 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciceVPR: Stable Cross-Image Correlation Enhanced Model for Visual Place Recognition
Feb 28, 2025



Visual Place Recognition (VPR) is a major challenge for robotics and autonomous systems, with the goal of predicting the location of an image based solely on its visual features. State-of-the-art (SOTA) models extract global descriptors using the powerful foundation model DINOv2 as backbone. These models either explore the cross-image correlation or propose a time-consuming two-stage re-ranking strategy to achieve better performance. However, existing works only utilize the final output of DINOv2, and the current cross-image correlation causes unstable retrieval results. To produce both discriminative and constant global descriptors, this paper proposes stable cross-image correlation enhanced model for VPR called SciceVPR. This model explores the full potential of DINOv2 in providing useful feature representations that implicitly encode valuable contextual knowledge. Specifically, SciceVPR first uses a multi-layer feature fusion module to capture increasingly detailed task-relevant channel and spatial information from the multi-layer output of DINOv2. Secondly, SciceVPR considers the invariant correlation between images within a batch as valuable knowledge to be distilled into the proposed self-enhanced encoder. In this way, SciceVPR can acquire fairly robust global features regardless of domain shifts (e.g., changes in illumination, weather and viewpoint between pictures taken in the same place). Experimental results demonstrate that the base variant, SciceVPR-B, outperforms SOTA one-stage methods with single input on multiple datasets with varying domain conditions. The large variant, SciceVPR-L, performs on par with SOTA two-stage models, scoring over 3% higher in Recall@1 compared to existing models on the challenging Tokyo24/7 dataset. Our code will be released at https://github.com/shuimushan/SciceVPR.
TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling
Aug 02, 2024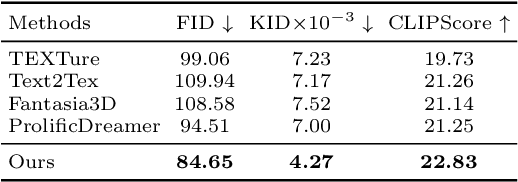
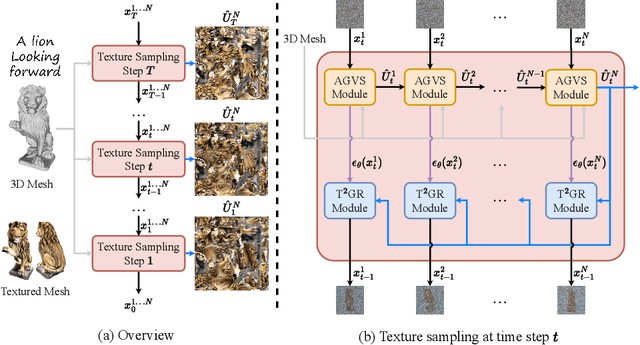
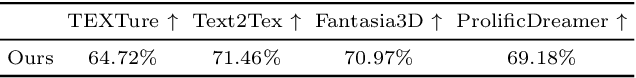

Given a 3D mesh, we aim to synthesize 3D textures that correspond to arbitrary textual descriptions. Current methods for generating and assembling textures from sampled views often result in prominent seams or excessive smoothing. To tackle these issues, we present TexGen, a novel multi-view sampling and resampling framework for texture generation leveraging a pre-trained text-to-image diffusion model. For view consistent sampling, first of all we maintain a texture map in RGB space that is parameterized by the denoising step and updated after each sampling step of the diffusion model to progressively reduce the view discrepancy. An attention-guided multi-view sampling strategy is exploited to broadcast the appearance information across views. To preserve texture details, we develop a noise resampling technique that aids in the estimation of noise, generating inputs for subsequent denoising steps, as directed by the text prompt and current texture map. Through an extensive amount of qualitative and quantitative evaluations, we demonstrate that our proposed method produces significantly better texture quality for diverse 3D objects with a high degree of view consistency and rich appearance details, outperforming current state-of-the-art methods. Furthermore, our proposed texture generation technique can also be applied to texture editing while preserving the original identity. More experimental results are available at https://dong-huo.github.io/TexGen/
Learning to Recover Spectral Reflectance from RGB Images
Apr 04, 2023



This paper tackles spectral reflectance recovery (SRR) from RGB images. Since capturing ground-truth spectral reflectance and camera spectral sensitivity are challenging and costly, most existing approaches are trained on synthetic images and utilize the same parameters for all unseen testing images, which are suboptimal especially when the trained models are tested on real images because they never exploit the internal information of the testing images. To address this issue, we adopt a self-supervised meta-auxiliary learning (MAXL) strategy that fine-tunes the well-trained network parameters with each testing image to combine external with internal information. To the best of our knowledge, this is the first work that successfully adapts the MAXL strategy to this problem. Instead of relying on naive end-to-end training, we also propose a novel architecture that integrates the physical relationship between the spectral reflectance and the corresponding RGB images into the network based on our mathematical analysis. Besides, since the spectral reflectance of a scene is independent to its illumination while the corresponding RGB images are not, we recover the spectral reflectance of a scene from its RGB images captured under multiple illuminations to further reduce the unknown. Qualitative and quantitative evaluations demonstrate the effectiveness of our proposed network and of the MAXL. Our code and data are available at https://github.com/Dong-Huo/SRR-MAXL.
SF2Former: Amyotrophic Lateral Sclerosis Identification From Multi-center MRI Data Using Spatial and Frequency Fusion Transformer
Feb 28, 2023



Amyotrophic Lateral Sclerosis (ALS) is a complex neurodegenerative disorder involving motor neuron degeneration. Significant research has begun to establish brain magnetic resonance imaging (MRI) as a potential biomarker to diagnose and monitor the state of the disease. Deep learning has turned into a prominent class of machine learning programs in computer vision and has been successfully employed to solve diverse medical image analysis tasks. However, deep learning-based methods applied to neuroimaging have not achieved superior performance in ALS patients classification from healthy controls due to having insignificant structural changes correlated with pathological features. Therefore, the critical challenge in deep models is to determine useful discriminative features with limited training data. By exploiting the long-range relationship of image features, this study introduces a framework named SF2Former that leverages vision transformer architecture's power to distinguish the ALS subjects from the control group. To further improve the network's performance, spatial and frequency domain information are combined because MRI scans are captured in the frequency domain before being converted to the spatial domain. The proposed framework is trained with a set of consecutive coronal 2D slices, which uses the pre-trained weights on ImageNet by leveraging transfer learning. Finally, a majority voting scheme has been employed to those coronal slices of a particular subject to produce the final classification decision. Our proposed architecture has been thoroughly assessed with multi-modal neuroimaging data using two well-organized versions of the Canadian ALS Neuroimaging Consortium (CALSNIC) multi-center datasets. The experimental results demonstrate the superiority of our proposed strategy in terms of classification accuracy compared with several popular deep learning-based techniques.
Glass Segmentation with RGB-Thermal Image Pairs
Apr 13, 2022
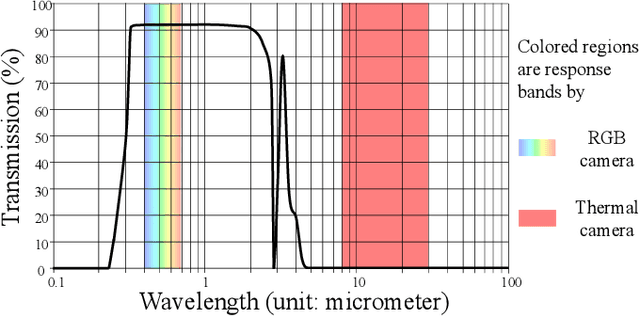


This paper proposes a new glass segmentation method utilizing paired RGB and thermal images. Due to the large difference between the transmission property of visible light and that of the thermal energy through the glass where most glass is transparent to the visible light but opaque to thermal energy, glass regions of a scene are made more distinguishable with a pair of RGB and thermal images than solely with an RGB image. To exploit such a unique property, we propose a neural network architecture that effectively combines an RGB-thermal image pair with a new multi-modal fusion module based on attention, and integrate CNN and transformer to extract local features and long-range dependencies, respectively. As well, we have collected a new dataset containing 5551 RGB-thermal image pairs with ground-truth segmentation annotations. The qualitative and quantitative evaluations demonstrate the effectiveness of the proposed approach on fusing RGB and thermal data for glass segmentation. Our code and data are available at https://github.com/Dong-Huo/RGB-T-Glass-Segmentation.
HIPA: Hierarchical Patch Transformer for Single Image Super Resolution
Mar 19, 2022
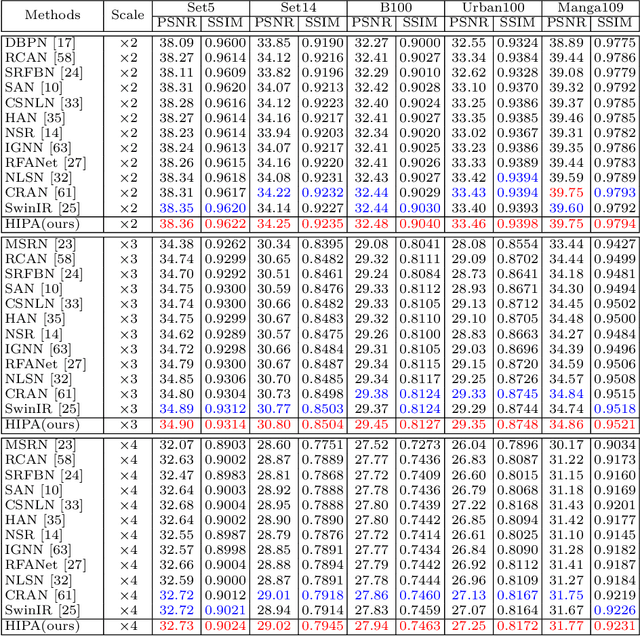
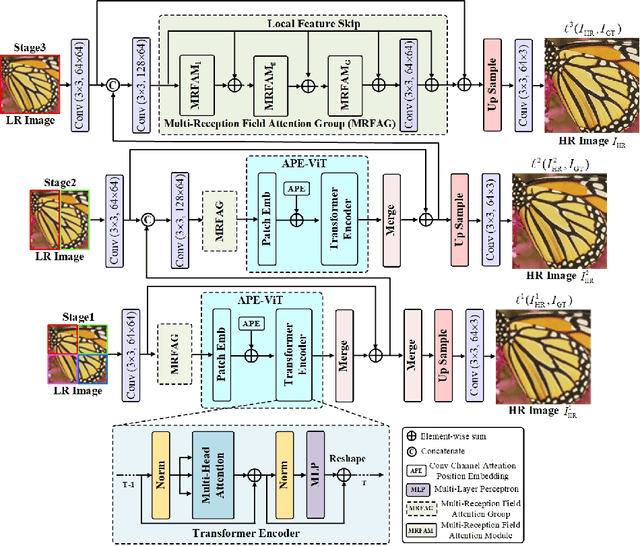

Transformer-based architectures start to emerge in single image super resolution (SISR) and have achieved promising performance. Most existing Vision Transformers divide images into the same number of patches with a fixed size, which may not be optimal for restoring patches with different levels of texture richness. This paper presents HIPA, a novel Transformer architecture that progressively recovers the high resolution image using a hierarchical patch partition. Specifically, we build a cascaded model that processes an input image in multiple stages, where we start with tokens with small patch sizes and gradually merge to the full resolution. Such a hierarchical patch mechanism not only explicitly enables feature aggregation at multiple resolutions but also adaptively learns patch-aware features for different image regions, e.g., using a smaller patch for areas with fine details and a larger patch for textureless regions. Meanwhile, a new attention-based position encoding scheme for Transformer is proposed to let the network focus on which tokens should be paid more attention by assigning different weights to different tokens, which is the first time to our best knowledge. Furthermore, we also propose a new multi-reception field attention module to enlarge the convolution reception field from different branches. The experimental results on several public datasets demonstrate the superior performance of the proposed HIPA over previous methods quantitatively and qualitatively.
Blind Image Deconvolution Using Variational Deep Image Prior
Feb 01, 2022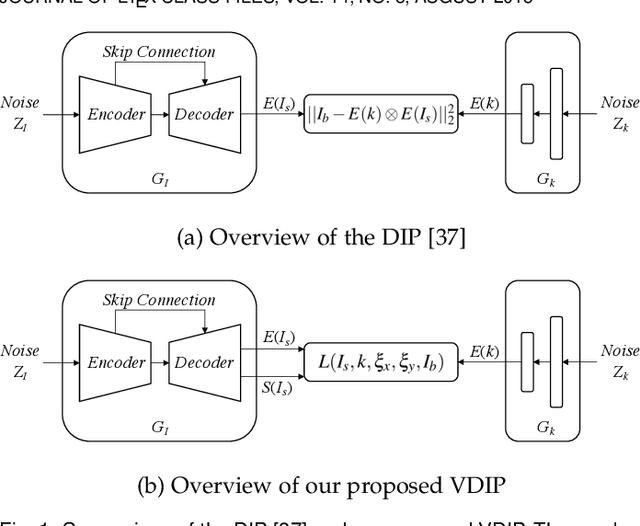
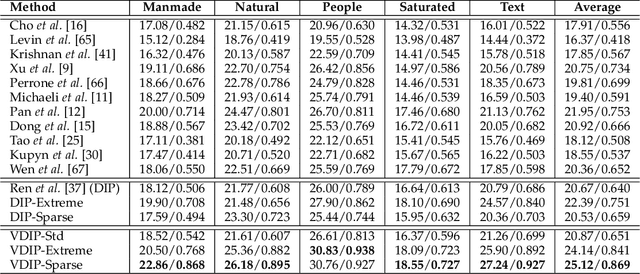
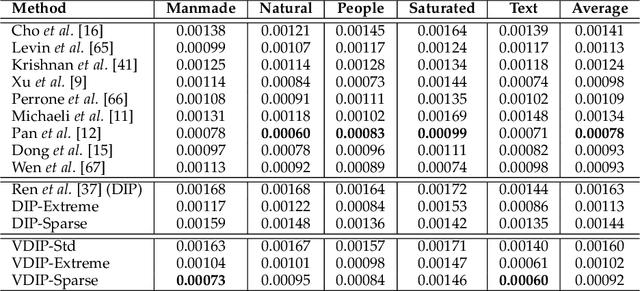
Conventional deconvolution methods utilize hand-crafted image priors to constrain the optimization. While deep-learning-based methods have simplified the optimization by end-to-end training, they fail to generalize well to blurs unseen in the training dataset. Thus, training image-specific models is important for higher generalization. Deep image prior (DIP) provides an approach to optimize the weights of a randomly initialized network with a single degraded image by maximum a posteriori (MAP), which shows that the architecture of a network can serve as the hand-crafted image prior. Different from the conventional hand-crafted image priors that are statistically obtained, it is hard to find a proper network architecture because the relationship between images and their corresponding network architectures is unclear. As a result, the network architecture cannot provide enough constraint for the latent sharp image. This paper proposes a new variational deep image prior (VDIP) for blind image deconvolution, which exploits additive hand-crafted image priors on latent sharp images and approximates a distribution for each pixel to avoid suboptimal solutions. Our mathematical analysis shows that the proposed method can better constrain the optimization. The experimental results further demonstrate that the generated images have better quality than that of the original DIP on benchmark datasets. The source code of our VDIP is available at https://github.com/Dong-Huo/VDIP-Deconvolution.
Blind Non-Uniform Motion Deblurring using Atrous Spatial Pyramid Deformable Convolution and Deblurring-Reblurring Consistency
Jun 27, 2021



Many deep learning based methods are designed to remove non-uniform (spatially variant) motion blur caused by object motion and camera shake without knowing the blur kernel. Some methods directly output the latent sharp image in one stage, while others utilize a multi-stage strategy (\eg multi-scale, multi-patch, or multi-temporal) to gradually restore the sharp image. However, these methods have the following two main issues: 1) The computational cost of multi-stage is high; 2) The same convolution kernel is applied in different regions, which is not an ideal choice for non-uniform blur. Hence, non-uniform motion deblurring is still a challenging and open problem. In this paper, we propose a new architecture which consists of multiple Atrous Spatial Pyramid Deformable Convolution (ASPDC) modules to deblur an image end-to-end with more flexibility. Multiple ASPDC modules implicitly learn the pixel-specific motion with different dilation rates in the same layer to handle movements of different magnitude. To improve the training, we also propose a reblurring network to map the deblurred output back to the blurred input, which constrains the solution space. Our experimental results show that the proposed method outperforms state-of-the-art methods on the benchmark datasets.
Blind Image Super-Resolution with Spatial Context Hallucination
Sep 25, 2020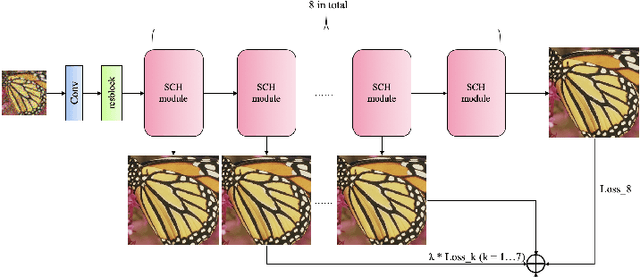

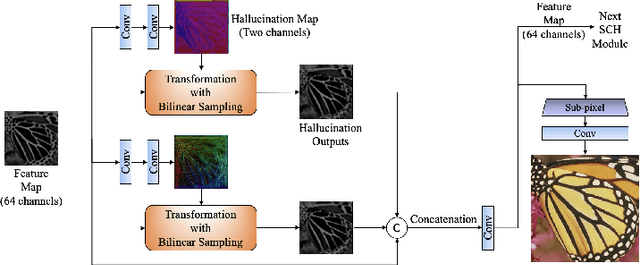
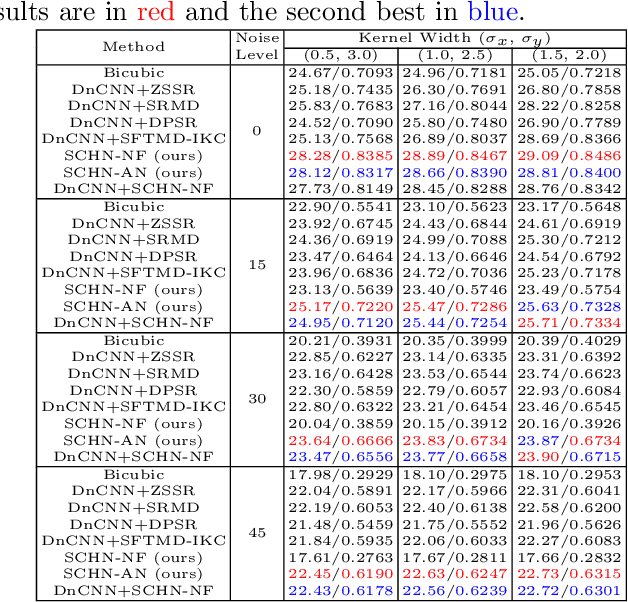
Deep convolution neural networks (CNNs) play a critical role in single image super-resolution (SISR) since the amazing improvement of high performance computing. However, most of the super-resolution (SR) methods only focus on recovering bicubic degradation. Reconstructing high-resolution (HR) images from randomly blurred and noisy low-resolution (LR) images is still a challenging problem. In this paper, we propose a novel Spatial Context Hallucination Network (SCHN) for blind super-resolution without knowing the degradation kernel. We find that when the blur kernel is unknown, separate deblurring and super-resolution could limit the performance because of the accumulation of error. Thus, we integrate denoising, deblurring and super-resolution within one framework to avoid such a problem. We train our model on two high quality datasets, DIV2K and Flickr2K. Our method performs better than state-of-the-art methods when input images are corrupted with random blur and noise.
Online Learnable Keyframe Extraction in Videos and its Application with Semantic Word Vector in Action Recognition
Sep 25, 2020
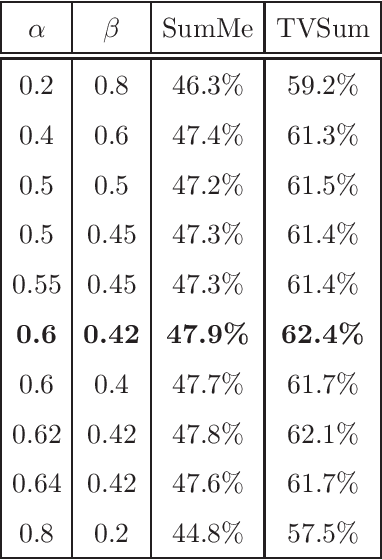
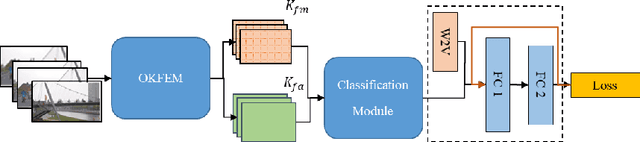

Video processing has become a popular research direction in computer vision due to its various applications such as video summarization, action recognition, etc. Recently, deep learning-based methods have achieved impressive results in action recognition. However, these methods need to process a full video sequence to recognize the action, even though most of these frames are similar and non-essential to recognizing a particular action. Additionally, these non-essential frames increase the computational cost and can confuse a method in action recognition. Instead, the important frames called keyframes not only are helpful in the recognition of an action but also can reduce the processing time of each video sequence for classification or in other applications, e.g. summarization. As well, current methods in video processing have not yet been demonstrated in an online fashion. Motivated by the above, we propose an online learnable module for keyframe extraction. This module can be used to select key-shots in video and thus can be applied to video summarization. The extracted keyframes can be used as input to any deep learning-based classification model to recognize action. We also propose a plugin module to use the semantic word vector as input along with keyframes and a novel train/test strategy for the classification models. To our best knowledge, this is the first time such an online module and train/test strategy have been proposed. The experimental results on many commonly used datasets in video summarization and in action recognition have shown impressive results using the proposed module.