 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmojiVoice: Towards long-term controllable expressivity in robot speech
Jun 18, 2025Humans vary their expressivity when speaking for extended periods to maintain engagement with their listener. Although social robots tend to be deployed with ``expressive'' joyful voices, they lack this long-term variation found in human speech. Foundation model text-to-speech systems are beginning to mimic the expressivity in human speech, but they are difficult to deploy offline on robots. We present EmojiVoice, a free, customizable text-to-speech (TTS) toolkit that allows social roboticists to build temporally variable, expressive speech on social robots. We introduce emoji-prompting to allow fine-grained control of expressivity on a phase level and use the lightweight Matcha-TTS backbone to generate speech in real-time. We explore three case studies: (1) a scripted conversation with a robot assistant, (2) a storytelling robot, and (3) an autonomous speech-to-speech interactive agent. We found that using varied emoji prompting improved the perception and expressivity of speech over a long period in a storytelling task, but expressive voice was not preferred in the assistant use case.
Make Some Noise: Towards LLM audio reasoning and generation using sound tokens
Mar 28, 2025
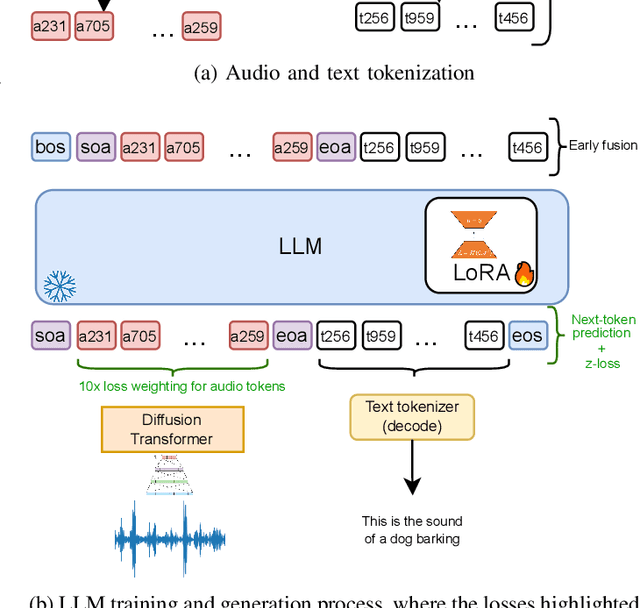


Integrating audio comprehension and generation into large language models (LLMs) remains challenging due to the continuous nature of audio and the resulting high sampling rates. Here, we introduce a novel approach that combines Variational Quantization with Conditional Flow Matching to convert audio into ultra-low bitrate discrete tokens of 0.23kpbs, allowing for seamless integration with text tokens in LLMs. We fine-tuned a pretrained text-based LLM using Low-Rank Adaptation (LoRA) to assess its effectiveness in achieving true multimodal capabilities, i.e., audio comprehension and generation. Our tokenizer outperforms a traditional VQ-VAE across various datasets with diverse acoustic events. Despite the substantial loss of fine-grained details through audio tokenization, our multimodal LLM trained with discrete tokens achieves competitive results in audio comprehension with state-of-the-art methods, though audio generation is poor. Our results highlight the need for larger, more diverse datasets and improved evaluation metrics to advance multimodal LLM performance.
Should you use a probabilistic duration model in TTS? Probably! Especially for spontaneous speech
Jun 08, 2024Converting input symbols to output audio in TTS requires modelling the durations of speech sounds. Leading non-autoregressive (NAR) TTS models treat duration modelling as a regression problem. The same utterance is then spoken with identical timings every time, unlike when a human speaks. Probabilistic models of duration have been proposed, but there is mixed evidence of their benefits. However, prior studies generally only consider speech read aloud, and ignore spontaneous speech, despite the latter being both a more common and a more variable mode of speaking. We compare the effect of conventional deterministic duration modelling to durations sampled from a powerful probabilistic model based on conditional flow matching (OT-CFM), in three different NAR TTS approaches: regression-based, deep generative, and end-to-end. Across four different corpora, stochastic duration modelling improves probabilistic NAR TTS approaches, especially for spontaneous speech. Please see https://shivammehta25.github.io/prob_dur/ for audio and resources.
Fake it to make it: Using synthetic data to remedy the data shortage in joint multimodal speech-and-gesture synthesis
Apr 30, 2024Although humans engaged in face-to-face conversation simultaneously communicate both verbally and non-verbally, methods for joint and unified synthesis of speech audio and co-speech 3D gesture motion from text are a new and emerging field. These technologies hold great promise for more human-like, efficient, expressive, and robust synthetic communication, but are currently held back by the lack of suitably large datasets, as existing methods are trained on parallel data from all constituent modalities. Inspired by student-teacher methods, we propose a straightforward solution to the data shortage, by simply synthesising additional training material. Specifically, we use unimodal synthesis models trained on large datasets to create multimodal (but synthetic) parallel training data, and then pre-train a joint synthesis model on that material. In addition, we propose a new synthesis architecture that adds better and more controllable prosody modelling to the state-of-the-art method in the field. Our results confirm that pre-training on large amounts of synthetic data improves the quality of both the speech and the motion synthesised by the multimodal model, with the proposed architecture yielding further benefits when pre-trained on the synthetic data. See https://shivammehta25.github.io/MAGI/ for example output.
Unified speech and gesture synthesis using flow matching
Oct 08, 2023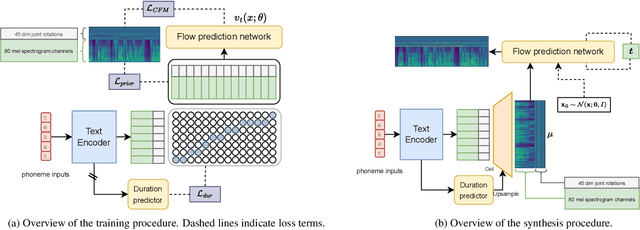
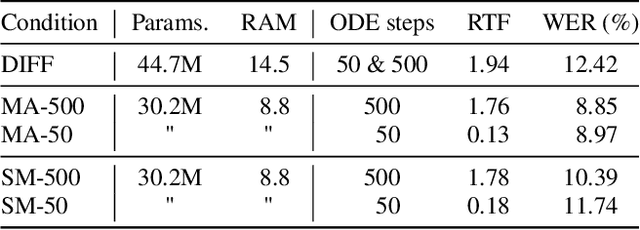
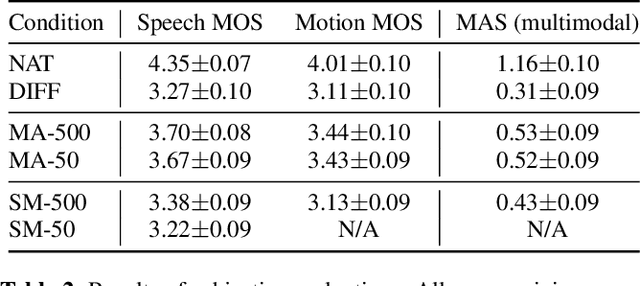
As text-to-speech technologies achieve remarkable naturalness in read-aloud tasks, there is growing interest in multimodal synthesis of verbal and non-verbal communicative behaviour, such as spontaneous speech and associated body gestures. This paper presents a novel, unified architecture for jointly synthesising speech acoustics and skeleton-based 3D gesture motion from text, trained using optimal-transport conditional flow matching (OT-CFM). The proposed architecture is simpler than the previous state of the art, has a smaller memory footprint, and can capture the joint distribution of speech and gestures, generating both modalities together in one single process. The new training regime, meanwhile, enables better synthesis quality in much fewer steps (network evaluations) than before. Uni- and multimodal subjective tests demonstrate improved speech naturalness, gesture human-likeness, and cross-modal appropriateness compared to existing benchmarks.
Diffusion-Based Co-Speech Gesture Generation Using Joint Text and Audio Representation
Sep 11, 2023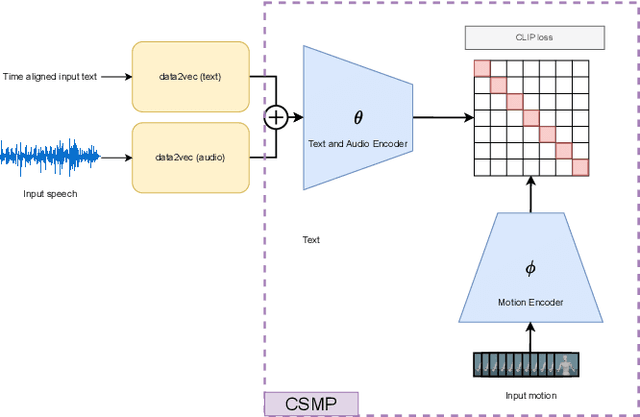
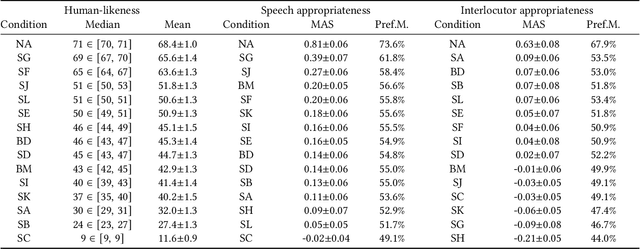
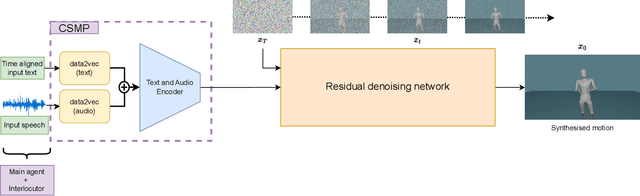
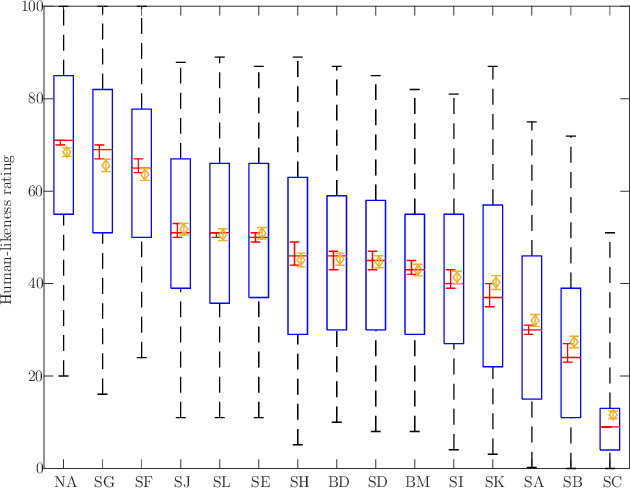
This paper describes a system developed for the GENEA (Generation and Evaluation of Non-verbal Behaviour for Embodied Agents) Challenge 2023. Our solution builds on an existing diffusion-based motion synthesis model. We propose a contrastive speech and motion pretraining (CSMP) module, which learns a joint embedding for speech and gesture with the aim to learn a semantic coupling between these modalities. The output of the CSMP module is used as a conditioning signal in the diffusion-based gesture synthesis model in order to achieve semantically-aware co-speech gesture generation. Our entry achieved highest human-likeness and highest speech appropriateness rating among the submitted entries. This indicates that our system is a promising approach to achieve human-like co-speech gestures in agents that carry semantic meaning.
Matcha-TTS: A fast TTS architecture with conditional flow matching
Sep 06, 2023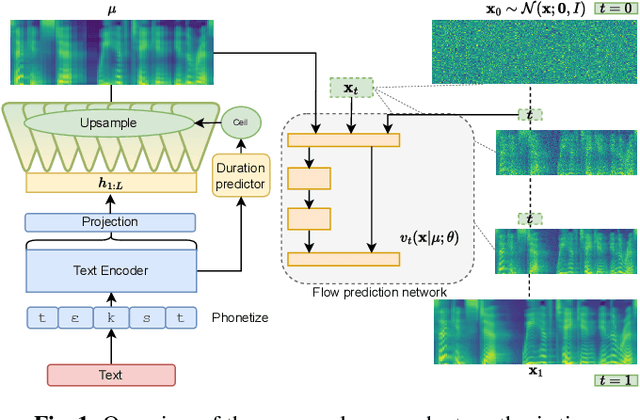
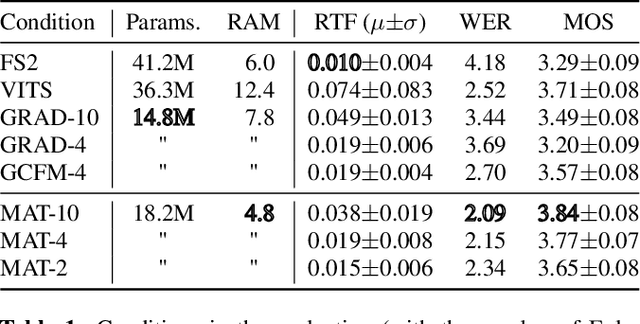
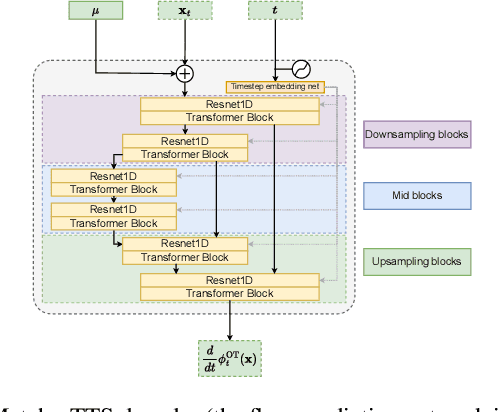
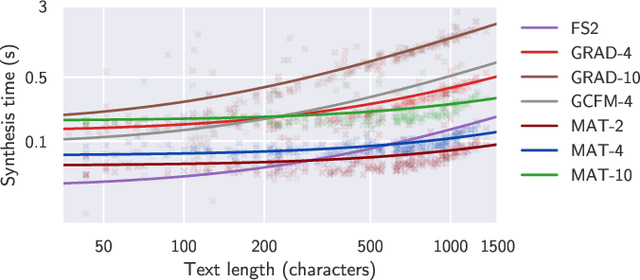
We introduce Matcha-TTS, a new encoder-decoder architecture for speedy TTS acoustic modelling, trained using optimal-transport conditional flow matching (OT-CFM). This yields an ODE-based decoder capable of high output quality in fewer synthesis steps than models trained using score matching. Careful design choices additionally ensure each synthesis step is fast to run. The method is probabilistic, non-autoregressive, and learns to speak from scratch without external alignments. Compared to strong pre-trained baseline models, the Matcha-TTS system has the smallest memory footprint, rivals the speed of the fastest models on long utterances, and attains the highest mean opinion score in a listening test. Please see https://shivammehta25.github.io/Matcha-TTS/ for audio examples, code, and pre-trained models.
Diff-TTSG: Denoising probabilistic integrated speech and gesture synthesis
Jun 15, 2023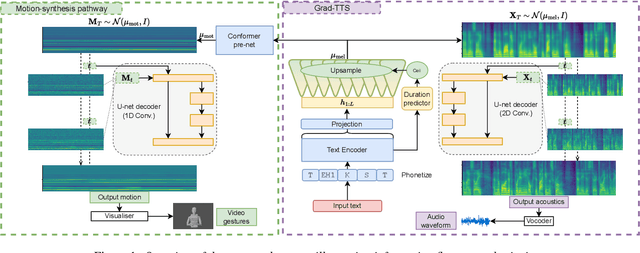

With read-aloud speech synthesis achieving high naturalness scores, there is a growing research interest in synthesising spontaneous speech. However, human spontaneous face-to-face conversation has both spoken and non-verbal aspects (here, co-speech gestures). Only recently has research begun to explore the benefits of jointly synthesising these two modalities in a single system. The previous state of the art used non-probabilistic methods, which fail to capture the variability of human speech and motion, and risk producing oversmoothing artefacts and sub-optimal synthesis quality. We present the first diffusion-based probabilistic model, called Diff-TTSG, that jointly learns to synthesise speech and gestures together. Our method can be trained on small datasets from scratch. Furthermore, we describe a set of careful uni- and multi-modal subjective tests for evaluating integrated speech and gesture synthesis systems, and use them to validate our proposed approach. For synthesised examples please see https://shivammehta25.github.io/Diff-TTSG
Prosody-controllable spontaneous TTS with neural HMMs
Nov 24, 2022Spontaneous speech has many affective and pragmatic functions that are interesting and challenging to model in TTS (text-to-speech). However, the presence of reduced articulation, fillers, repetitions, and other disfluencies mean that text and acoustics are less well aligned than in read speech. This is problematic for attention-based TTS. We propose a TTS architecture that is particularly suited for rapidly learning to speak from irregular and small datasets while also reproducing the diversity of expressive phenomena present in spontaneous speech. Specifically, we modify an existing neural HMM-based TTS system, which is capable of stable, monotonic alignments for spontaneous speech, and add utterance-level prosody control, so that the system can represent the wide range of natural variability in a spontaneous speech corpus. We objectively evaluate control accuracy and perform a subjective listening test to compare to a system without prosody control. To exemplify the power of combining mid-level prosody control and ecologically valid data for reproducing intricate spontaneous speech phenomena, we evaluate the system's capability of synthesizing two types of creaky phonation. Audio samples are available at https://hfkml.github.io/pc_nhmm_tts/
OverFlow: Putting flows on top of neural transducers for better TTS
Nov 13, 2022



Neural HMMs are a type of neural transducer recently proposed for sequence-to-sequence modelling in text-to-speech. They combine the best features of classic statistical speech synthesis and modern neural TTS, requiring less data and fewer training updates, and are less prone to gibberish output caused by neural attention failures. In this paper, we combine neural HMM TTS with normalising flows for describing the highly non-Gaussian distribution of speech acoustics. The result is a powerful, fully probabilistic model of durations and acoustics that can be trained using exact maximum likelihood. Compared to dominant flow-based acoustic models, our approach integrates autoregression for improved modelling of long-range dependences such as utterance-level prosody. Experiments show that a system based on our proposal gives more accurate pronunciations and better subjective speech quality than comparable methods, whilst retaining the original advantages of neural HMMs. Audio examples and code are available at https://shivammehta25.github.io/OverFlow/