 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoDefense: Co-Evolving Black-Box Defense with Large Language Models
May 29, 2026Large Language Models (LLMs) remain highly vulnerable to diverse attacks, particularly in black-box settings where the internals of target models are inaccessible. Existing black-box defenses typically rely on pre-defined filtering heuristics, which often fail to generalize to unseen attack types and target model architectures. We introduce EvoDefense, an experience-guided co-evolving black-box defense paradigm. EvoDefense employs a guard LLM to detect malicious queries and an experience memory module to accumulate defense knowledge from previous interactions. At the core of EvoDefense is a continuous attack-defense evolution loop, where an attack generator and the guard model iteratively refine their attack strategies and defense policies through experience-guided optimization. This design enables EvoDefense to generalize across unseen attacks and target models without retraining. Experiments on HarmBench, AdvBench, and AlpacaEval show that EvoDefense achieves consistently strong defense performance across seven popular models and five representative LLM attacks, while preserving competitive general capabilities. On HarmBench, EvoDefense reduces the attack success rate (ASR) of AutoDAN-turbo on Gemini-3-flash and LLaMA-3-8B-Instruct from 29.4% and 43.4% to 8.4% and 6.2%, respectively.
FoCLIP: A Feature-Space Misalignment Framework for CLIP-Based Image Manipulation and Detection
Nov 10, 2025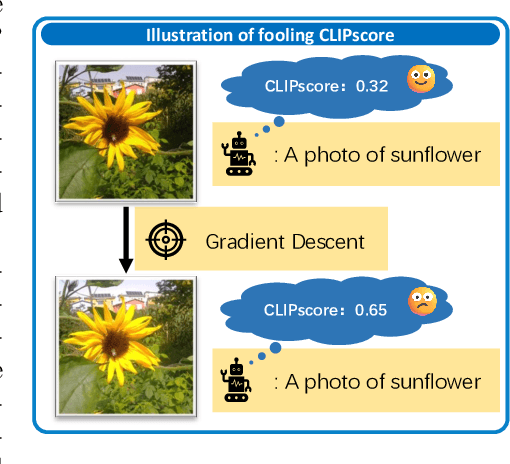
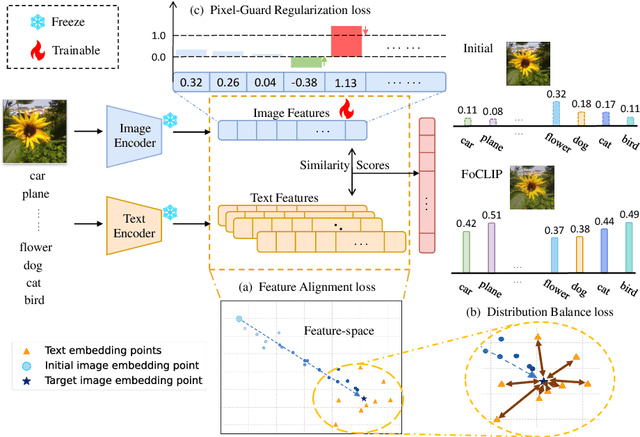
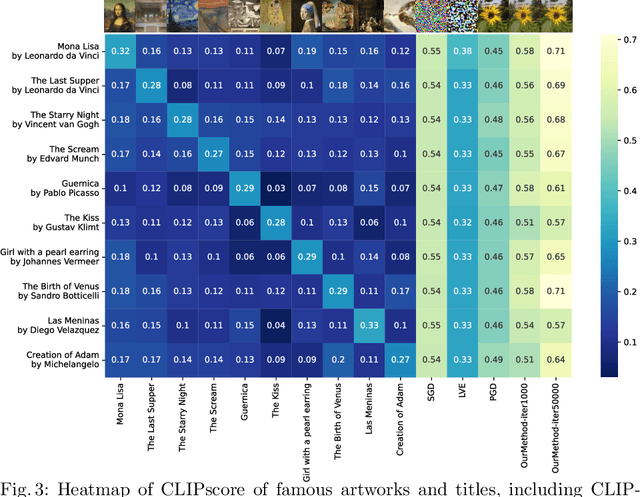
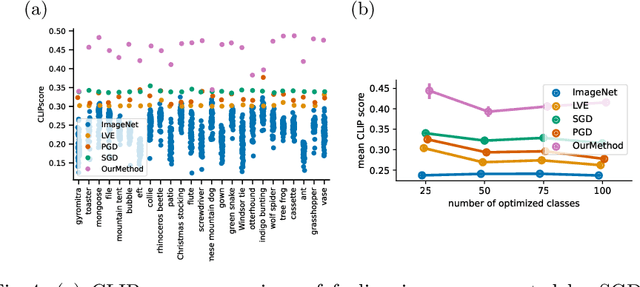
The well-aligned attribute of CLIP-based models enables its effective application like CLIPscore as a widely adopted image quality assessment metric. However, such a CLIP-based metric is vulnerable for its delicate multimodal alignment. In this work, we propose \textbf{FoCLIP}, a feature-space misalignment framework for fooling CLIP-based image quality metric. Based on the stochastic gradient descent technique, FoCLIP integrates three key components to construct fooling examples: feature alignment as the core module to reduce image-text modality gaps, the score distribution balance module and pixel-guard regularization, which collectively optimize multimodal output equilibrium between CLIPscore performance and image quality. Such a design can be engineered to maximize the CLIPscore predictions across diverse input prompts, despite exhibiting either visual unrecognizability or semantic incongruence with the corresponding adversarial prompts from human perceptual perspectives. Experiments on ten artistic masterpiece prompts and ImageNet subsets demonstrate that optimized images can achieve significant improvement in CLIPscore while preserving high visual fidelity. In addition, we found that grayscale conversion induces significant feature degradation in fooling images, exhibiting noticeable CLIPscore reduction while preserving statistical consistency with original images. Inspired by this phenomenon, we propose a color channel sensitivity-driven tampering detection mechanism that achieves 91% accuracy on standard benchmarks. In conclusion, this work establishes a practical pathway for feature misalignment in CLIP-based multimodal systems and the corresponding defense method.
SciceVPR: Stable Cross-Image Correlation Enhanced Model for Visual Place Recognition
Feb 28, 2025



Visual Place Recognition (VPR) is a major challenge for robotics and autonomous systems, with the goal of predicting the location of an image based solely on its visual features. State-of-the-art (SOTA) models extract global descriptors using the powerful foundation model DINOv2 as backbone. These models either explore the cross-image correlation or propose a time-consuming two-stage re-ranking strategy to achieve better performance. However, existing works only utilize the final output of DINOv2, and the current cross-image correlation causes unstable retrieval results. To produce both discriminative and constant global descriptors, this paper proposes stable cross-image correlation enhanced model for VPR called SciceVPR. This model explores the full potential of DINOv2 in providing useful feature representations that implicitly encode valuable contextual knowledge. Specifically, SciceVPR first uses a multi-layer feature fusion module to capture increasingly detailed task-relevant channel and spatial information from the multi-layer output of DINOv2. Secondly, SciceVPR considers the invariant correlation between images within a batch as valuable knowledge to be distilled into the proposed self-enhanced encoder. In this way, SciceVPR can acquire fairly robust global features regardless of domain shifts (e.g., changes in illumination, weather and viewpoint between pictures taken in the same place). Experimental results demonstrate that the base variant, SciceVPR-B, outperforms SOTA one-stage methods with single input on multiple datasets with varying domain conditions. The large variant, SciceVPR-L, performs on par with SOTA two-stage models, scoring over 3% higher in Recall@1 compared to existing models on the challenging Tokyo24/7 dataset. Our code will be released at https://github.com/shuimushan/SciceVPR.
PointCFormer: a Relation-based Progressive Feature Extraction Network for Point Cloud Completion
Dec 11, 2024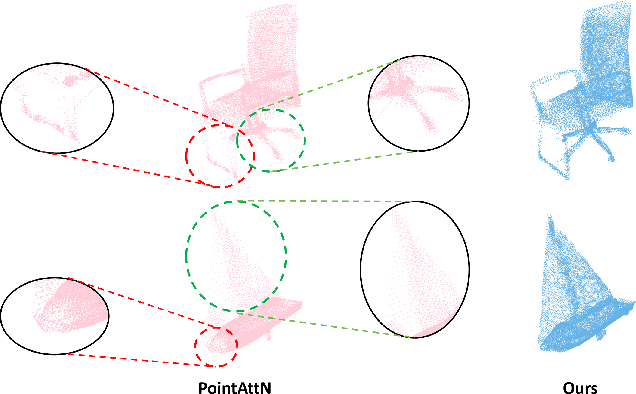
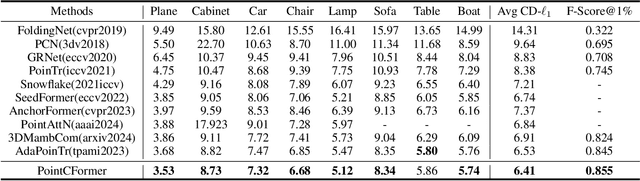
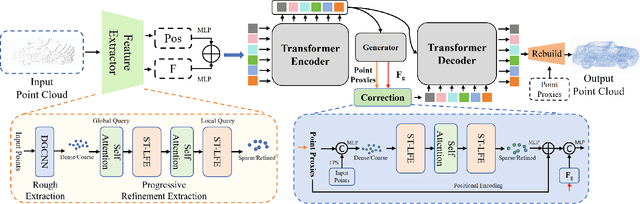
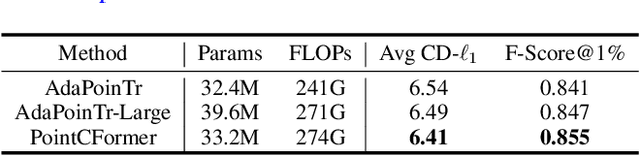
Point cloud completion aims to reconstruct the complete 3D shape from incomplete point clouds, and it is crucial for tasks such as 3D object detection and segmentation. Despite the continuous advances in point cloud analysis techniques, feature extraction methods are still confronted with apparent limitations. The sparse sampling of point clouds, used as inputs in most methods, often results in a certain loss of global structure information. Meanwhile, traditional local feature extraction methods usually struggle to capture the intricate geometric details. To overcome these drawbacks, we introduce PointCFormer, a transformer framework optimized for robust global retention and precise local detail capture in point cloud completion. This framework embraces several key advantages. First, we propose a relation-based local feature extraction method to perceive local delicate geometry characteristics. This approach establishes a fine-grained relationship metric between the target point and its k-nearest neighbors, quantifying each neighboring point's contribution to the target point's local features. Secondly, we introduce a progressive feature extractor that integrates our local feature perception method with self-attention. Starting with a denser sampling of points as input, it iteratively queries long-distance global dependencies and local neighborhood relationships. This extractor maintains enhanced global structure and refined local details, without generating substantial computational overhead. Additionally, we develop a correction module after generating point proxies in the latent space to reintroduce denser information from the input points, enhancing the representation capability of the point proxies. PointCFormer demonstrates state-of-the-art performance on several widely used benchmarks.
Cross Domain Object Detection via Multi-Granularity Confidence Alignment based Mean Teacher
Jul 10, 2024



Cross domain object detection learns an object detector for an unlabeled target domain by transferring knowledge from an annotated source domain. Promising results have been achieved via Mean Teacher, however, pseudo labeling which is the bottleneck of mutual learning remains to be further explored. In this study, we find that confidence misalignment of the predictions, including category-level overconfidence, instance-level task confidence inconsistency, and image-level confidence misfocusing, leading to the injection of noisy pseudo label in the training process, will bring suboptimal performance on the target domain. To tackle this issue, we present a novel general framework termed Multi-Granularity Confidence Alignment Mean Teacher (MGCAMT) for cross domain object detection, which alleviates confidence misalignment across category-, instance-, and image-levels simultaneously to obtain high quality pseudo supervision for better teacher-student learning. Specifically, to align confidence with accuracy at category level, we propose Classification Confidence Alignment (CCA) to model category uncertainty based on Evidential Deep Learning (EDL) and filter out the category incorrect labels via an uncertainty-aware selection strategy. Furthermore, to mitigate the instance-level misalignment between classification and localization, we design Task Confidence Alignment (TCA) to enhance the interaction between the two task branches and allow each classification feature to adaptively locate the optimal feature for the regression. Finally, we develop imagery Focusing Confidence Alignment (FCA) adopting another way of pseudo label learning, i.e., we use the original outputs from the Mean Teacher network for supervised learning without label assignment to concentrate on holistic information in the target image. These three procedures benefit from each other from a cooperative learning perspective.