 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotional Theory of Mind: Bridging Fast Visual Processing with Slow Linguistic Reasoning
Oct 30, 2023
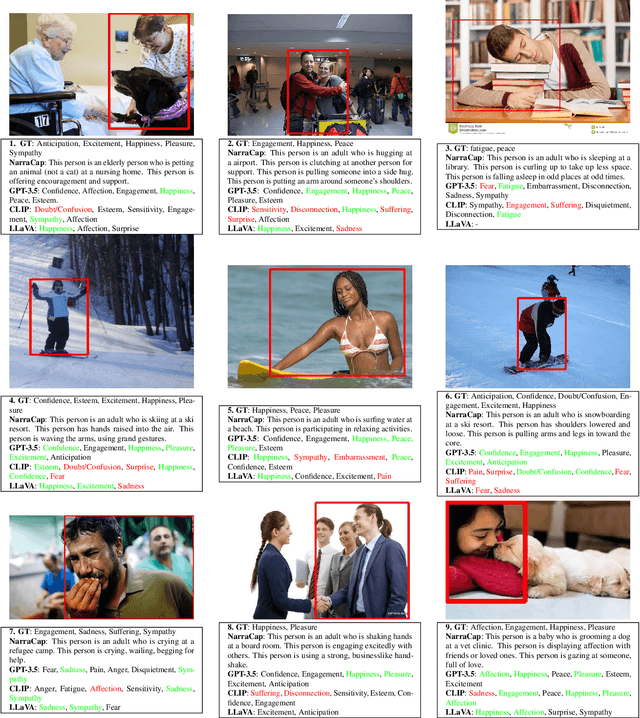

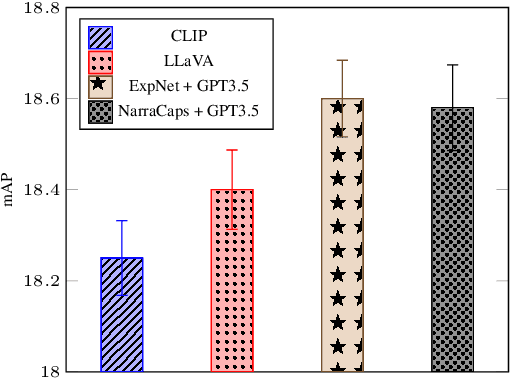
The emotional theory of mind problem in images is an emotion recognition task, specifically asking "How does the person in the bounding box feel?" Facial expressions, body pose, contextual information and implicit commonsense knowledge all contribute to the difficulty of the task, making this task currently one of the hardest problems in affective computing. The goal of this work is to evaluate the emotional commonsense knowledge embedded in recent large vision language models (CLIP, LLaVA) and large language models (GPT-3.5) on the Emotions in Context (EMOTIC) dataset. In order to evaluate a purely text-based language model on images, we construct "narrative captions" relevant to emotion perception, using a set of 872 physical social signal descriptions related to 26 emotional categories, along with 224 labels for emotionally salient environmental contexts, sourced from writer's guides for character expressions and settings. We evaluate the use of the resulting captions in an image-to-language-to-emotion task. Experiments using zero-shot vision-language models on EMOTIC show that combining "fast" and "slow" reasoning is a promising way forward to improve emotion recognition systems. Nevertheless, a gap remains in the zero-shot emotional theory of mind task compared to prior work trained on the EMOTIC dataset.