 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPHO: Joint Visual-Physical Cue Learning and Aggregation for Hand-Object Pose Estimation
Nov 15, 2025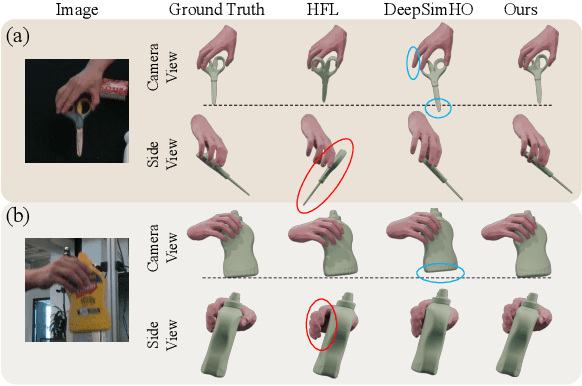
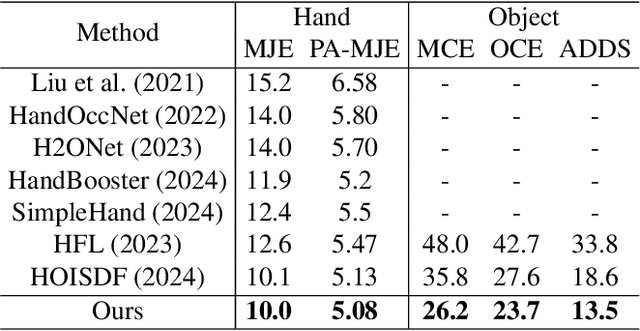
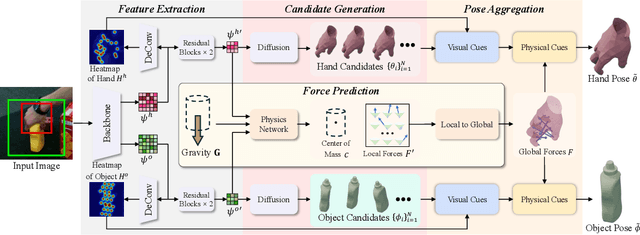
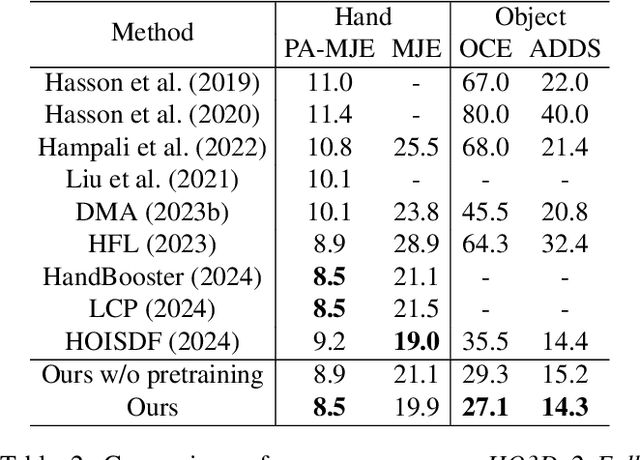
Estimating the 3D poses of hands and objects from a single RGB image is a fundamental yet challenging problem, with broad applications in augmented reality and human-computer interaction. Existing methods largely rely on visual cues alone, often producing results that violate physical constraints such as interpenetration or non-contact. Recent efforts to incorporate physics reasoning typically depend on post-optimization or non-differentiable physics engines, which compromise visual consistency and end-to-end trainability. To overcome these limitations, we propose a novel framework that jointly integrates visual and physical cues for hand-object pose estimation. This integration is achieved through two key ideas: 1) joint visual-physical cue learning: The model is trained to extract 2D visual cues and 3D physical cues, thereby enabling more comprehensive representation learning for hand-object interactions; 2) candidate pose aggregation: A novel refinement process that aggregates multiple diffusion-generated candidate poses by leveraging both visual and physical predictions, yielding a final estimate that is visually consistent and physically plausible. Extensive experiments demonstrate that our method significantly outperforms existing state-of-the-art approaches in both pose accuracy and physical plausibility.
CasaGPT: Cuboid Arrangement and Scene Assembly for Interior Design
Apr 28, 2025We present a novel approach for indoor scene synthesis, which learns to arrange decomposed cuboid primitives to represent 3D objects within a scene. Unlike conventional methods that use bounding boxes to determine the placement and scale of 3D objects, our approach leverages cuboids as a straightforward yet highly effective alternative for modeling objects. This allows for compact scene generation while minimizing object intersections. Our approach, coined CasaGPT for Cuboid Arrangement and Scene Assembly, employs an autoregressive model to sequentially arrange cuboids, producing physically plausible scenes. By applying rejection sampling during the fine-tuning stage to filter out scenes with object collisions, our model further reduces intersections and enhances scene quality. Additionally, we introduce a refined dataset, 3DFRONT-NC, which eliminates significant noise presented in the original dataset, 3D-FRONT. Extensive experiments on the 3D-FRONT dataset as well as our dataset demonstrate that our approach consistently outperforms the state-of-the-art methods, enhancing the realism of generated scenes, and providing a promising direction for 3D scene synthesis.
MotionDreamer: One-to-Many Motion Synthesis with Localized Generative Masked Transformer
Apr 11, 2025Generative masked transformers have demonstrated remarkable success across various content generation tasks, primarily due to their ability to effectively model large-scale dataset distributions with high consistency. However, in the animation domain, large datasets are not always available. Applying generative masked modeling to generate diverse instances from a single MoCap reference may lead to overfitting, a challenge that remains unexplored. In this work, we present MotionDreamer, a localized masked modeling paradigm designed to learn internal motion patterns from a given motion with arbitrary topology and duration. By embedding the given motion into quantized tokens with a novel distribution regularization method, MotionDreamer constructs a robust and informative codebook for local motion patterns. Moreover, a sliding window local attention is introduced in our masked transformer, enabling the generation of natural yet diverse animations that closely resemble the reference motion patterns. As demonstrated through comprehensive experiments, MotionDreamer outperforms the state-of-the-art methods that are typically GAN or Diffusion-based in both faithfulness and diversity. Thanks to the consistency and robustness of the quantization-based approach, MotionDreamer can also effectively perform downstream tasks such as temporal motion editing, \textcolor{update}{crowd animation}, and beat-aligned dance generation, all using a single reference motion. Visit our project page: https://motiondreamer.github.io/
BOOTPLACE: Bootstrapped Object Placement with Detection Transformers
Mar 27, 2025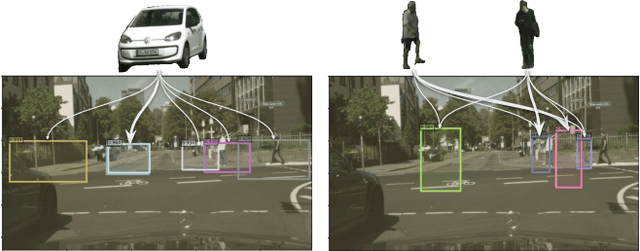

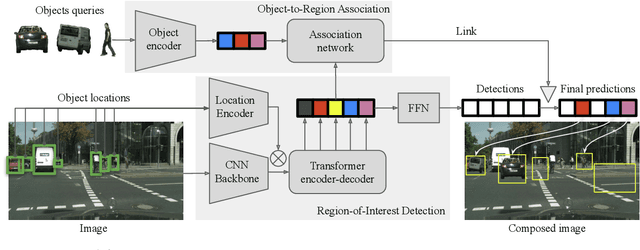
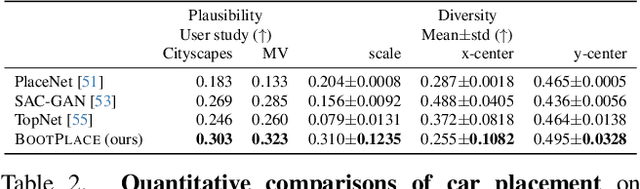
In this paper, we tackle the copy-paste image-to-image composition problem with a focus on object placement learning. Prior methods have leveraged generative models to reduce the reliance for dense supervision. However, this often limits their capacity to model complex data distributions. Alternatively, transformer networks with a sparse contrastive loss have been explored, but their over-relaxed regularization often leads to imprecise object placement. We introduce BOOTPLACE, a novel paradigm that formulates object placement as a placement-by-detection problem. Our approach begins by identifying suitable regions of interest for object placement. This is achieved by training a specialized detection transformer on object-subtracted backgrounds, enhanced with multi-object supervisions. It then semantically associates each target compositing object with detected regions based on their complementary characteristics. Through a boostrapped training approach applied to randomly object-subtracted images, our model enforces meaningful placements through extensive paired data augmentation. Experimental results on established benchmarks demonstrate BOOTPLACE's superior performance in object repositioning, markedly surpassing state-of-the-art baselines on Cityscapes and OPA datasets with notable improvements in IOU scores. Additional ablation studies further showcase the compositionality and generalizability of our approach, supported by user study evaluations.
InterMask: 3D Human Interaction Generation via Collaborative Masked Modelling
Oct 13, 2024Generating realistic 3D human-human interactions from textual descriptions remains a challenging task. Existing approaches, typically based on diffusion models, often generate unnatural and unrealistic results. In this work, we introduce InterMask, a novel framework for generating human interactions using collaborative masked modeling in discrete space. InterMask first employs a VQ-VAE to transform each motion sequence into a 2D discrete motion token map. Unlike traditional 1D VQ token maps, it better preserves fine-grained spatio-temporal details and promotes spatial awareness within each token. Building on this representation, InterMask utilizes a generative masked modeling framework to collaboratively model the tokens of two interacting individuals. This is achieved by employing a transformer architecture specifically designed to capture complex spatio-temporal interdependencies. During training, it randomly masks the motion tokens of both individuals and learns to predict them. In inference, starting from fully masked sequences, it progressively fills in the tokens for both individuals. With its enhanced motion representation, dedicated architecture, and effective learning strategy, InterMask achieves state-of-the-art results, producing high-fidelity and diverse human interactions. It outperforms previous methods, achieving an FID of $5.154$ (vs $5.535$ for in2IN) on the InterHuman dataset and $0.399$ (vs $5.207$ for InterGen) on the InterX dataset. Additionally, InterMask seamlessly supports reaction generation without the need for model redesign or fine-tuning.
RegionGrasp: A Novel Task for Contact Region Controllable Hand Grasp Generation
Oct 10, 2024



Can machine automatically generate multiple distinct and natural hand grasps, given specific contact region of an object in 3D? This motivates us to consider a novel task of \textit{Region Controllable Hand Grasp Generation (RegionGrasp)}, as follows: given as input a 3D object, together with its specific surface area selected as the intended contact region, to generate a diverse set of plausible hand grasps of the object, where the thumb finger tip touches the object surface on the contact region. To address this task, RegionGrasp-CVAE is proposed, which consists of two main parts. First, to enable contact region-awareness, we propose ConditionNet as the condition encoder that includes in it a transformer-backboned object encoder, O-Enc; a pretraining strategy is adopted by O-Enc, where the point patches of object surface are randomly masked off and subsequently restored, to further capture surface geometric information of the object. Second, to realize interaction awareness, HOINet is introduced to encode hand-object interaction features by entangling high-level hand features with embedded object features through geometric-aware multi-head cross attention. Empirical evaluations demonstrate the effectiveness of our approach qualitatively and quantitatively where it is shown to compare favorably with respect to the state of the art methods.
TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling
Aug 02, 2024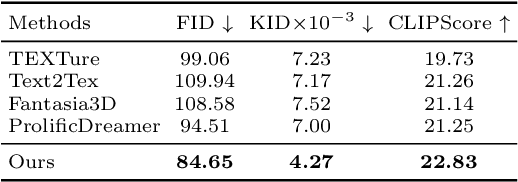
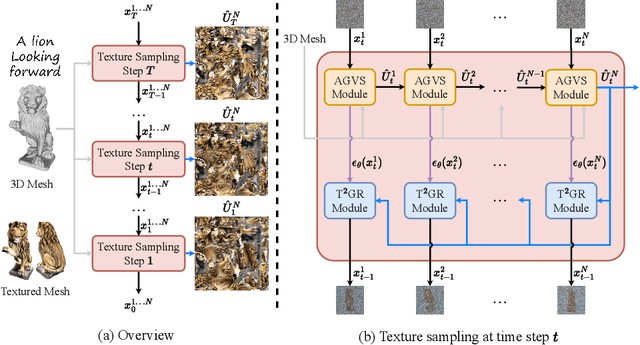

Given a 3D mesh, we aim to synthesize 3D textures that correspond to arbitrary textual descriptions. Current methods for generating and assembling textures from sampled views often result in prominent seams or excessive smoothing. To tackle these issues, we present TexGen, a novel multi-view sampling and resampling framework for texture generation leveraging a pre-trained text-to-image diffusion model. For view consistent sampling, first of all we maintain a texture map in RGB space that is parameterized by the denoising step and updated after each sampling step of the diffusion model to progressively reduce the view discrepancy. An attention-guided multi-view sampling strategy is exploited to broadcast the appearance information across views. To preserve texture details, we develop a noise resampling technique that aids in the estimation of noise, generating inputs for subsequent denoising steps, as directed by the text prompt and current texture map. Through an extensive amount of qualitative and quantitative evaluations, we demonstrate that our proposed method produces significantly better texture quality for diverse 3D objects with a high degree of view consistency and rich appearance details, outperforming current state-of-the-art methods. Furthermore, our proposed texture generation technique can also be applied to texture editing while preserving the original identity. More experimental results are available at https://dong-huo.github.io/TexGen/
GSD: View-Guided Gaussian Splatting Diffusion for 3D Reconstruction
Jul 05, 2024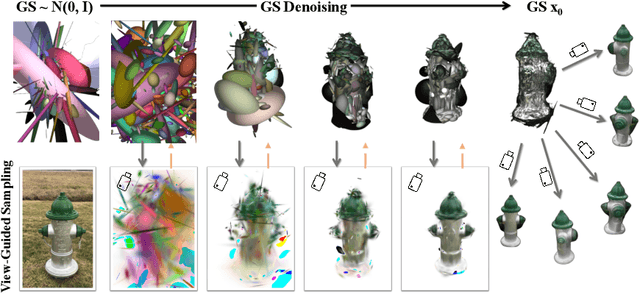



We present GSD, a diffusion model approach based on Gaussian Splatting (GS) representation for 3D object reconstruction from a single view. Prior works suffer from inconsistent 3D geometry or mediocre rendering quality due to improper representations. We take a step towards resolving these shortcomings by utilizing the recent state-of-the-art 3D explicit representation, Gaussian Splatting, and an unconditional diffusion model. This model learns to generate 3D objects represented by sets of GS ellipsoids. With these strong generative 3D priors, though learning unconditionally, the diffusion model is ready for view-guided reconstruction without further model fine-tuning. This is achieved by propagating fine-grained 2D features through the efficient yet flexible splatting function and the guided denoising sampling process. In addition, a 2D diffusion model is further employed to enhance rendering fidelity, and improve reconstructed GS quality by polishing and re-using the rendered images. The final reconstructed objects explicitly come with high-quality 3D structure and texture, and can be efficiently rendered in arbitrary views. Experiments on the challenging real-world CO3D dataset demonstrate the superiority of our approach.
Generative Human Motion Stylization in Latent Space
Jan 24, 2024



Human motion stylization aims to revise the style of an input motion while keeping its content unaltered. Unlike existing works that operate directly in pose space, we leverage the latent space of pretrained autoencoders as a more expressive and robust representation for motion extraction and infusion. Building upon this, we present a novel generative model that produces diverse stylization results of a single motion (latent) code. During training, a motion code is decomposed into two coding components: a deterministic content code, and a probabilistic style code adhering to a prior distribution; then a generator massages the random combination of content and style codes to reconstruct the corresponding motion codes. Our approach is versatile, allowing the learning of probabilistic style space from either style labeled or unlabeled motions, providing notable flexibility in stylization as well. In inference, users can opt to stylize a motion using style cues from a reference motion or a label. Even in the absence of explicit style input, our model facilitates novel re-stylization by sampling from the unconditional style prior distribution. Experimental results show that our proposed stylization models, despite their lightweight design, outperform the state-of-the-arts in style reeanactment, content preservation, and generalization across various applications and settings. Project Page: https://yxmu.foo/GenMoStyle
MotionScript: Natural Language Descriptions for Expressive 3D Human Motions
Dec 19, 2023



This paper proposes MotionScript, a motion-to-text conversion algorithm and natural language representation for human body motions. MotionScript aims to describe movements in greater detail and with more accuracy than previous natural language approaches. Many motion datasets describe relatively objective and simple actions with little variation on the way they are expressed (e.g. sitting, walking, dribbling a ball). But for expressive actions that contain a diversity of movements in the class (e.g. being sad, dancing), or for actions outside the domain of standard motion capture datasets (e.g. stylistic walking, sign-language), more specific and granular natural language descriptions are needed. Our proposed MotionScript descriptions differ from existing natural language representations in that it provides direct descriptions in natural language instead of simple action labels or high-level human captions. To the best of our knowledge, this is the first attempt at translating 3D motions to natural language descriptions without requiring training data. Our experiments show that when MotionScript representations are used in a text-to-motion neural task, body movements are more accurately reconstructed, and large language models can be used to generate unseen complex motions.