 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFifty Years of SAR Automatic Target Recognition: The Road Forward
Sep 26, 2025This paper provides the first comprehensive review of fifty years of synthetic aperture radar automatic target recognition (SAR ATR) development, tracing its evolution from inception to the present day. Central to our analysis is the inheritance and refinement of traditional methods, such as statistical modeling, scattering center analysis, and feature engineering, within modern deep learning frameworks. The survey clearly distinguishes long-standing challenges that have been substantially mitigated by deep learning from newly emerging obstacles. We synthesize recent advances in physics-guided deep learning and propose future directions toward more generalizable and physically-consistent SAR ATR. Additionally, we provide a systematically organized compilation of all publicly available SAR datasets, complete with direct links to support reproducibility and benchmarking. This work not only documents the technical evolution of the field but also offers practical resources and forward-looking insights for researchers and practitioners. A systematic summary of existing literature, code, and datasets are open-sourced at \href{https://github.com/JoyeZLearning/SAR-ATR-From-Beginning-to-Present}{https://github.com/JoyeZLearning/SAR-ATR-From-Beginning-to-Present}.
On the Convergence of Muon and Beyond
Sep 19, 2025The Muon optimizer has demonstrated remarkable empirical success in handling matrix-structured parameters for training neural networks. However, a significant gap persists between its practical performance and theoretical understanding. Existing analyses indicate that the standard Muon variant achieves only a suboptimal convergence rate of $\mathcal{O}(T^{-1/4})$ in stochastic non-convex settings, where $T$ denotes the number of iterations. To explore the theoretical limits of the Muon framework, we construct and analyze a variance-reduced variant, termed Muon-VR2. We provide the first rigorous proof that incorporating a variance-reduction mechanism enables Muon-VR2 to attain an optimal convergence rate of $\tilde{\mathcal{O}}(T^{-1/3})$, thereby matching the theoretical lower bound for this class of problems. Moreover, our analysis establishes convergence guarantees for Muon variants under the Polyak-{\L}ojasiewicz (P{\L}) condition. Extensive experiments on vision (CIFAR-10) and language (C4) benchmarks corroborate our theoretical findings on per-iteration convergence. Overall, this work provides the first proof of optimality for a Muon-style optimizer and clarifies the path toward developing more practically efficient, accelerated variants.
A Reverse Causal Framework to Mitigate Spurious Correlations for Debiasing Scene Graph Generation
May 29, 2025Existing two-stage Scene Graph Generation (SGG) frameworks typically incorporate a detector to extract relationship features and a classifier to categorize these relationships; therefore, the training paradigm follows a causal chain structure, where the detector's inputs determine the classifier's inputs, which in turn influence the final predictions. However, such a causal chain structure can yield spurious correlations between the detector's inputs and the final predictions, i.e., the prediction of a certain relationship may be influenced by other relationships. This influence can induce at least two observable biases: tail relationships are predicted as head ones, and foreground relationships are predicted as background ones; notably, the latter bias is seldom discussed in the literature. To address this issue, we propose reconstructing the causal chain structure into a reverse causal structure, wherein the classifier's inputs are treated as the confounder, and both the detector's inputs and the final predictions are viewed as causal variables. Specifically, we term the reconstructed causal paradigm as the Reverse causal Framework for SGG (RcSGG). RcSGG initially employs the proposed Active Reverse Estimation (ARE) to intervene on the confounder to estimate the reverse causality, \ie the causality from final predictions to the classifier's inputs. Then, the Maximum Information Sampling (MIS) is suggested to enhance the reverse causality estimation further by considering the relationship information. Theoretically, RcSGG can mitigate the spurious correlations inherent in the SGG framework, subsequently eliminating the induced biases. Comprehensive experiments on popular benchmarks and diverse SGG frameworks show the state-of-the-art mean recall rate.
SAR-GTR: Attributed Scattering Information Guided SAR Graph Transformer Recognition Algorithm
May 13, 2025Utilizing electromagnetic scattering information for SAR data interpretation is currently a prominent research focus in the SAR interpretation domain. Graph Neural Networks (GNNs) can effectively integrate domain-specific physical knowledge and human prior knowledge, thereby alleviating challenges such as limited sample availability and poor generalization in SAR interpretation. In this study, we thoroughly investigate the electromagnetic inverse scattering information of single-channel SAR and re-examine the limitations of applying GNNs to SAR interpretation. We propose the SAR Graph Transformer Recognition Algorithm (SAR-GTR). SAR-GTR carefully considers the attributes and characteristics of different electromagnetic scattering parameters by distinguishing the mapping methods for discrete and continuous parameters, thereby avoiding information confusion and loss. Furthermore, the GTR combines GNNs with the Transformer mechanism and introduces an edge information enhancement channel to facilitate interactive learning of node and edge features, enabling the capture of robust and global structural characteristics of targets. Additionally, the GTR constructs a hierarchical topology-aware system through global node encoding and edge position encoding, fully exploiting the hierarchical structural information of targets. Finally, the effectiveness of the algorithm is validated using the ATRNet-STAR large-scale vehicle dataset.
Step-wise Distribution Alignment Guided Style Prompt Tuning for Source-free Cross-domain Few-shot Learning
Nov 15, 2024



Existing cross-domain few-shot learning (CDFSL) methods, which develop source-domain training strategies to enhance model transferability, face challenges with large-scale pre-trained models (LMs) due to inaccessible source data and training strategies. Moreover, fine-tuning LMs for CDFSL demands substantial computational resources, limiting practicality. This paper addresses the source-free CDFSL (SF-CDFSL) problem, tackling few-shot learning (FSL) in the target domain using only pre-trained models and a few target samples without source data or strategies. To overcome the challenge of inaccessible source data, this paper introduces Step-wise Distribution Alignment Guided Style Prompt Tuning (StepSPT), which implicitly narrows domain gaps through prediction distribution optimization. StepSPT proposes a style prompt to align target samples with the desired distribution and adopts a dual-phase optimization process. In the external process, a step-wise distribution alignment strategy factorizes prediction distribution optimization into a multi-step alignment problem to tune the style prompt. In the internal process, the classifier is updated using standard cross-entropy loss. Evaluations on five datasets demonstrate that StepSPT outperforms existing prompt tuning-based methods and SOTAs. Ablation studies further verify its effectiveness. Code will be made publicly available at \url{https://github.com/xuhuali-mxj/StepSPT}.
MaDiNet: Mamba Diffusion Network for SAR Target Detection
Nov 12, 2024



The fundamental challenge in SAR target detection lies in developing discriminative, efficient, and robust representations of target characteristics within intricate non-cooperative environments. However, accurate target detection is impeded by factors including the sparse distribution and discrete features of the targets, as well as complex background interference. In this study, we propose a \textbf{Ma}mba \textbf{Di}ffusion \textbf{Net}work (MaDiNet) for SAR target detection. Specifically, MaDiNet conceptualizes SAR target detection as the task of generating the position (center coordinates) and size (width and height) of the bounding boxes in the image space. Furthermore, we design a MambaSAR module to capture intricate spatial structural information of targets and enhance the capability of the model to differentiate between targets and complex backgrounds. The experimental results on extensive SAR target detection datasets achieve SOTA, proving the effectiveness of the proposed network. Code is available at \href{https://github.com/JoyeZLearning/MaDiNet}{https://github.com/JoyeZLearning/MaDiNet}.
UEVAVD: A Dataset for Developing UAV's Eye View Active Object Detection
Nov 07, 2024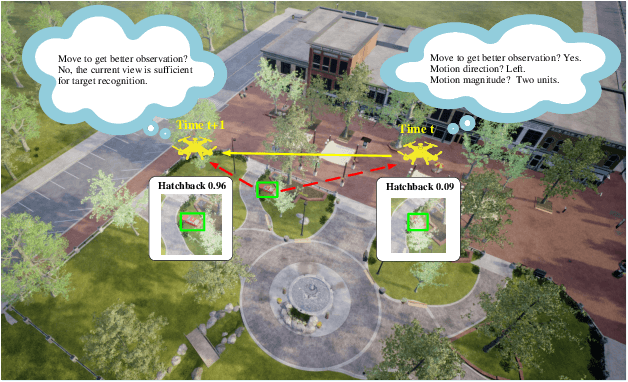
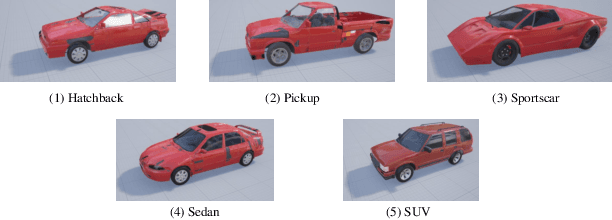
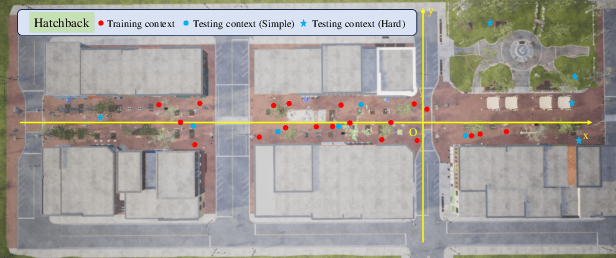
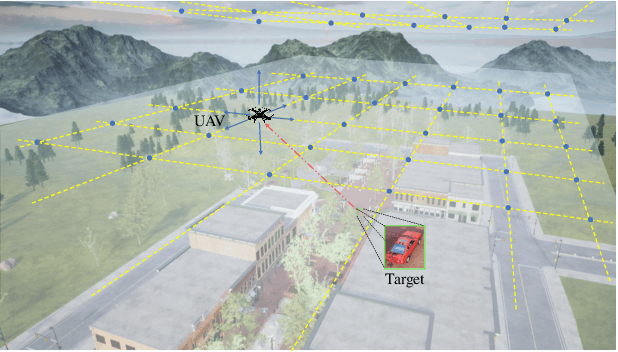
Occlusion is a longstanding difficulty that challenges the UAV-based object detection. Many works address this problem by adapting the detection model. However, few of them exploit that the UAV could fundamentally improve detection performance by changing its viewpoint. Active Object Detection (AOD) offers an effective way to achieve this purpose. Through Deep Reinforcement Learning (DRL), AOD endows the UAV with the ability of autonomous path planning to search for the observation that is more conducive to target identification. Unfortunately, there exists no available dataset for developing the UAV AOD method. To fill this gap, we released a UAV's eye view active vision dataset named UEVAVD and hope it can facilitate research on the UAV AOD problem. Additionally, we improve the existing DRL-based AOD method by incorporating the inductive bias when learning the state representation. First, due to the partial observability, we use the gated recurrent unit to extract state representations from the observation sequence instead of the single-view observation. Second, we pre-decompose the scene with the Segment Anything Model (SAM) and filter out the irrelevant information with the derived masks. With these practices, the agent could learn an active viewing policy with better generalization capability. The effectiveness of our innovations is validated by the experiments on the UEVAVD dataset. Our dataset will soon be available at https://github.com/Leo000ooo/UEVAVD_dataset.
Enhancing Transferability of Targeted Adversarial Examples: A Self-Universal Perspective
Jul 22, 2024Transfer-based targeted adversarial attacks against black-box deep neural networks (DNNs) have been proven to be significantly more challenging than untargeted ones. The impressive transferability of current SOTA, the generative methods, comes at the cost of requiring massive amounts of additional data and time-consuming training for each targeted label. This results in limited efficiency and flexibility, significantly hindering their deployment in practical applications. In this paper, we offer a self-universal perspective that unveils the great yet underexplored potential of input transformations in pursuing this goal. Specifically, transformations universalize gradient-based attacks with intrinsic but overlooked semantics inherent within individual images, exhibiting similar scalability and comparable results to time-consuming learning over massive additional data from diverse classes. We also contribute a surprising empirical insight that one of the most fundamental transformations, simple image scaling, is highly effective, scalable, sufficient, and necessary in enhancing targeted transferability. We further augment simple scaling with orthogonal transformations and block-wise applicability, resulting in the Simple, faSt, Self-universal yet Strong Scale Transformation (S$^4$ST) for self-universal TTA. On the ImageNet-Compatible benchmark dataset, our method achieves a 19.8% improvement in the average targeted transfer success rate against various challenging victim models over existing SOTA transformation methods while only consuming 36% time for attacking. It also outperforms resource-intensive attacks by a large margin in various challenging settings.
Cross Domain Object Detection via Multi-Granularity Confidence Alignment based Mean Teacher
Jul 10, 2024



Cross domain object detection learns an object detector for an unlabeled target domain by transferring knowledge from an annotated source domain. Promising results have been achieved via Mean Teacher, however, pseudo labeling which is the bottleneck of mutual learning remains to be further explored. In this study, we find that confidence misalignment of the predictions, including category-level overconfidence, instance-level task confidence inconsistency, and image-level confidence misfocusing, leading to the injection of noisy pseudo label in the training process, will bring suboptimal performance on the target domain. To tackle this issue, we present a novel general framework termed Multi-Granularity Confidence Alignment Mean Teacher (MGCAMT) for cross domain object detection, which alleviates confidence misalignment across category-, instance-, and image-levels simultaneously to obtain high quality pseudo supervision for better teacher-student learning. Specifically, to align confidence with accuracy at category level, we propose Classification Confidence Alignment (CCA) to model category uncertainty based on Evidential Deep Learning (EDL) and filter out the category incorrect labels via an uncertainty-aware selection strategy. Furthermore, to mitigate the instance-level misalignment between classification and localization, we design Task Confidence Alignment (TCA) to enhance the interaction between the two task branches and allow each classification feature to adaptively locate the optimal feature for the regression. Finally, we develop imagery Focusing Confidence Alignment (FCA) adopting another way of pseudo label learning, i.e., we use the original outputs from the Mean Teacher network for supervised learning without label assignment to concentrate on holistic information in the target image. These three procedures benefit from each other from a cooperative learning perspective.
SARATR-X: A Foundation Model for Synthetic Aperture Radar Images Target Recognition
May 15, 2024

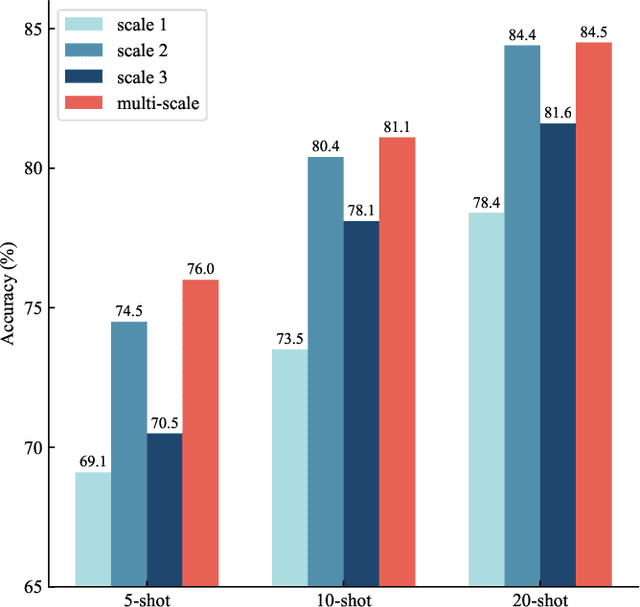

Synthetic aperture radar (SAR) is essential in actively acquiring information for Earth observation. SAR Automatic Target Recognition (ATR) focuses on detecting and classifying various target categories under different image conditions. The current deep learning-based SAR ATR methods are typically designed for specific datasets and applications. Various target characteristics, scene background information, and sensor parameters across ATR datasets challenge the generalization of those methods. This paper aims to achieve general SAR ATR based on a foundation model with Self-Supervised Learning (SSL). Our motivation is to break through the specific dataset and condition limitations and obtain universal perceptual capabilities across the target, scene, and sensor. A foundation model named SARATR-X is proposed with the following four aspects: pre-training dataset, model backbone, SSL, and evaluation task. First, we integrated 14 datasets with various target categories and imaging conditions as a pre-training dataset. Second, different model backbones were discussed to find the most suitable approaches for remote-sensing images. Third, we applied two-stage training and SAR gradient features to ensure the diversity and scalability of SARATR-X. Finally, SARATR-X has achieved competitive and superior performance on 5 datasets with 8 task settings, which shows that the foundation model can achieve universal SAR ATR. We believe it is time to embrace fundamental models for SAR image interpretation in the era of increasing big data.