 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak Your Mind: The Speech Continuation Task as a Probe of Voice-Based Model Bias
Sep 26, 2025Speech Continuation (SC) is the task of generating a coherent extension of a spoken prompt while preserving both semantic context and speaker identity. Because SC is constrained to a single audio stream, it offers a more direct setting for probing biases in speech foundation models than dialogue does. In this work we present the first systematic evaluation of bias in SC, investigating how gender and phonation type (breathy, creaky, end-creak) affect continuation behaviour. We evaluate three recent models: SpiritLM (base and expressive), VAE-GSLM, and SpeechGPT across speaker similarity, voice quality preservation, and text-based bias metrics. Results show that while both speaker similarity and coherence remain a challenge, textual evaluations reveal significant model and gender interactions: once coherence is sufficiently high (for VAE-GSLM), gender effects emerge on text-metrics such as agency and sentence polarity. In addition, continuations revert toward modal phonation more strongly for female prompts than for male ones, revealing a systematic voice-quality bias. These findings highlight SC as a controlled probe of socially relevant representational biases in speech foundation models, and suggest that it will become an increasingly informative diagnostic as continuation quality improves.
VoXtream: Full-Stream Text-to-Speech with Extremely Low Latency
Sep 19, 2025We present VoXtream, a fully autoregressive, zero-shot streaming text-to-speech (TTS) system for real-time use that begins speaking from the first word. VoXtream directly maps incoming phonemes to audio tokens using a monotonic alignment scheme and a dynamic look-ahead that does not delay onset. Built around an incremental phoneme transformer, a temporal transformer predicting semantic and duration tokens, and a depth transformer producing acoustic tokens, VoXtream achieves, to our knowledge, the lowest initial delay among publicly available streaming TTS: 102 ms on GPU. Despite being trained on a mid-scale 9k-hour corpus, it matches or surpasses larger baselines on several metrics, while delivering competitive quality in both output- and full-streaming settings. Demo and code are available at https://herimor.github.io/voxtream.
EmojiVoice: Towards long-term controllable expressivity in robot speech
Jun 18, 2025Humans vary their expressivity when speaking for extended periods to maintain engagement with their listener. Although social robots tend to be deployed with ``expressive'' joyful voices, they lack this long-term variation found in human speech. Foundation model text-to-speech systems are beginning to mimic the expressivity in human speech, but they are difficult to deploy offline on robots. We present EmojiVoice, a free, customizable text-to-speech (TTS) toolkit that allows social roboticists to build temporally variable, expressive speech on social robots. We introduce emoji-prompting to allow fine-grained control of expressivity on a phase level and use the lightweight Matcha-TTS backbone to generate speech in real-time. We explore three case studies: (1) a scripted conversation with a robot assistant, (2) a storytelling robot, and (3) an autonomous speech-to-speech interactive agent. We found that using varied emoji prompting improved the perception and expressivity of speech over a long period in a storytelling task, but expressive voice was not preferred in the assistant use case.
CARL-GT: Evaluating Causal Reasoning Capabilities of Large Language Models
Dec 23, 2024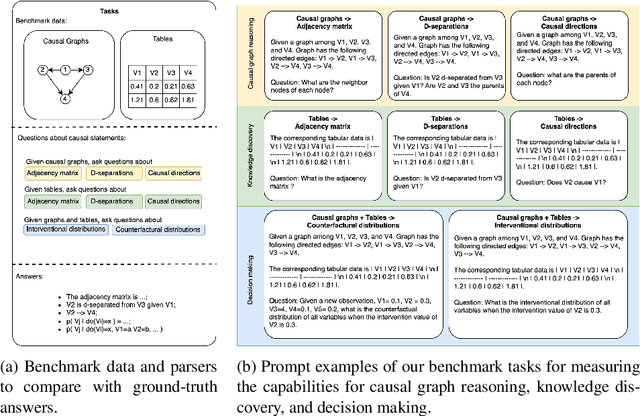


Causal reasoning capabilities are essential for large language models (LLMs) in a wide range of applications, such as education and healthcare. But there is still a lack of benchmarks for a better understanding of such capabilities. Current LLM benchmarks are mainly based on conversational tasks, academic math tests, and coding tests. Such benchmarks evaluate LLMs in well-regularized settings, but they are limited in assessing the skills and abilities to solve real-world problems. In this work, we provide a benchmark, named by CARL-GT, which evaluates CAusal Reasoning capabilities of large Language models using Graphs and Tabular data. The benchmark has a diverse range of tasks for evaluating LLMs from causal graph reasoning, knowledge discovery, and decision-making aspects. In addition, effective zero-shot learning prompts are developed for the tasks. In our experiments, we leverage the benchmark for evaluating open-source LLMs and provide a detailed comparison of LLMs for causal reasoning abilities. We found that LLMs are still weak in casual reasoning, especially with tabular data to discover new insights. Furthermore, we investigate and discuss the relationships of different benchmark tasks by analyzing the performance of LLMs. The experimental results show that LLMs have different strength over different tasks and that their performance on tasks in different categories, i.e., causal graph reasoning, knowledge discovery, and decision-making, shows stronger correlation than tasks in the same category.
Towards a GENEA Leaderboard -- an Extended, Living Benchmark for Evaluating and Advancing Conversational Motion Synthesis
Oct 08, 2024

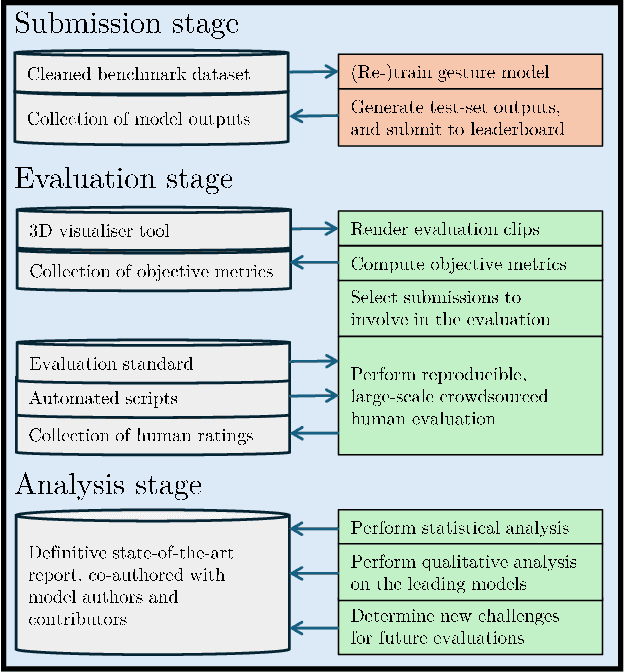

Current evaluation practices in speech-driven gesture generation lack standardisation and focus on aspects that are easy to measure over aspects that actually matter. This leads to a situation where it is impossible to know what is the state of the art, or to know which method works better for which purpose when comparing two publications. In this position paper, we review and give details on issues with existing gesture-generation evaluation, and present a novel proposal for remedying them. Specifically, we announce an upcoming living leaderboard to benchmark progress in conversational motion synthesis. Unlike earlier gesture-generation challenges, the leaderboard will be updated with large-scale user studies of new gesture-generation systems multiple times per year, and systems on the leaderboard can be submitted to any publication venue that their authors prefer. By evolving the leaderboard evaluation data and tasks over time, the effort can keep driving progress towards the most important end goals identified by the community. We actively seek community involvement across the entire evaluation pipeline: from data and tasks for the evaluation, via tooling, to the systems evaluated. In other words, our proposal will not only make it easier for researchers to perform good evaluations, but their collective input and contributions will also help drive the future of gesture-generation research.
Causality for Tabular Data Synthesis: A High-Order Structure Causal Benchmark Framework
Jun 12, 2024Tabular synthesis models remain ineffective at capturing complex dependencies, and the quality of synthetic data is still insufficient for comprehensive downstream tasks, such as prediction under distribution shifts, automated decision-making, and cross-table understanding. A major challenge is the lack of prior knowledge about underlying structures and high-order relationships in tabular data. We argue that a systematic evaluation on high-order structural information for tabular data synthesis is the first step towards solving the problem. In this paper, we introduce high-order structural causal information as natural prior knowledge and provide a benchmark framework for the evaluation of tabular synthesis models. The framework allows us to generate benchmark datasets with a flexible range of data generation processes and to train tabular synthesis models using these datasets for further evaluation. We propose multiple benchmark tasks, high-order metrics, and causal inference tasks as downstream tasks for evaluating the quality of synthetic data generated by the trained models. Our experiments demonstrate to leverage the benchmark framework for evaluating the model capability of capturing high-order structural causal information. Furthermore, our benchmarking results provide an initial assessment of state-of-the-art tabular synthesis models. They have clearly revealed significant gaps between ideal and actual performance and how baseline methods differ. Our benchmark framework is available at URL https://github.com/TURuibo/CauTabBench.
Should you use a probabilistic duration model in TTS? Probably! Especially for spontaneous speech
Jun 08, 2024Converting input symbols to output audio in TTS requires modelling the durations of speech sounds. Leading non-autoregressive (NAR) TTS models treat duration modelling as a regression problem. The same utterance is then spoken with identical timings every time, unlike when a human speaks. Probabilistic models of duration have been proposed, but there is mixed evidence of their benefits. However, prior studies generally only consider speech read aloud, and ignore spontaneous speech, despite the latter being both a more common and a more variable mode of speaking. We compare the effect of conventional deterministic duration modelling to durations sampled from a powerful probabilistic model based on conditional flow matching (OT-CFM), in three different NAR TTS approaches: regression-based, deep generative, and end-to-end. Across four different corpora, stochastic duration modelling improves probabilistic NAR TTS approaches, especially for spontaneous speech. Please see https://shivammehta25.github.io/prob_dur/ for audio and resources.
Fake it to make it: Using synthetic data to remedy the data shortage in joint multimodal speech-and-gesture synthesis
Apr 30, 2024Although humans engaged in face-to-face conversation simultaneously communicate both verbally and non-verbally, methods for joint and unified synthesis of speech audio and co-speech 3D gesture motion from text are a new and emerging field. These technologies hold great promise for more human-like, efficient, expressive, and robust synthetic communication, but are currently held back by the lack of suitably large datasets, as existing methods are trained on parallel data from all constituent modalities. Inspired by student-teacher methods, we propose a straightforward solution to the data shortage, by simply synthesising additional training material. Specifically, we use unimodal synthesis models trained on large datasets to create multimodal (but synthetic) parallel training data, and then pre-train a joint synthesis model on that material. In addition, we propose a new synthesis architecture that adds better and more controllable prosody modelling to the state-of-the-art method in the field. Our results confirm that pre-training on large amounts of synthetic data improves the quality of both the speech and the motion synthesised by the multimodal model, with the proposed architecture yielding further benefits when pre-trained on the synthetic data. See https://shivammehta25.github.io/MAGI/ for example output.
Exploring Internal Numeracy in Language Models: A Case Study on ALBERT
Apr 25, 2024



It has been found that Transformer-based language models have the ability to perform basic quantitative reasoning. In this paper, we propose a method for studying how these models internally represent numerical data, and use our proposal to analyze the ALBERT family of language models. Specifically, we extract the learned embeddings these models use to represent tokens that correspond to numbers and ordinals, and subject these embeddings to Principal Component Analysis (PCA). PCA results reveal that ALBERT models of different sizes, trained and initialized separately, consistently learn to use the axes of greatest variation to represent the approximate ordering of various numerical concepts. Numerals and their textual counterparts are represented in separate clusters, but increase along the same direction in 2D space. Our findings illustrate that language models, trained purely to model text, can intuit basic mathematical concepts, opening avenues for NLP applications that intersect with quantitative reasoning.
Unified speech and gesture synthesis using flow matching
Oct 08, 2023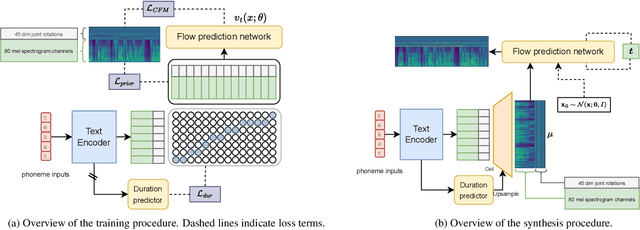
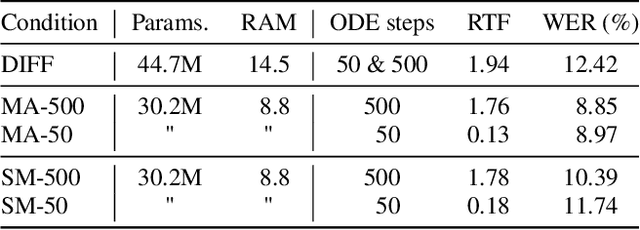
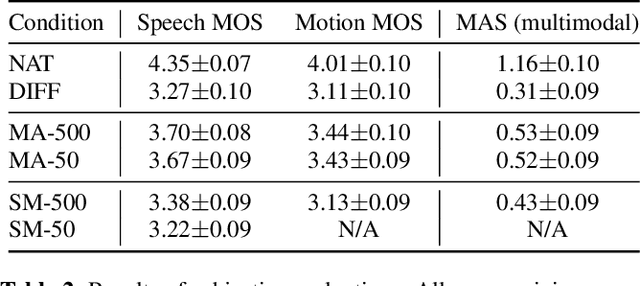
As text-to-speech technologies achieve remarkable naturalness in read-aloud tasks, there is growing interest in multimodal synthesis of verbal and non-verbal communicative behaviour, such as spontaneous speech and associated body gestures. This paper presents a novel, unified architecture for jointly synthesising speech acoustics and skeleton-based 3D gesture motion from text, trained using optimal-transport conditional flow matching (OT-CFM). The proposed architecture is simpler than the previous state of the art, has a smaller memory footprint, and can capture the joint distribution of speech and gestures, generating both modalities together in one single process. The new training regime, meanwhile, enables better synthesis quality in much fewer steps (network evaluations) than before. Uni- and multimodal subjective tests demonstrate improved speech naturalness, gesture human-likeness, and cross-modal appropriateness compared to existing benchmarks.