 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Context-Aware Human-like Pointing Gestures with RL Motion Imitation
Sep 16, 2025Pointing is a key mode of interaction with robots, yet most prior work has focused on recognition rather than generation. We present a motion capture dataset of human pointing gestures covering diverse styles, handedness, and spatial targets. Using reinforcement learning with motion imitation, we train policies that reproduce human-like pointing while maximizing precision. Results show our approach enables context-aware pointing behaviors in simulation, balancing task performance with natural dynamics.
Learning to Generate Pointing Gestures in Situated Embodied Conversational Agents
Sep 15, 2025

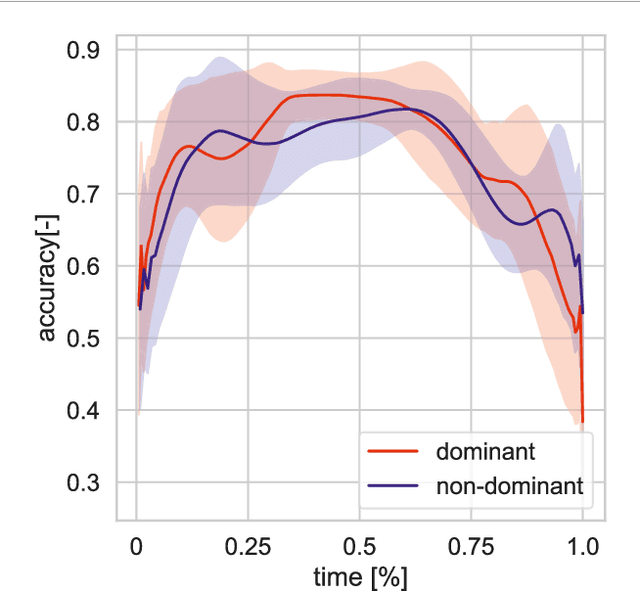

One of the main goals of robotics and intelligent agent research is to enable natural communication with humans in physically situated settings. While recent work has focused on verbal modes such as language and speech, non-verbal communication is crucial for flexible interaction. We present a framework for generating pointing gestures in embodied agents by combining imitation and reinforcement learning. Using a small motion capture dataset, our method learns a motor control policy that produces physically valid, naturalistic gestures with high referential accuracy. We evaluate the approach against supervised learning and retrieval baselines in both objective metrics and a virtual reality referential game with human users. Results show that our system achieves higher naturalness and accuracy than state-of-the-art supervised models, highlighting the promise of imitation-RL for communicative gesture generation and its potential application to robots.
* DOI: 10.3389/frobt.2023.1110534. This is the author's LaTeX version
Incorporating Spatial Awareness in Data-Driven Gesture Generation for Virtual Agents
Aug 07, 2024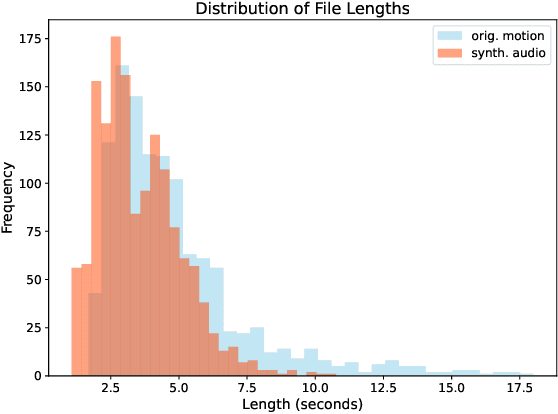
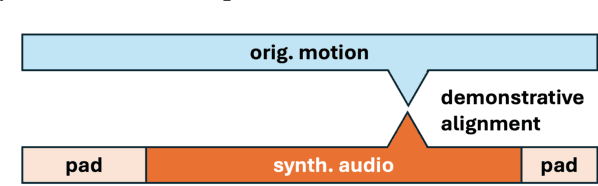
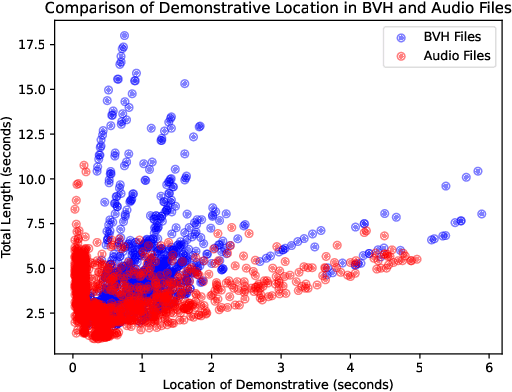

This paper focuses on enhancing human-agent communication by integrating spatial context into virtual agents' non-verbal behaviors, specifically gestures. Recent advances in co-speech gesture generation have primarily utilized data-driven methods, which create natural motion but limit the scope of gestures to those performed in a void. Our work aims to extend these methods by enabling generative models to incorporate scene information into speech-driven gesture synthesis. We introduce a novel synthetic gesture dataset tailored for this purpose. This development represents a critical step toward creating embodied conversational agents that interact more naturally with their environment and users.
Fake it to make it: Using synthetic data to remedy the data shortage in joint multimodal speech-and-gesture synthesis
Apr 30, 2024Although humans engaged in face-to-face conversation simultaneously communicate both verbally and non-verbally, methods for joint and unified synthesis of speech audio and co-speech 3D gesture motion from text are a new and emerging field. These technologies hold great promise for more human-like, efficient, expressive, and robust synthetic communication, but are currently held back by the lack of suitably large datasets, as existing methods are trained on parallel data from all constituent modalities. Inspired by student-teacher methods, we propose a straightforward solution to the data shortage, by simply synthesising additional training material. Specifically, we use unimodal synthesis models trained on large datasets to create multimodal (but synthetic) parallel training data, and then pre-train a joint synthesis model on that material. In addition, we propose a new synthesis architecture that adds better and more controllable prosody modelling to the state-of-the-art method in the field. Our results confirm that pre-training on large amounts of synthetic data improves the quality of both the speech and the motion synthesised by the multimodal model, with the proposed architecture yielding further benefits when pre-trained on the synthetic data. See https://shivammehta25.github.io/MAGI/ for example output.
Unified speech and gesture synthesis using flow matching
Oct 08, 2023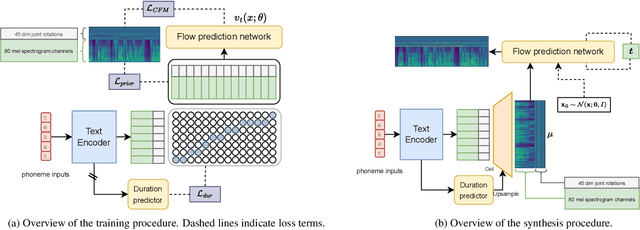
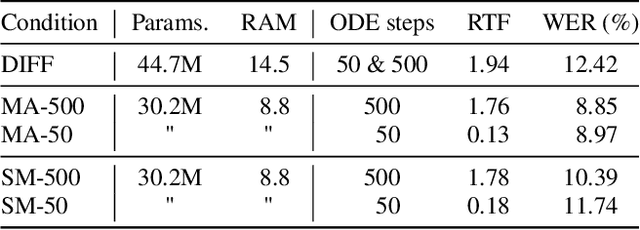
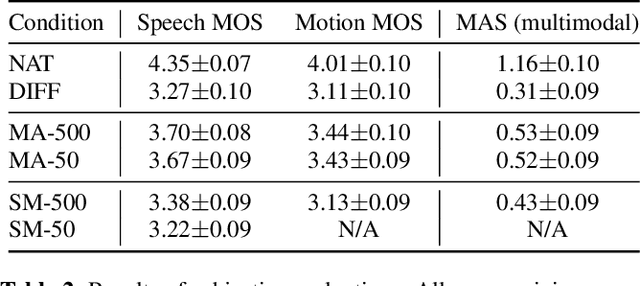
As text-to-speech technologies achieve remarkable naturalness in read-aloud tasks, there is growing interest in multimodal synthesis of verbal and non-verbal communicative behaviour, such as spontaneous speech and associated body gestures. This paper presents a novel, unified architecture for jointly synthesising speech acoustics and skeleton-based 3D gesture motion from text, trained using optimal-transport conditional flow matching (OT-CFM). The proposed architecture is simpler than the previous state of the art, has a smaller memory footprint, and can capture the joint distribution of speech and gestures, generating both modalities together in one single process. The new training regime, meanwhile, enables better synthesis quality in much fewer steps (network evaluations) than before. Uni- and multimodal subjective tests demonstrate improved speech naturalness, gesture human-likeness, and cross-modal appropriateness compared to existing benchmarks.
Diffusion-Based Co-Speech Gesture Generation Using Joint Text and Audio Representation
Sep 11, 2023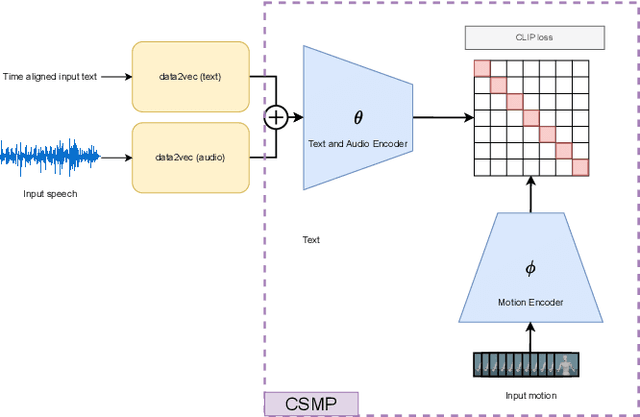
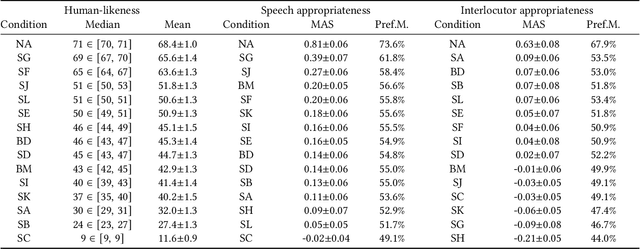
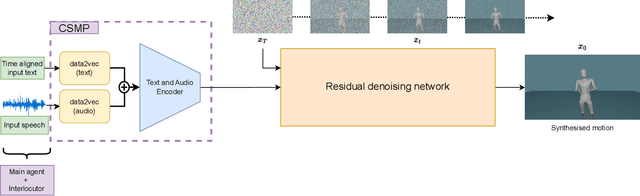
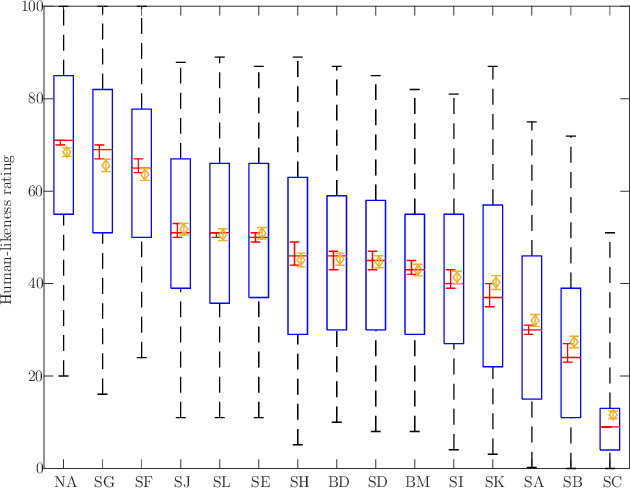
This paper describes a system developed for the GENEA (Generation and Evaluation of Non-verbal Behaviour for Embodied Agents) Challenge 2023. Our solution builds on an existing diffusion-based motion synthesis model. We propose a contrastive speech and motion pretraining (CSMP) module, which learns a joint embedding for speech and gesture with the aim to learn a semantic coupling between these modalities. The output of the CSMP module is used as a conditioning signal in the diffusion-based gesture synthesis model in order to achieve semantically-aware co-speech gesture generation. Our entry achieved highest human-likeness and highest speech appropriateness rating among the submitted entries. This indicates that our system is a promising approach to achieve human-like co-speech gestures in agents that carry semantic meaning.
Diff-TTSG: Denoising probabilistic integrated speech and gesture synthesis
Jun 15, 2023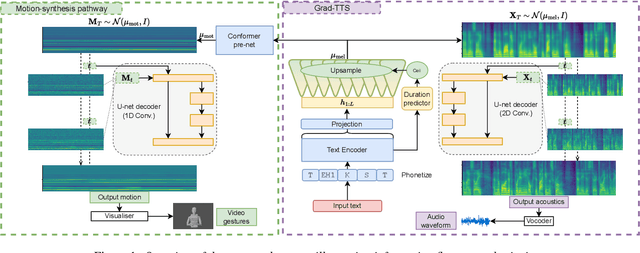

With read-aloud speech synthesis achieving high naturalness scores, there is a growing research interest in synthesising spontaneous speech. However, human spontaneous face-to-face conversation has both spoken and non-verbal aspects (here, co-speech gestures). Only recently has research begun to explore the benefits of jointly synthesising these two modalities in a single system. The previous state of the art used non-probabilistic methods, which fail to capture the variability of human speech and motion, and risk producing oversmoothing artefacts and sub-optimal synthesis quality. We present the first diffusion-based probabilistic model, called Diff-TTSG, that jointly learns to synthesise speech and gestures together. Our method can be trained on small datasets from scratch. Furthermore, we describe a set of careful uni- and multi-modal subjective tests for evaluating integrated speech and gesture synthesis systems, and use them to validate our proposed approach. For synthesised examples please see https://shivammehta25.github.io/Diff-TTSG
Listen, denoise, action! Audio-driven motion synthesis with diffusion models
Nov 17, 2022
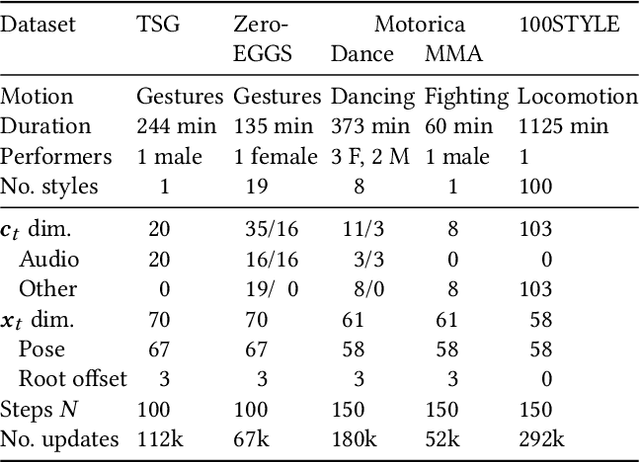
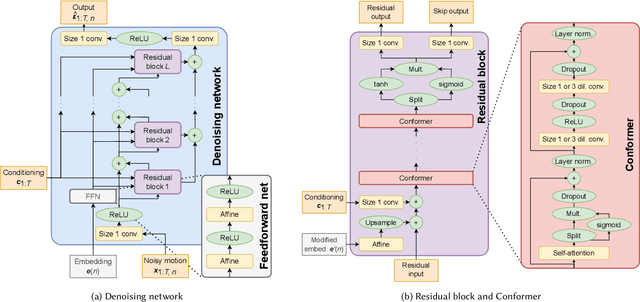
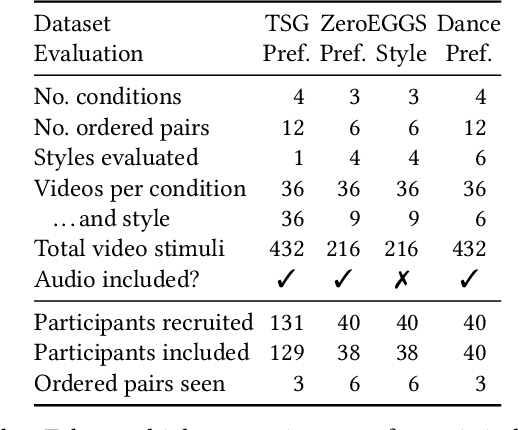
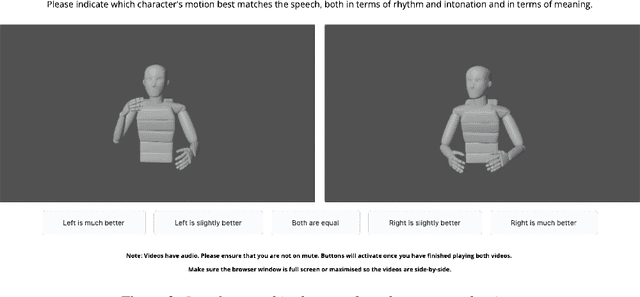
Diffusion models have experienced a surge of interest as highly expressive yet efficiently trainable probabilistic models. We show that these models are an excellent fit for synthesising human motion that co-occurs with audio, for example co-speech gesticulation, since motion is complex and highly ambiguous given audio, calling for a probabilistic description. Specifically, we adapt the DiffWave architecture to model 3D pose sequences, putting Conformers in place of dilated convolutions for improved accuracy. We also demonstrate control over motion style, using classifier-free guidance to adjust the strength of the stylistic expression. Gesture-generation experiments on the Trinity Speech-Gesture and ZeroEGGS datasets confirm that the proposed method achieves top-of-the-line motion quality, with distinctive styles whose expression can be made more or less pronounced. We also synthesise dance motion and path-driven locomotion using the same model architecture. Finally, we extend the guidance procedure to perform style interpolation in a manner that is appealing for synthesis tasks and has connections to product-of-experts models, a contribution we believe is of independent interest. Video examples are available at https://www.speech.kth.se/research/listen-denoise-action/
Integrated Speech and Gesture Synthesis
Aug 25, 2021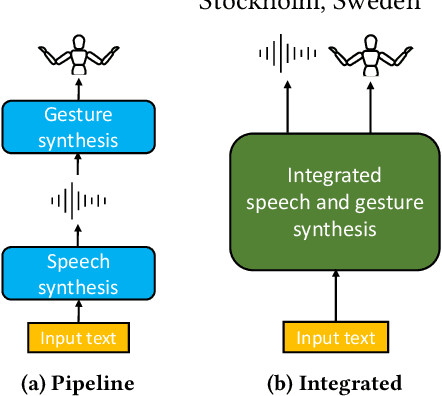

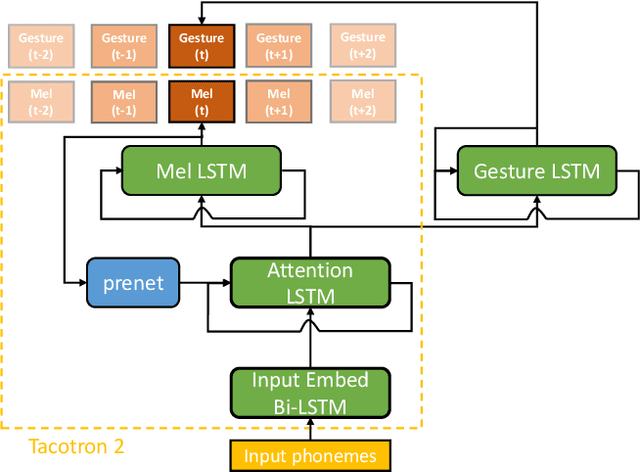
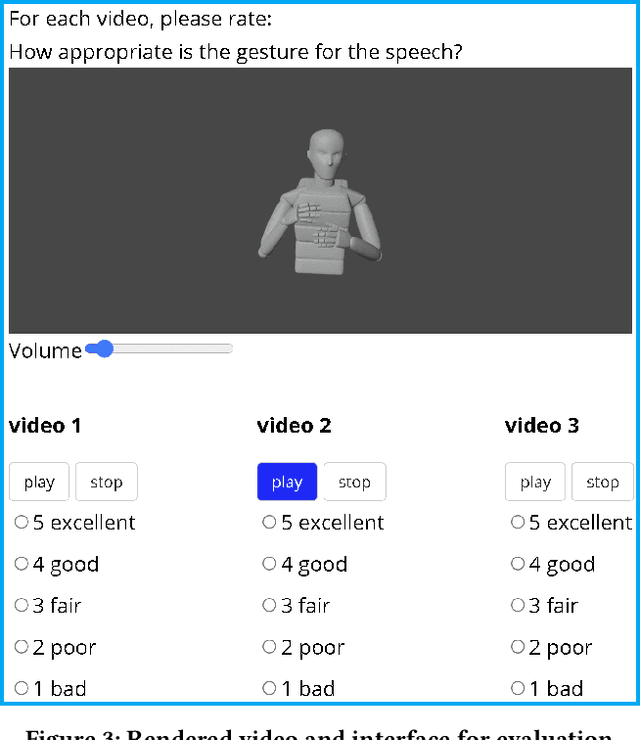
Text-to-speech and co-speech gesture synthesis have until now been treated as separate areas by two different research communities, and applications merely stack the two technologies using a simple system-level pipeline. This can lead to modeling inefficiencies and may introduce inconsistencies that limit the achievable naturalness. We propose to instead synthesize the two modalities in a single model, a new problem we call integrated speech and gesture synthesis (ISG). We also propose a set of models modified from state-of-the-art neural speech-synthesis engines to achieve this goal. We evaluate the models in three carefully-designed user studies, two of which evaluate the synthesized speech and gesture in isolation, plus a combined study that evaluates the models like they will be used in real-world applications -- speech and gesture presented together. The results show that participants rate one of the proposed integrated synthesis models as being as good as the state-of-the-art pipeline system we compare against, in all three tests. The model is able to achieve this with faster synthesis time and greatly reduced parameter count compared to the pipeline system, illustrating some of the potential benefits of treating speech and gesture synthesis together as a single, unified problem. Videos and code are available on our project page at https://swatsw.github.io/isg_icmi21/
Transflower: probabilistic autoregressive dance generation with multimodal attention
Jun 25, 2021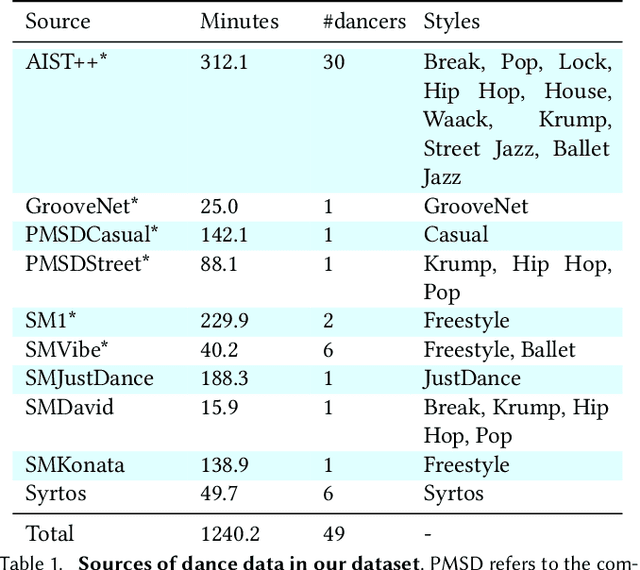
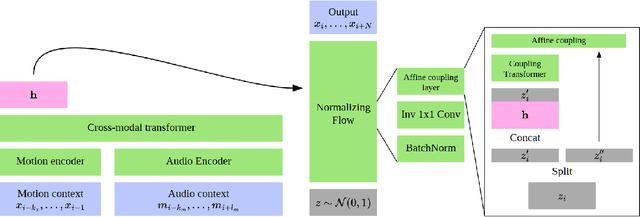
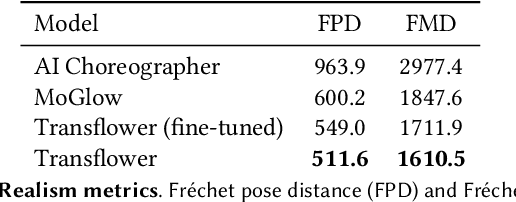

Dance requires skillful composition of complex movements that follow rhythmic, tonal and timbral features of music. Formally, generating dance conditioned on a piece of music can be expressed as a problem of modelling a high-dimensional continuous motion signal, conditioned on an audio signal. In this work we make two contributions to tackle this problem. First, we present a novel probabilistic autoregressive architecture that models the distribution over future poses with a normalizing flow conditioned on previous poses as well as music context, using a multimodal transformer encoder. Second, we introduce the currently largest 3D dance-motion dataset, obtained with a variety of motion-capture technologies, and including both professional and casual dancers. Using this dataset, we compare our new model against two baselines, via objective metrics and a user study, and show that both the ability to model a probability distribution, as well as being able to attend over a large motion and music context are necessary to produce interesting, diverse, and realistic dance that matches the music.