 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmojiVoice: Towards long-term controllable expressivity in robot speech
Jun 18, 2025Humans vary their expressivity when speaking for extended periods to maintain engagement with their listener. Although social robots tend to be deployed with ``expressive'' joyful voices, they lack this long-term variation found in human speech. Foundation model text-to-speech systems are beginning to mimic the expressivity in human speech, but they are difficult to deploy offline on robots. We present EmojiVoice, a free, customizable text-to-speech (TTS) toolkit that allows social roboticists to build temporally variable, expressive speech on social robots. We introduce emoji-prompting to allow fine-grained control of expressivity on a phase level and use the lightweight Matcha-TTS backbone to generate speech in real-time. We explore three case studies: (1) a scripted conversation with a robot assistant, (2) a storytelling robot, and (3) an autonomous speech-to-speech interactive agent. We found that using varied emoji prompting improved the perception and expressivity of speech over a long period in a storytelling task, but expressive voice was not preferred in the assistant use case.
BERSting at the Screams: A Benchmark for Distanced, Emotional and Shouted Speech Recognition
Apr 30, 2025Some speech recognition tasks, such as automatic speech recognition (ASR), are approaching or have reached human performance in many reported metrics. Yet, they continue to struggle in complex, real-world, situations, such as with distanced speech. Previous challenges have released datasets to address the issue of distanced ASR, however, the focus remains primarily on distance, specifically relying on multi-microphone array systems. Here we present the B(asic) E(motion) R(andom phrase) S(hou)t(s) (BERSt) dataset. The dataset contains almost 4 hours of English speech from 98 actors with varying regional and non-native accents. The data was collected on smartphones in the actors homes and therefore includes at least 98 different acoustic environments. The data also includes 7 different emotion prompts and both shouted and spoken utterances. The smartphones were places in 19 different positions, including obstructions and being in a different room than the actor. This data is publicly available for use and can be used to evaluate a variety of speech recognition tasks, including: ASR, shout detection, and speech emotion recognition (SER). We provide initial benchmarks for ASR and SER tasks, and find that ASR degrades both with an increase in distance and shout level and shows varied performance depending on the intended emotion. Our results show that the BERSt dataset is challenging for both ASR and SER tasks and continued work is needed to improve the robustness of such systems for more accurate real-world use.
Past, Present, and Future: A Survey of The Evolution of Affective Robotics For Well-being
Jul 03, 2024Recent research in affective robots has recognized their potential in supporting human well-being. Due to rapidly developing affective and artificial intelligence technologies, this field of research has undergone explosive expansion and advancement in recent years. In order to develop a deeper understanding of recent advancements, we present a systematic review of the past 10 years of research in affective robotics for wellbeing. In this review, we identify the domains of well-being that have been studied, the methods used to investigate affective robots for well-being, and how these have evolved over time. We also examine the evolution of the multifaceted research topic from three lenses: technical, design, and ethical. Finally, we discuss future opportunities for research based on the gaps we have identified in our review -- proposing pathways to take affective robotics from the past and present to the future. The results of our review are of interest to human-robot interaction and affective computing researchers, as well as clinicians and well-being professionals who may wish to examine and incorporate affective robotics in their practices.
Mmm whatcha say? Uncovering distal and proximal context effects in first and second-language word perception using psychophysical reverse correlation
Jun 08, 2024



Acoustic context effects, where surrounding changes in pitch, rate or timbre influence the perception of a sound, are well documented in speech perception, but how they interact with language background remains unclear. Using a reverse-correlation approach, we systematically varied the pitch and speech rate in phrases around different pairs of vowels for second language (L2) speakers of English (/i/-/I/) and French (/u/-/y/), thus reconstructing, in a data-driven manner, the prosodic profiles that bias their perception. Testing English and French speakers (n=25), we showed that vowel perception is in fact influenced by conflicting effects from the surrounding pitch and speech rate: a congruent proximal effect 0.2s pre-target and a distal contrastive effect up to 1s before; and found that L1 and L2 speakers exhibited strikingly similar prosodic profiles in perception. We provide a novel method to investigate acoustic context effects across stimuli, timescales, and acoustic domain.
Predicting Long-Term Human Behaviors in Discrete Representations via Physics-Guided Diffusion
May 29, 2024
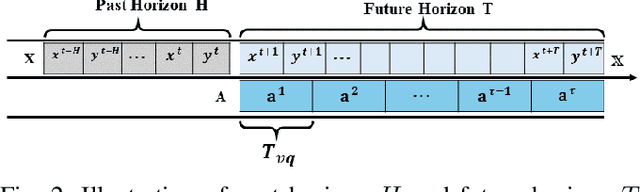
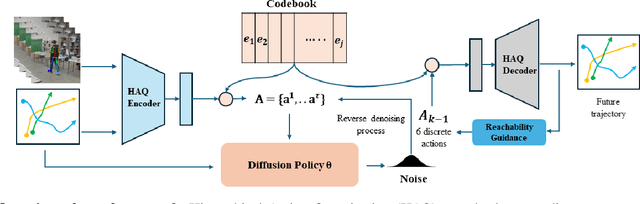
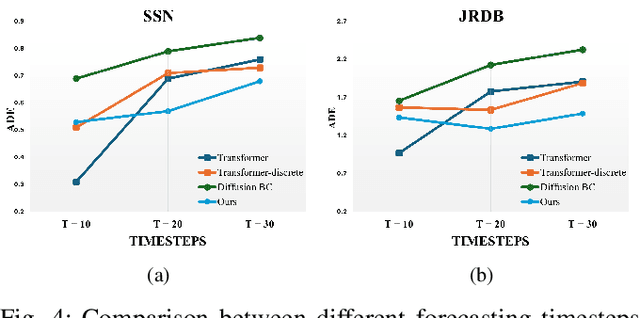
Long-term human trajectory prediction is a challenging yet critical task in robotics and autonomous systems. Prior work that studied how to predict accurate short-term human trajectories with only unimodal features often failed in long-term prediction. Reinforcement learning provides a good solution for learning human long-term behaviors but can suffer from challenges in data efficiency and optimization. In this work, we propose a long-term human trajectory forecasting framework that leverages a guided diffusion model to generate diverse long-term human behaviors in a high-level latent action space, obtained via a hierarchical action quantization scheme using a VQ-VAE to discretize continuous trajectories and the available context. The latent actions are predicted by our guided diffusion model, which uses physics-inspired guidance at test time to constrain generated multimodal action distributions. Specifically, we use reachability analysis during the reverse denoising process to guide the diffusion steps toward physically feasible latent actions. We evaluate our framework on two publicly available human trajectory forecasting datasets: SFU-Store-Nav and JRDB, and extensive experimental results show that our framework achieves superior performance in long-term human trajectory forecasting.
Contextual Emotion Recognition using Large Vision Language Models
May 14, 2024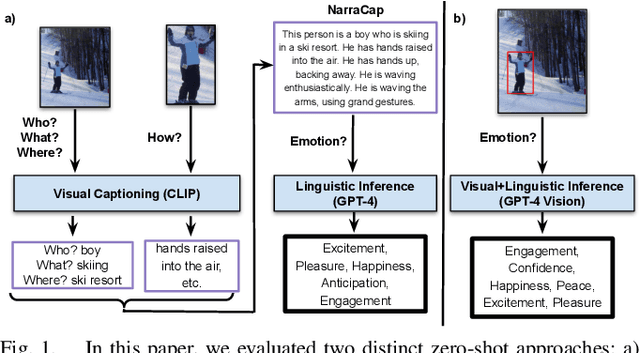
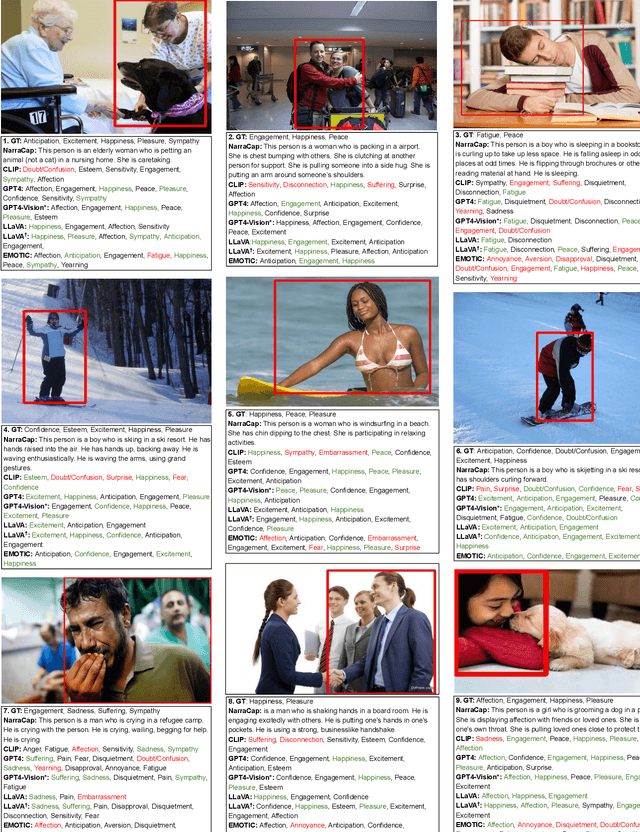

"How does the person in the bounding box feel?" Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.
Good Things Come in Trees: Emotion and Context Aware Behaviour Trees for Ethical Robotic Decision-Making
May 10, 2024Emotions guide our decision making process and yet have been little explored in practical ethical decision making scenarios. In this challenge, we explore emotions and how they can influence ethical decision making in a home robot context: which fetch requests should a robot execute, and why or why not? We discuss, in particular, two aspects of emotion: (1) somatic markers: objects to be retrieved are tagged as negative (dangerous, e.g. knives or mind-altering, e.g. medicine with overdose potential), providing a quick heuristic for where to focus attention to avoid the classic Frame Problem of artificial intelligence, (2) emotion inference: users' valence and arousal levels are taken into account in defining how and when a robot should respond to a human's requests, e.g. to carefully consider giving dangerous items to users experiencing intense emotions. Our emotion-based approach builds a foundation for the primary consideration of Safety, and is complemented by policies that support overriding based on Context (e.g. age of user, allergies) and Privacy (e.g. administrator settings). Transparency is another key aspect of our solution. Our solution is defined using behaviour trees, towards an implementable design that can provide reasoning information in real-time.
MotionScript: Natural Language Descriptions for Expressive 3D Human Motions
Dec 19, 2023



This paper proposes MotionScript, a motion-to-text conversion algorithm and natural language representation for human body motions. MotionScript aims to describe movements in greater detail and with more accuracy than previous natural language approaches. Many motion datasets describe relatively objective and simple actions with little variation on the way they are expressed (e.g. sitting, walking, dribbling a ball). But for expressive actions that contain a diversity of movements in the class (e.g. being sad, dancing), or for actions outside the domain of standard motion capture datasets (e.g. stylistic walking, sign-language), more specific and granular natural language descriptions are needed. Our proposed MotionScript descriptions differ from existing natural language representations in that it provides direct descriptions in natural language instead of simple action labels or high-level human captions. To the best of our knowledge, this is the first attempt at translating 3D motions to natural language descriptions without requiring training data. Our experiments show that when MotionScript representations are used in a text-to-motion neural task, body movements are more accurately reconstructed, and large language models can be used to generate unseen complex motions.
Emotional Theory of Mind: Bridging Fast Visual Processing with Slow Linguistic Reasoning
Oct 30, 2023
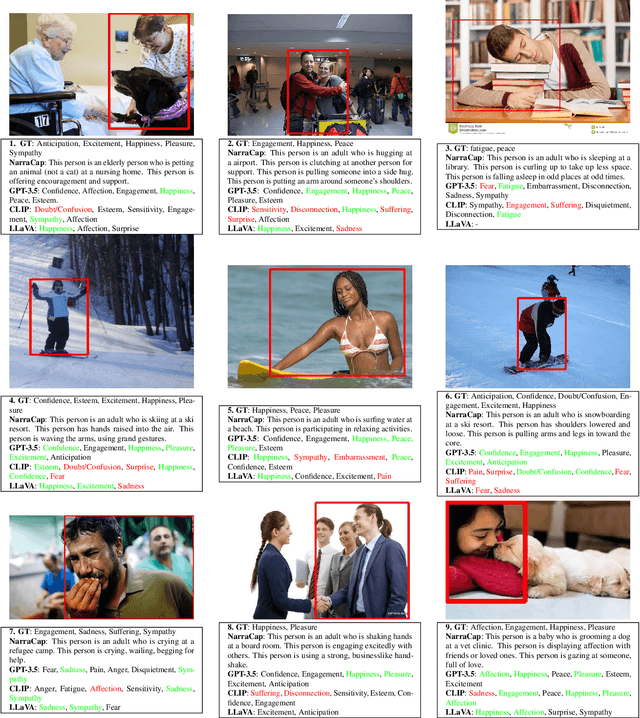

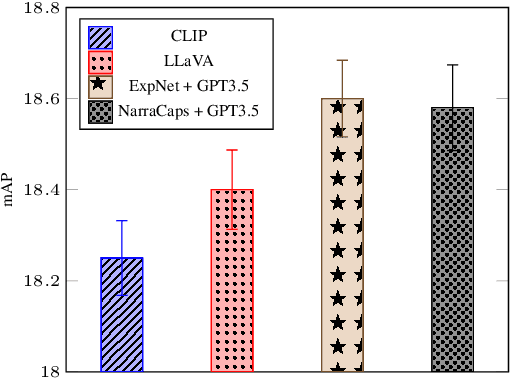
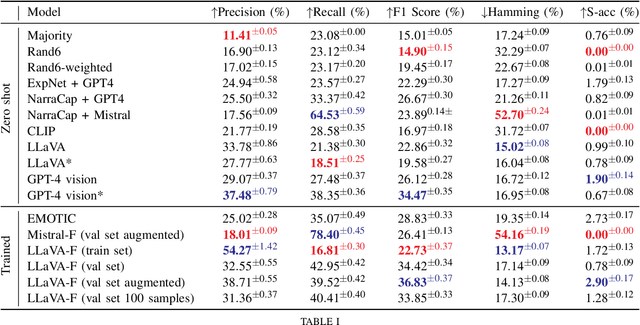
The emotional theory of mind problem in images is an emotion recognition task, specifically asking "How does the person in the bounding box feel?" Facial expressions, body pose, contextual information and implicit commonsense knowledge all contribute to the difficulty of the task, making this task currently one of the hardest problems in affective computing. The goal of this work is to evaluate the emotional commonsense knowledge embedded in recent large vision language models (CLIP, LLaVA) and large language models (GPT-3.5) on the Emotions in Context (EMOTIC) dataset. In order to evaluate a purely text-based language model on images, we construct "narrative captions" relevant to emotion perception, using a set of 872 physical social signal descriptions related to 26 emotional categories, along with 224 labels for emotionally salient environmental contexts, sourced from writer's guides for character expressions and settings. We evaluate the use of the resulting captions in an image-to-language-to-emotion task. Experiments using zero-shot vision-language models on EMOTIC show that combining "fast" and "slow" reasoning is a promising way forward to improve emotion recognition systems. Nevertheless, a gap remains in the zero-shot emotional theory of mind task compared to prior work trained on the EMOTIC dataset.
An MCTS-DRL Based Obstacle and Occlusion Avoidance Methodology in Robotic Follow-Ahead Applications
Sep 28, 2023



We propose a novel methodology for robotic follow-ahead applications that address the critical challenge of obstacle and occlusion avoidance. Our approach effectively navigates the robot while ensuring avoidance of collisions and occlusions caused by surrounding objects. To achieve this, we developed a high-level decision-making algorithm that generates short-term navigational goals for the mobile robot. Monte Carlo Tree Search is integrated with a Deep Reinforcement Learning method to enhance the performance of the decision-making process and generate more reliable navigational goals. Through extensive experimentation and analysis, we demonstrate the effectiveness and superiority of our proposed approach in comparison to the existing follow-ahead human-following robotic methods. Our code is available at https://github.com/saharLeisiazar/follow-ahead-ros.