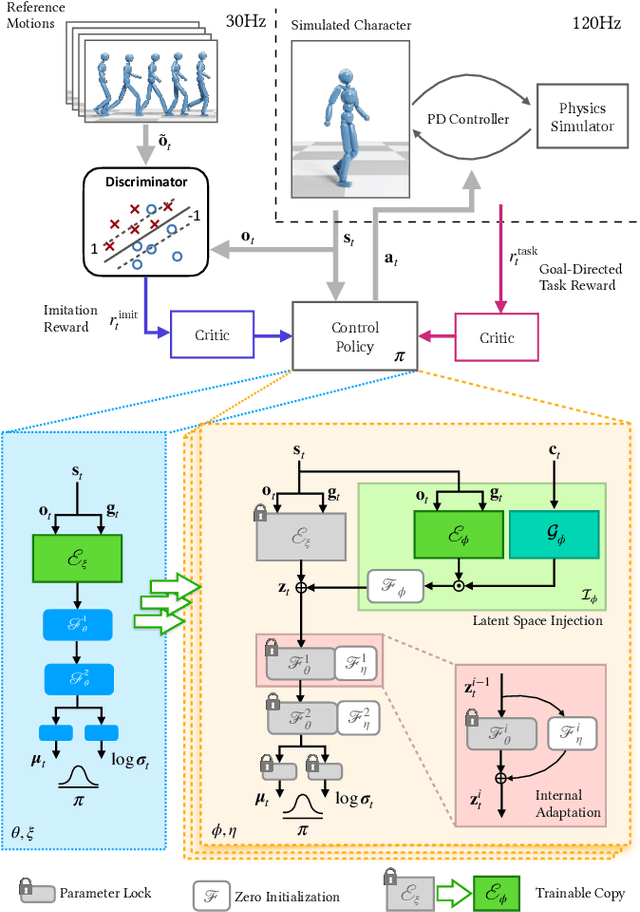
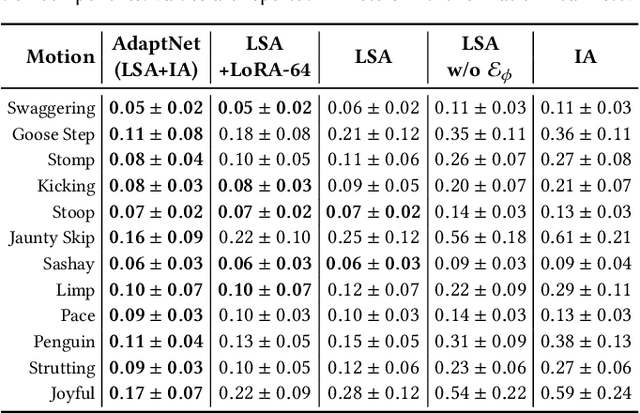
Motivated by humans' ability to adapt skills in the learning of new ones, this paper presents AdaptNet, an approach for modifying the latent space of existing policies to allow new behaviors to be quickly learned from like tasks in comparison to learning from scratch. Building on top of a given reinforcement learning controller, AdaptNet uses a two-tier hierarchy that augments the original state embedding to support modest changes in a behavior and further modifies the policy network layers to make more substantive changes. The technique is shown to be effective for adapting existing physics-based controllers to a wide range of new styles for locomotion, new task targets, changes in character morphology and extensive changes in environment. Furthermore, it exhibits significant increase in learning efficiency, as indicated by greatly reduced training times when compared to training from scratch or using other approaches that modify existing policies. Code is available at https://motion-lab.github.io/AdaptNet.
* SIGGRAPH Asia 2023. Video: https://youtu.be/WxmJSCNFb28. Website: https://motion-lab.github.io/AdaptNet, https://pei-xu.github.io/AdaptNet
A Comprehensive Review of Data-Driven Co-Speech Gesture Generation
Jan 13, 2023Gestures that accompany speech are an essential part of natural and efficient embodied human communication. The automatic generation of such co-speech gestures is a long-standing problem in computer animation and is considered an enabling technology in film, games, virtual social spaces, and for interaction with social robots. The problem is made challenging by the idiosyncratic and non-periodic nature of human co-speech gesture motion, and by the great diversity of communicative functions that gestures encompass. Gesture generation has seen surging interest recently, owing to the emergence of more and larger datasets of human gesture motion, combined with strides in deep-learning-based generative models, that benefit from the growing availability of data. This review article summarizes co-speech gesture generation research, with a particular focus on deep generative models. First, we articulate the theory describing human gesticulation and how it complements speech. Next, we briefly discuss rule-based and classical statistical gesture synthesis, before delving into deep learning approaches. We employ the choice of input modalities as an organizing principle, examining systems that generate gestures from audio, text, and non-linguistic input. We also chronicle the evolution of the related training data sets in terms of size, diversity, motion quality, and collection method. Finally, we identify key research challenges in gesture generation, including data availability and quality; producing human-like motion; grounding the gesture in the co-occurring speech in interaction with other speakers, and in the environment; performing gesture evaluation; and integration of gesture synthesis into applications. We highlight recent approaches to tackling the various key challenges, as well as the limitations of these approaches, and point toward areas of future development.
Multimodal analysis of the predictability of hand-gesture properties
Aug 12, 2021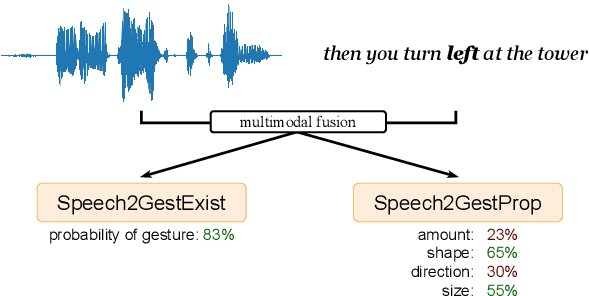
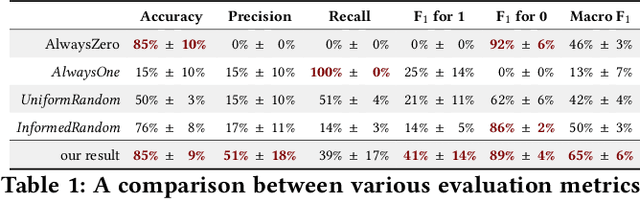
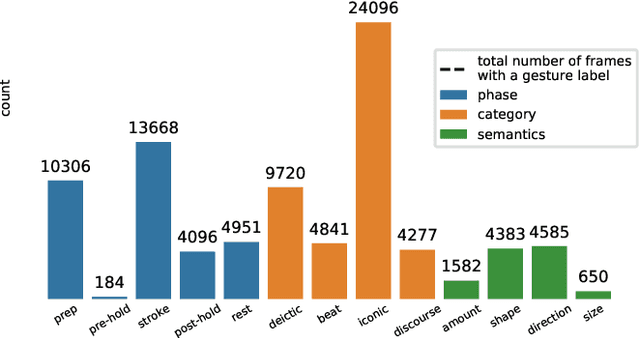
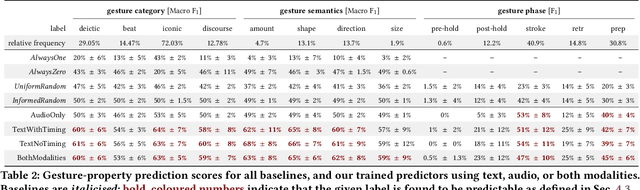
Embodied conversational agents benefit from being able to accompany their speech with gestures. Although many data-driven approaches to gesture generation have been proposed in recent years, it is still unclear whether such systems can consistently generate gestures that convey meaning. We investigate which gesture properties (phase, category, and semantics) can be predicted from speech text and/or audio using contemporary deep learning. In extensive experiments, we show that gesture properties related to gesture meaning (semantics and category) are predictable from text features (time-aligned BERT embeddings) alone, but not from prosodic audio features, while rhythm-related gesture properties (phase) on the other hand can be predicted from either audio, text (with word-level timing information), or both. These results are encouraging as they indicate that it is possible to equip an embodied agent with content-wise meaningful co-speech gestures using a machine-learning model.
Speech2Properties2Gestures: Gesture-Property Prediction as a Tool for Generating Representational Gestures from Speech
Jun 28, 2021
We propose a new framework for gesture generation, aiming to allow data-driven approaches to produce more semantically rich gestures. Our approach first predicts whether to gesture, followed by a prediction of the gesture properties. Those properties are then used as conditioning for a modern probabilistic gesture-generation model capable of high-quality output. This empowers the approach to generate gestures that are both diverse and representational.
Understanding the Predictability of Gesture Parameters from Speech and their Perceptual Importance
Oct 02, 2020
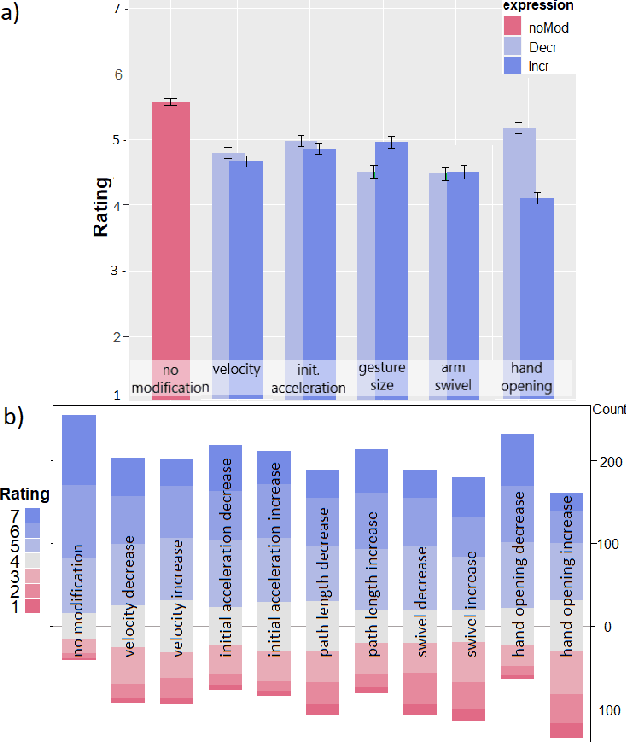
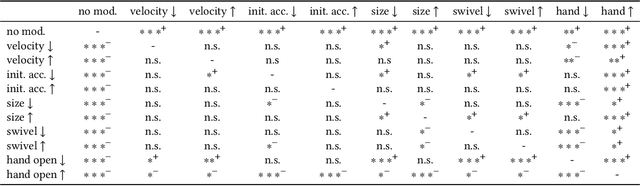
Gesture behavior is a natural part of human conversation. Much work has focused on removing the need for tedious hand-animation to create embodied conversational agents by designing speech-driven gesture generators. However, these generators often work in a black-box manner, assuming a general relationship between input speech and output motion. As their success remains limited, we investigate in more detail how speech may relate to different aspects of gesture motion. We determine a number of parameters characterizing gesture, such as speed and gesture size, and explore their relationship to the speech signal in a two-fold manner. First, we train multiple recurrent networks to predict the gesture parameters from speech to understand how well gesture attributes can be modeled from speech alone. We find that gesture parameters can be partially predicted from speech, and some parameters, such as path length, being predicted more accurately than others, like velocity. Second, we design a perceptual study to assess the importance of each gesture parameter for producing motion that people perceive as appropriate for the speech. Results show that a degradation in any parameter was viewed negatively, but some changes, such as hand shape, are more impactful than others. A video summarization can be found at https://youtu.be/aw6-_5kmLjY.
Storytelling Agents with Personality and Adaptivity
Sep 04, 2017
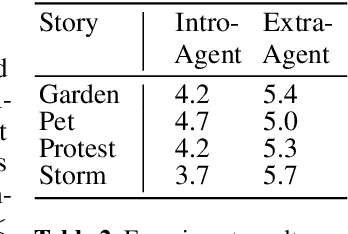
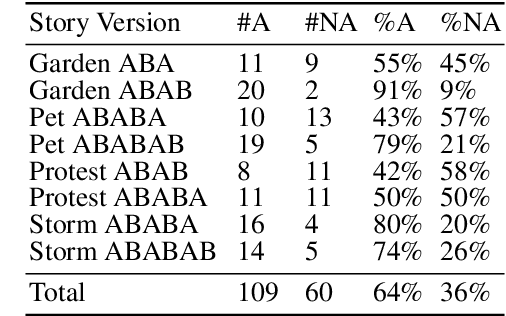

We explore the expression of personality and adaptivity through the gestures of virtual agents in a storytelling task. We conduct two experiments using four different dialogic stories. We manipulate agent personality on the extraversion scale, whether the agents adapt to one another in their gestural performance and agent gender. Our results show that subjects are able to perceive the intended variation in extraversion between different virtual agents, independently of the story they are telling and the gender of the agent. A second study shows that subjects also prefer adaptive to nonadaptive virtual agents.
* Related dataset: https://nlds.soe.ucsc.edu/sdg