 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamDirector: Towards Long-Term Coherent Video Trajectory Editing
Feb 27, 2026Video (camera) trajectory editing aims to synthesize new videos that follow user-defined camera paths while preserving scene content and plausibly inpainting previously unseen regions, upgrading amateur footage into professionally styled videos. Existing VTE methods struggle with precise camera control and long-range consistency because they either inject target poses through a limited-capacity embedding or rely on single-frame warping with only implicit cross-frame aggregation in video diffusion models. To address these issues, we introduce a new VTE framework that 1) explicitly aggregates information across the entire source video via a hybrid warping scheme. Specifically, static regions are progressively fused into a world cache then rendered to target camera poses, while dynamic regions are directly warped; their fusion yields globally consistent coarse frames that guide refinement. 2) processes video segments jointly with their history via a history-guided autoregressive diffusion model, while the world cache is incrementally updated to reinforce already inpainted content, enabling long-term temporal coherence. Finally, we present iPhone-PTZ, a new VTE benchmark with diverse camera motions and large trajectory variations, and achieve state-of-the-art performance with fewer parameters.
Widget2Code: From Visual Widgets to UI Code via Multimodal LLMs
Dec 22, 2025User interface to code (UI2Code) aims to generate executable code that can faithfully reconstruct a given input UI. Prior work focuses largely on web pages and mobile screens, leaving app widgets underexplored. Unlike web or mobile UIs with rich hierarchical context, widgets are compact, context-free micro-interfaces that summarize key information through dense layouts and iconography under strict spatial constraints. Moreover, while (image, code) pairs are widely available for web or mobile UIs, widget designs are proprietary and lack accessible markup. We formalize this setting as the Widget-to-Code (Widget2Code) and introduce an image-only widget benchmark with fine-grained, multi-dimensional evaluation metrics. Benchmarking shows that although generalized multimodal large language models (MLLMs) outperform specialized UI2Code methods, they still produce unreliable and visually inconsistent code. To address these limitations, we develop a baseline that jointly advances perceptual understanding and structured code generation. At the perceptual level, we follow widget design principles to assemble atomic components into complete layouts, equipped with icon retrieval and reusable visualization modules. At the system level, we design an end-to-end infrastructure, WidgetFactory, which includes a framework-agnostic widget-tailored domain-specific language (WidgetDSL) and a compiler that translates it into multiple front-end implementations (e.g., React, HTML/CSS). An adaptive rendering module further refines spatial dimensions to satisfy compactness constraints. Together, these contributions substantially enhance visual fidelity, establishing a strong baseline and unified infrastructure for future Widget2Code research.
Pressure2Motion: Hierarchical Motion Synthesis from Ground Pressure with Text Guidance
Nov 07, 2025We present Pressure2Motion, a novel motion capture algorithm that synthesizes human motion from a ground pressure sequence and text prompt. It eliminates the need for specialized lighting setups, cameras, or wearable devices, making it suitable for privacy-preserving, low-light, and low-cost motion capture scenarios. Such a task is severely ill-posed due to the indeterminate nature of the pressure signals to full-body motion. To address this issue, we introduce Pressure2Motion, a generative model that leverages pressure features as input and utilizes a text prompt as a high-level guiding constraint. Specifically, our model utilizes a dual-level feature extractor that accurately interprets pressure data, followed by a hierarchical diffusion model that discerns broad-scale movement trajectories and subtle posture adjustments. Both the physical cues gained from the pressure sequence and the semantic guidance derived from descriptive texts are leveraged to guide the motion generation with precision. To the best of our knowledge, Pressure2Motion is a pioneering work in leveraging both pressure data and linguistic priors for motion generation, and the established MPL benchmark is the first benchmark for this task. Experiments show our method generates high-fidelity, physically plausible motions, establishing a new state-of-the-art for this task. The codes and benchmarks will be publicly released upon publication.
Sketch2PoseNet: Efficient and Generalized Sketch to 3D Human Pose Prediction
Oct 30, 20253D human pose estimation from sketches has broad applications in computer animation and film production. Unlike traditional human pose estimation, this task presents unique challenges due to the abstract and disproportionate nature of sketches. Previous sketch-to-pose methods, constrained by the lack of large-scale sketch-3D pose annotations, primarily relied on optimization with heuristic rules-an approach that is both time-consuming and limited in generalizability. To address these challenges, we propose a novel approach leveraging a "learn from synthesis" strategy. First, a diffusion model is trained to synthesize sketch images from 2D poses projected from 3D human poses, mimicking disproportionate human structures in sketches. This process enables the creation of a synthetic dataset, SKEP-120K, consisting of 120k accurate sketch-3D pose annotation pairs across various sketch styles. Building on this synthetic dataset, we introduce an end-to-end data-driven framework for estimating human poses and shapes from diverse sketch styles. Our framework combines existing 2D pose detectors and generative diffusion priors for sketch feature extraction with a feed-forward neural network for efficient 2D pose estimation. Multiple heuristic loss functions are incorporated to guarantee geometric coherence between the derived 3D poses and the detected 2D poses while preserving accurate self-contacts. Qualitative, quantitative, and subjective evaluations collectively show that our model substantially surpasses previous ones in both estimation accuracy and speed for sketch-to-pose tasks.
MotionDreamer: One-to-Many Motion Synthesis with Localized Generative Masked Transformer
Apr 11, 2025Generative masked transformers have demonstrated remarkable success across various content generation tasks, primarily due to their ability to effectively model large-scale dataset distributions with high consistency. However, in the animation domain, large datasets are not always available. Applying generative masked modeling to generate diverse instances from a single MoCap reference may lead to overfitting, a challenge that remains unexplored. In this work, we present MotionDreamer, a localized masked modeling paradigm designed to learn internal motion patterns from a given motion with arbitrary topology and duration. By embedding the given motion into quantized tokens with a novel distribution regularization method, MotionDreamer constructs a robust and informative codebook for local motion patterns. Moreover, a sliding window local attention is introduced in our masked transformer, enabling the generation of natural yet diverse animations that closely resemble the reference motion patterns. As demonstrated through comprehensive experiments, MotionDreamer outperforms the state-of-the-art methods that are typically GAN or Diffusion-based in both faithfulness and diversity. Thanks to the consistency and robustness of the quantization-based approach, MotionDreamer can also effectively perform downstream tasks such as temporal motion editing, \textcolor{update}{crowd animation}, and beat-aligned dance generation, all using a single reference motion. Visit our project page: https://motiondreamer.github.io/
BOOTPLACE: Bootstrapped Object Placement with Detection Transformers
Mar 27, 2025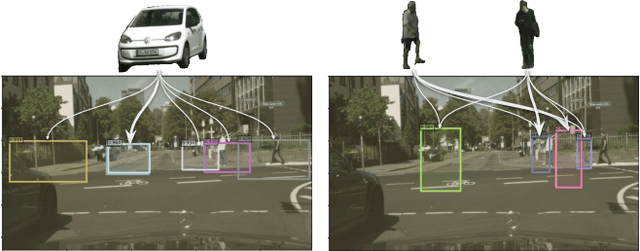

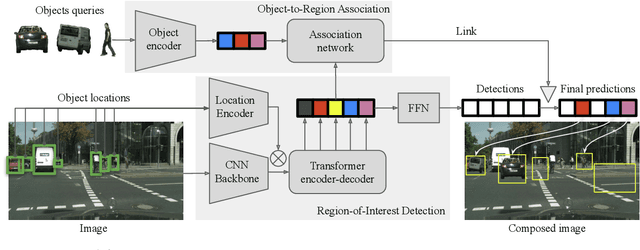
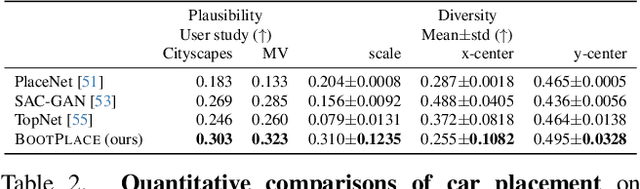
In this paper, we tackle the copy-paste image-to-image composition problem with a focus on object placement learning. Prior methods have leveraged generative models to reduce the reliance for dense supervision. However, this often limits their capacity to model complex data distributions. Alternatively, transformer networks with a sparse contrastive loss have been explored, but their over-relaxed regularization often leads to imprecise object placement. We introduce BOOTPLACE, a novel paradigm that formulates object placement as a placement-by-detection problem. Our approach begins by identifying suitable regions of interest for object placement. This is achieved by training a specialized detection transformer on object-subtracted backgrounds, enhanced with multi-object supervisions. It then semantically associates each target compositing object with detected regions based on their complementary characteristics. Through a boostrapped training approach applied to randomly object-subtracted images, our model enforces meaningful placements through extensive paired data augmentation. Experimental results on established benchmarks demonstrate BOOTPLACE's superior performance in object repositioning, markedly surpassing state-of-the-art baselines on Cityscapes and OPA datasets with notable improvements in IOU scores. Additional ablation studies further showcase the compositionality and generalizability of our approach, supported by user study evaluations.
Lifelong Learning with Task-Specific Adaptation: Addressing the Stability-Plasticity Dilemma
Mar 08, 2025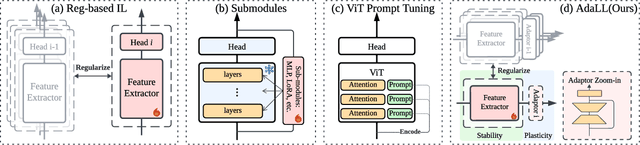
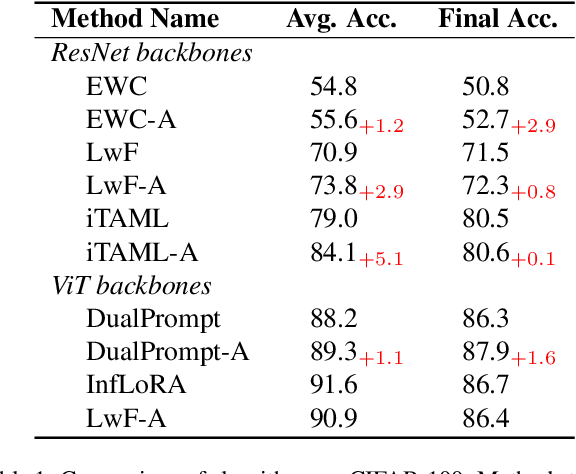
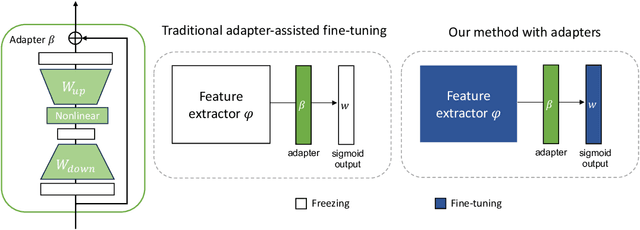

Lifelong learning (LL) aims to continuously acquire new knowledge while retaining previously learned knowledge. A central challenge in LL is the stability-plasticity dilemma, which requires models to balance the preservation of previous knowledge (stability) with the ability to learn new tasks (plasticity). While parameter-efficient fine-tuning (PEFT) has been widely adopted in large language models, its application to lifelong learning remains underexplored. To bridge this gap, this paper proposes AdaLL, an adapter-based framework designed to address the dilemma through a simple, universal, and effective strategy. AdaLL co-trains the backbone network and adapters under regularization constraints, enabling the backbone to capture task-invariant features while allowing the adapters to specialize in task-specific information. Unlike methods that freeze the backbone network, AdaLL incrementally enhances the backbone's capabilities across tasks while minimizing interference through backbone regularization. This architectural design significantly improves both stability and plasticity, effectively eliminating the stability-plasticity dilemma. Extensive experiments demonstrate that AdaLL consistently outperforms existing methods across various configurations, including dataset choices, task sequences, and task scales.
IMFine: 3D Inpainting via Geometry-guided Multi-view Refinement
Mar 06, 2025Current 3D inpainting and object removal methods are largely limited to front-facing scenes, facing substantial challenges when applied to diverse, "unconstrained" scenes where the camera orientation and trajectory are unrestricted. To bridge this gap, we introduce a novel approach that produces inpainted 3D scenes with consistent visual quality and coherent underlying geometry across both front-facing and unconstrained scenes. Specifically, we propose a robust 3D inpainting pipeline that incorporates geometric priors and a multi-view refinement network trained via test-time adaptation, building on a pre-trained image inpainting model. Additionally, we develop a novel inpainting mask detection technique to derive targeted inpainting masks from object masks, boosting the performance in handling unconstrained scenes. To validate the efficacy of our approach, we create a challenging and diverse benchmark that spans a wide range of scenes. Comprehensive experiments demonstrate that our proposed method substantially outperforms existing state-of-the-art approaches.
TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling
Aug 02, 2024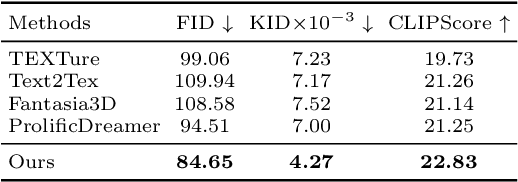
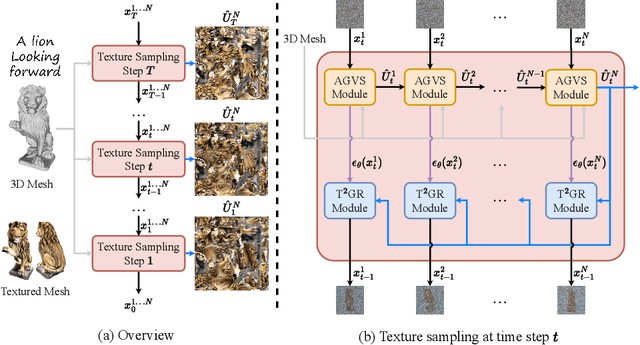
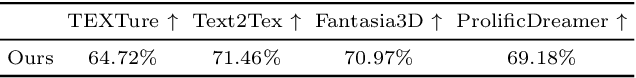

Given a 3D mesh, we aim to synthesize 3D textures that correspond to arbitrary textual descriptions. Current methods for generating and assembling textures from sampled views often result in prominent seams or excessive smoothing. To tackle these issues, we present TexGen, a novel multi-view sampling and resampling framework for texture generation leveraging a pre-trained text-to-image diffusion model. For view consistent sampling, first of all we maintain a texture map in RGB space that is parameterized by the denoising step and updated after each sampling step of the diffusion model to progressively reduce the view discrepancy. An attention-guided multi-view sampling strategy is exploited to broadcast the appearance information across views. To preserve texture details, we develop a noise resampling technique that aids in the estimation of noise, generating inputs for subsequent denoising steps, as directed by the text prompt and current texture map. Through an extensive amount of qualitative and quantitative evaluations, we demonstrate that our proposed method produces significantly better texture quality for diverse 3D objects with a high degree of view consistency and rich appearance details, outperforming current state-of-the-art methods. Furthermore, our proposed texture generation technique can also be applied to texture editing while preserving the original identity. More experimental results are available at https://dong-huo.github.io/TexGen/
GSD: View-Guided Gaussian Splatting Diffusion for 3D Reconstruction
Jul 05, 2024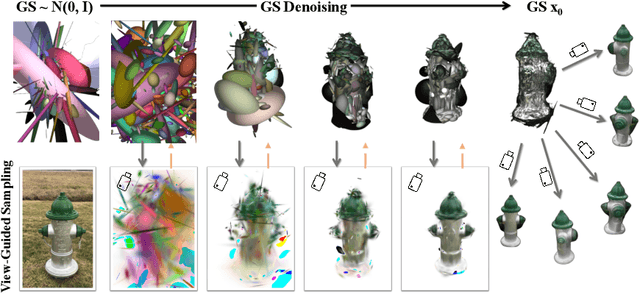



We present GSD, a diffusion model approach based on Gaussian Splatting (GS) representation for 3D object reconstruction from a single view. Prior works suffer from inconsistent 3D geometry or mediocre rendering quality due to improper representations. We take a step towards resolving these shortcomings by utilizing the recent state-of-the-art 3D explicit representation, Gaussian Splatting, and an unconditional diffusion model. This model learns to generate 3D objects represented by sets of GS ellipsoids. With these strong generative 3D priors, though learning unconditionally, the diffusion model is ready for view-guided reconstruction without further model fine-tuning. This is achieved by propagating fine-grained 2D features through the efficient yet flexible splatting function and the guided denoising sampling process. In addition, a 2D diffusion model is further employed to enhance rendering fidelity, and improve reconstructed GS quality by polishing and re-using the rendered images. The final reconstructed objects explicitly come with high-quality 3D structure and texture, and can be efficiently rendered in arbitrary views. Experiments on the challenging real-world CO3D dataset demonstrate the superiority of our approach.