 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Emotion Recognition using Large Vision Language Models
May 14, 2024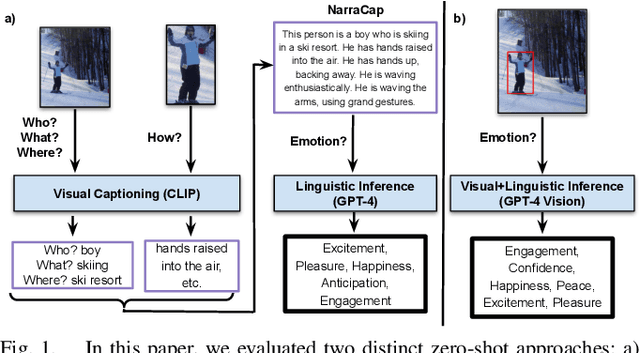
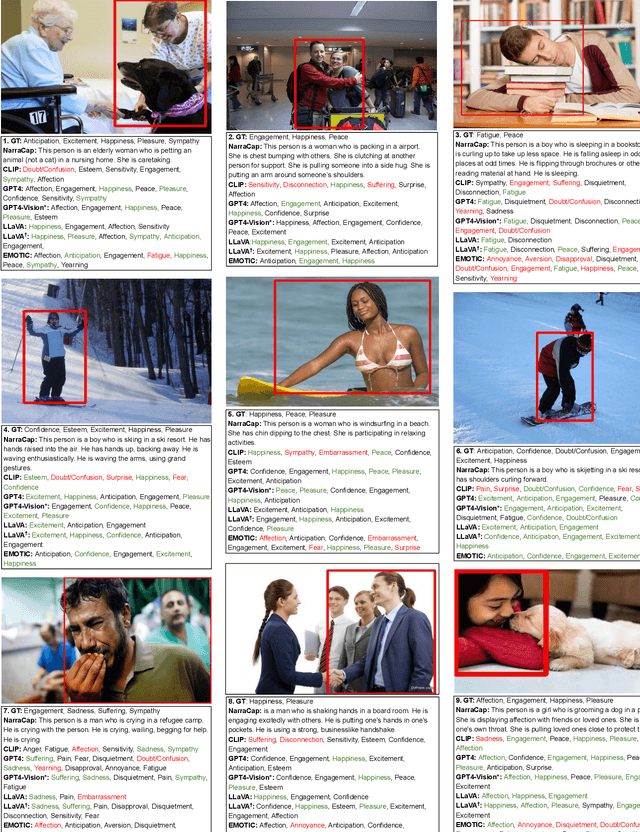

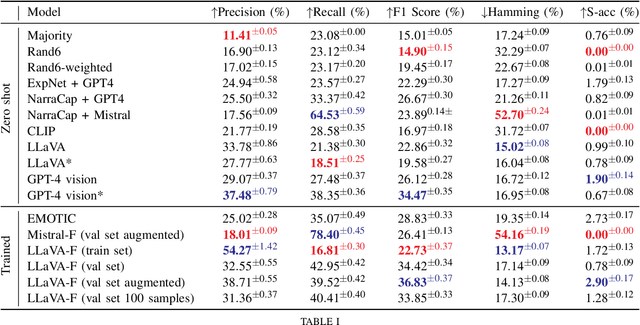
"How does the person in the bounding box feel?" Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.
Emotional Theory of Mind: Bridging Fast Visual Processing with Slow Linguistic Reasoning
Oct 30, 2023

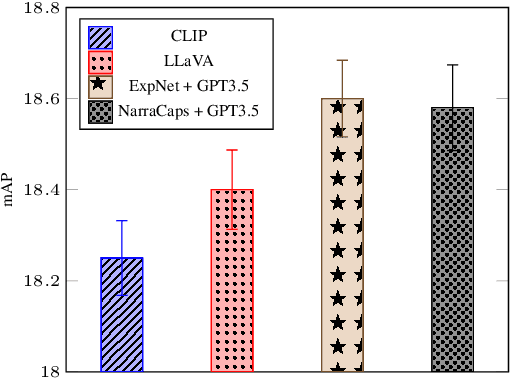
The emotional theory of mind problem in images is an emotion recognition task, specifically asking "How does the person in the bounding box feel?" Facial expressions, body pose, contextual information and implicit commonsense knowledge all contribute to the difficulty of the task, making this task currently one of the hardest problems in affective computing. The goal of this work is to evaluate the emotional commonsense knowledge embedded in recent large vision language models (CLIP, LLaVA) and large language models (GPT-3.5) on the Emotions in Context (EMOTIC) dataset. In order to evaluate a purely text-based language model on images, we construct "narrative captions" relevant to emotion perception, using a set of 872 physical social signal descriptions related to 26 emotional categories, along with 224 labels for emotionally salient environmental contexts, sourced from writer's guides for character expressions and settings. We evaluate the use of the resulting captions in an image-to-language-to-emotion task. Experiments using zero-shot vision-language models on EMOTIC show that combining "fast" and "slow" reasoning is a promising way forward to improve emotion recognition systems. Nevertheless, a gap remains in the zero-shot emotional theory of mind task compared to prior work trained on the EMOTIC dataset.
Contextual Emotion Estimation from Image Captions
Sep 22, 2023



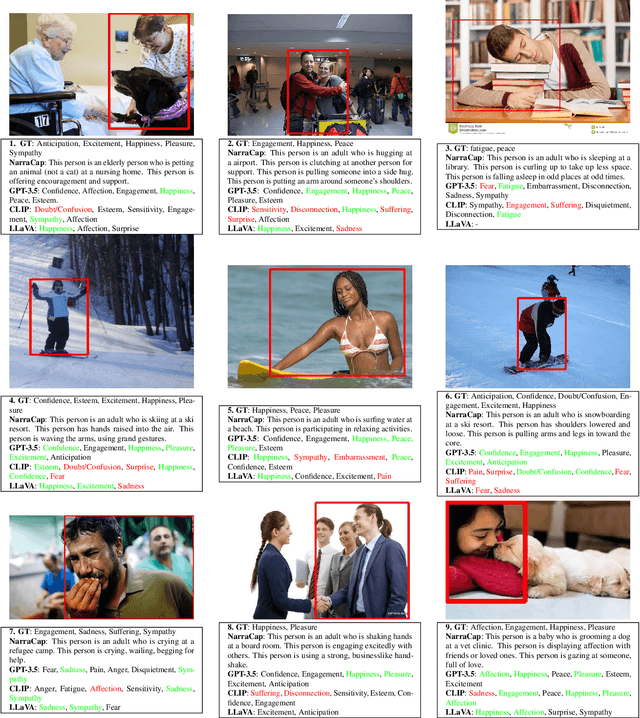
Emotion estimation in images is a challenging task, typically using computer vision methods to directly estimate people's emotions using face, body pose and contextual cues. In this paper, we explore whether Large Language Models (LLMs) can support the contextual emotion estimation task, by first captioning images, then using an LLM for inference. First, we must understand: how well do LLMs perceive human emotions? And which parts of the information enable them to determine emotions? One initial challenge is to construct a caption that describes a person within a scene with information relevant for emotion perception. Towards this goal, we propose a set of natural language descriptors for faces, bodies, interactions, and environments. We use them to manually generate captions and emotion annotations for a subset of 331 images from the EMOTIC dataset. These captions offer an interpretable representation for emotion estimation, towards understanding how elements of a scene affect emotion perception in LLMs and beyond. Secondly, we test the capability of a large language model to infer an emotion from the resulting image captions. We find that GPT-3.5, specifically the text-davinci-003 model, provides surprisingly reasonable emotion predictions consistent with human annotations, but accuracy can depend on the emotion concept. Overall, the results suggest promise in the image captioning and LLM approach.