 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Emotion Recognition using Large Vision Language Models
Paper and Code
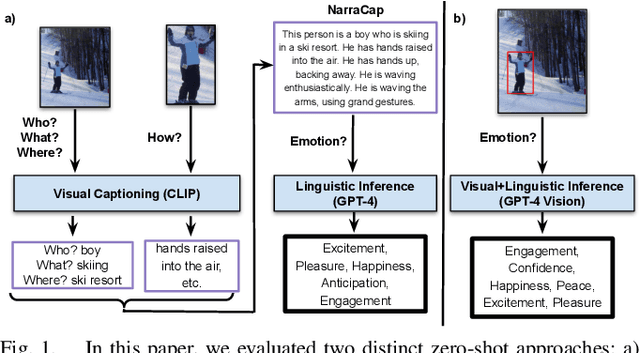
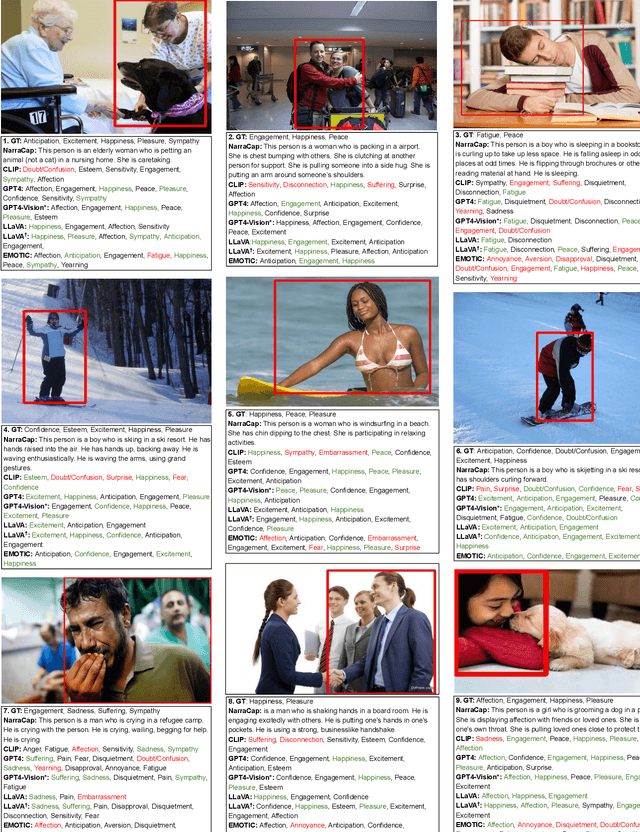

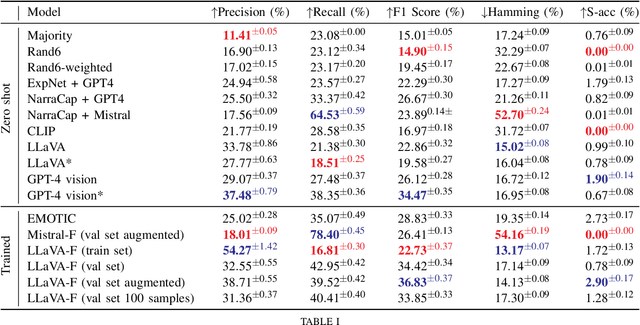
"How does the person in the bounding box feel?" Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.