 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOOTPLACE: Bootstrapped Object Placement with Detection Transformers
Paper and Code
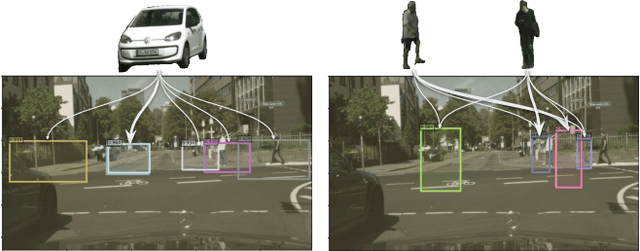

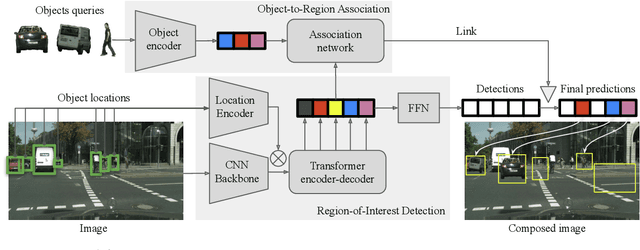
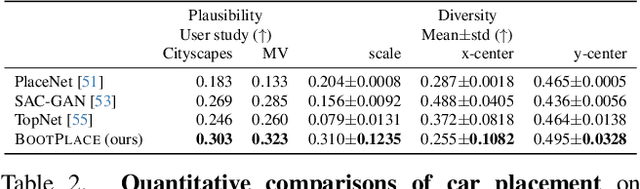
In this paper, we tackle the copy-paste image-to-image composition problem with a focus on object placement learning. Prior methods have leveraged generative models to reduce the reliance for dense supervision. However, this often limits their capacity to model complex data distributions. Alternatively, transformer networks with a sparse contrastive loss have been explored, but their over-relaxed regularization often leads to imprecise object placement. We introduce BOOTPLACE, a novel paradigm that formulates object placement as a placement-by-detection problem. Our approach begins by identifying suitable regions of interest for object placement. This is achieved by training a specialized detection transformer on object-subtracted backgrounds, enhanced with multi-object supervisions. It then semantically associates each target compositing object with detected regions based on their complementary characteristics. Through a boostrapped training approach applied to randomly object-subtracted images, our model enforces meaningful placements through extensive paired data augmentation. Experimental results on established benchmarks demonstrate BOOTPLACE's superior performance in object repositioning, markedly surpassing state-of-the-art baselines on Cityscapes and OPA datasets with notable improvements in IOU scores. Additional ablation studies further showcase the compositionality and generalizability of our approach, supported by user study evaluations.