 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards UAV Detection in the Real World: A New Multispectral Dataset UAVNet-MS and a New Method
May 20, 2026The proliferation of unmanned aerial vehicles (UAVs) has created urgent demand for precise UAV monitoring. Existing RGB-based systems rely on spatial cues that degrade at small scales, particularly with high inter-type similarity, target-clutter ambiguity, and low contrast. Multispectral imaging (MSI) encodes material-aware spectral signatures, yet MSI-based fine-grained small-UAV detection remains underexplored due to lack of dedicated datasets. We introduce UAVNet-MS, the first multispectral dataset for fine-grained small-UAV detection, comprising 15,618 temporally synchronized RGB-MSI data cubes (1440x1080) with bounding box annotations. The dataset features challenging small objects (93.7% <= 32^2 pixels, average 18^2 pixels, ~0.02% image area) under low contrast. We propose MFDNet, a dual-stream baseline addressing array-induced parallax and spatial-spectral fusion. Extensive evaluation under RGB-only, MSI-only, and RGB+MSI protocols against 20 detectors shows MFDNet achieves +6.2% AP50 improvement over best RGB-only methods, demonstrating spectral cues provide complementary material evidence beyond spatial cues. This work provides foundational dataset, strong baseline, and benchmark for multispectral UAV monitoring research.
Dynamic High-frequency Convolution for Infrared Small Target Detection
Feb 03, 2026Infrared small targets are typically tiny and locally salient, which belong to high-frequency components (HFCs) in images. Single-frame infrared small target (SIRST) detection is challenging, since there are many HFCs along with targets, such as bright corners, broken clouds, and other clutters. Current learning-based methods rely on the powerful capabilities of deep networks, but neglect explicit modeling and discriminative representation learning of various HFCs, which is important to distinguish targets from other HFCs. To address the aforementioned issues, we propose a dynamic high-frequency convolution (DHiF) to translate the discriminative modeling process into the generation of a dynamic local filter bank. Especially, DHiF is sensitive to HFCs, owing to the dynamic parameters of its generated filters being symmetrically adjusted within a zero-centered range according to Fourier transformation properties. Combining with standard convolution operations, DHiF can adaptively and dynamically process different HFC regions and capture their distinctive grayscale variation characteristics for discriminative representation learning. DHiF functions as a drop-in replacement for standard convolution and can be used in arbitrary SIRST detection networks without significant decrease in computational efficiency. To validate the effectiveness of our DHiF, we conducted extensive experiments across different SIRST detection networks on real-scene datasets. Compared to other state-of-the-art convolution operations, DHiF exhibits superior detection performance with promising improvement. Codes are available at https://github.com/TinaLRJ/DHiF.
Embodied Neuromorphic Control Applied on a 7-DOF Robotic Manipulator
Apr 17, 2025



The development of artificial intelligence towards real-time interaction with the environment is a key aspect of embodied intelligence and robotics. Inverse dynamics is a fundamental robotics problem, which maps from joint space to torque space of robotic systems. Traditional methods for solving it rely on direct physical modeling of robots which is difficult or even impossible due to nonlinearity and external disturbance. Recently, data-based model-learning algorithms are adopted to address this issue. However, they often require manual parameter tuning and high computational costs. Neuromorphic computing is inherently suitable to process spatiotemporal features in robot motion control at extremely low costs. However, current research is still in its infancy: existing works control only low-degree-of-freedom systems and lack performance quantification and comparison. In this paper, we propose a neuromorphic control framework to control 7 degree-of-freedom robotic manipulators. We use Spiking Neural Network to leverage the spatiotemporal continuity of the motion data to improve control accuracy, and eliminate manual parameters tuning. We validated the algorithm on two robotic platforms, which reduces torque prediction error by at least 60% and performs a target position tracking task successfully. This work advances embodied neuromorphic control by one step forward from proof of concept to applications in complex real-world tasks.
A Neural Symbolic Model for Space Physics
Mar 11, 2025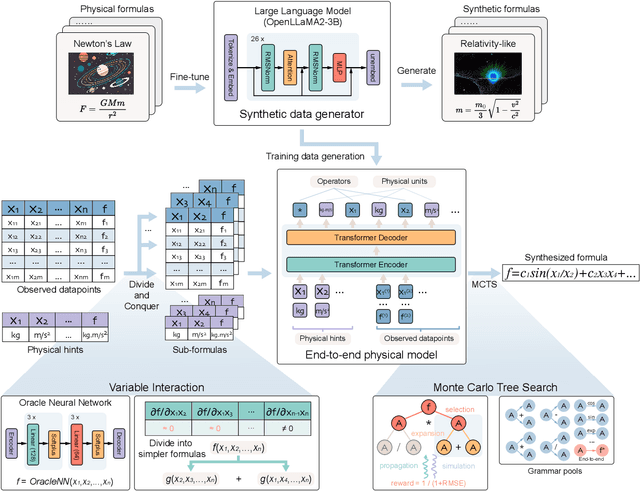
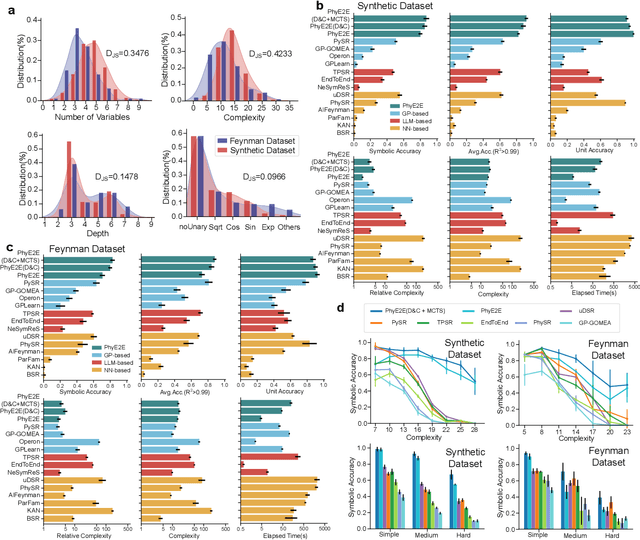
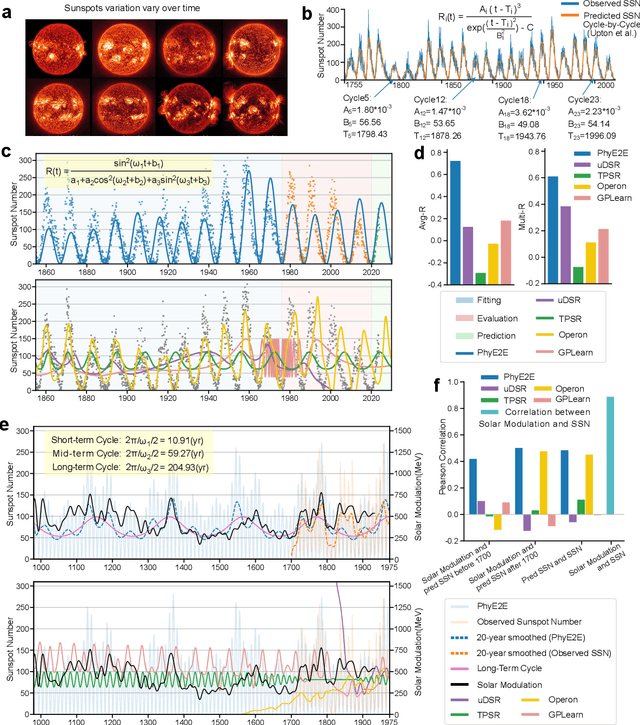
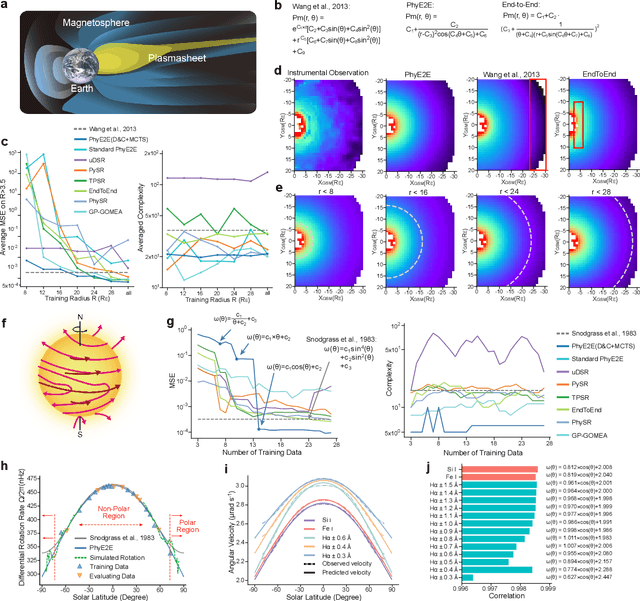
In this study, we unveil a new AI model, termed PhyE2E, to discover physical formulas through symbolic regression. PhyE2E simplifies symbolic regression by decomposing it into sub-problems using the second-order derivatives of an oracle neural network, and employs a transformer model to translate data into symbolic formulas in an end-to-end manner. The resulting formulas are refined through Monte-Carlo Tree Search and Genetic Programming. We leverage a large language model to synthesize extensive symbolic expressions resembling real physics, and train the model to recover these formulas directly from data. A comprehensive evaluation reveals that PhyE2E outperforms existing state-of-the-art approaches, delivering superior symbolic accuracy, precision in data fitting, and consistency in physical units. We deployed PhyE2E to five applications in space physics, including the prediction of sunspot numbers, solar rotational angular velocity, emission line contribution functions, near-Earth plasma pressure, and lunar-tide plasma signals. The physical formulas generated by AI demonstrate a high degree of accuracy in fitting the experimental data from satellites and astronomical telescopes. We have successfully upgraded the formula proposed by NASA in 1993 regarding solar activity, and for the first time, provided the explanations for the long cycle of solar activity in an explicit form. We also found that the decay of near-Earth plasma pressure is proportional to r^2 to Earth, where subsequent mathematical derivations are consistent with satellite data from another independent study. Moreover, we found physical formulas that can describe the relationships between emission lines in the extreme ultraviolet spectrum of the Sun, temperatures, electron densities, and magnetic fields. The formula obtained is consistent with the properties that physicists had previously hypothesized it should possess.
Heterogeneous Graph Transformer for Multiple Tiny Object Tracking in RGB-T Videos
Dec 14, 2024



Tracking multiple tiny objects is highly challenging due to their weak appearance and limited features. Existing multi-object tracking algorithms generally focus on single-modality scenes, and overlook the complementary characteristics of tiny objects captured by multiple remote sensors. To enhance tracking performance by integrating complementary information from multiple sources, we propose a novel framework called {HGT-Track (Heterogeneous Graph Transformer based Multi-Tiny-Object Tracking)}. Specifically, we first employ a Transformer-based encoder to embed images from different modalities. Subsequently, we utilize Heterogeneous Graph Transformer to aggregate spatial and temporal information from multiple modalities to generate detection and tracking features. Additionally, we introduce a target re-detection module (ReDet) to ensure tracklet continuity by maintaining consistency across different modalities. Furthermore, this paper introduces the first benchmark VT-Tiny-MOT (Visible-Thermal Tiny Multi-Object Tracking) for RGB-T fused multiple tiny object tracking. Extensive experiments are conducted on VT-Tiny-MOT, and the results have demonstrated the effectiveness of our method. Compared to other state-of-the-art methods, our method achieves better performance in terms of MOTA (Multiple-Object Tracking Accuracy) and ID-F1 score. The code and dataset will be made available at https://github.com/xuqingyu26/HGTMT.
MaDiNet: Mamba Diffusion Network for SAR Target Detection
Nov 12, 2024



The fundamental challenge in SAR target detection lies in developing discriminative, efficient, and robust representations of target characteristics within intricate non-cooperative environments. However, accurate target detection is impeded by factors including the sparse distribution and discrete features of the targets, as well as complex background interference. In this study, we propose a \textbf{Ma}mba \textbf{Di}ffusion \textbf{Net}work (MaDiNet) for SAR target detection. Specifically, MaDiNet conceptualizes SAR target detection as the task of generating the position (center coordinates) and size (width and height) of the bounding boxes in the image space. Furthermore, we design a MambaSAR module to capture intricate spatial structural information of targets and enhance the capability of the model to differentiate between targets and complex backgrounds. The experimental results on extensive SAR target detection datasets achieve SOTA, proving the effectiveness of the proposed network. Code is available at \href{https://github.com/JoyeZLearning/MaDiNet}{https://github.com/JoyeZLearning/MaDiNet}.
Visible-Thermal Tiny Object Detection: A Benchmark Dataset and Baselines
Jun 20, 2024



Small object detection (SOD) has been a longstanding yet challenging task for decades, with numerous datasets and algorithms being developed. However, they mainly focus on either visible or thermal modality, while visible-thermal (RGBT) bimodality is rarely explored. Although some RGBT datasets have been developed recently, the insufficient quantity, limited category, misaligned images and large target size cannot provide an impartial benchmark to evaluate multi-category visible-thermal small object detection (RGBT SOD) algorithms. In this paper, we build the first large-scale benchmark with high diversity for RGBT SOD (namely RGBT-Tiny), including 115 paired sequences, 93K frames and 1.2M manual annotations. RGBT-Tiny contains abundant targets (7 categories) and high-diversity scenes (8 types that cover different illumination and density variations). Note that, over 81% of targets are smaller than 16x16, and we provide paired bounding box annotations with tracking ID to offer an extremely challenging benchmark with wide-range applications, such as RGBT fusion, detection and tracking. In addition, we propose a scale adaptive fitness (SAFit) measure that exhibits high robustness on both small and large targets. The proposed SAFit can provide reasonable performance evaluation and promote detection performance. Based on the proposed RGBT-Tiny dataset and SAFit measure, extensive evaluations have been conducted, including 23 recent state-of-the-art algorithms that cover four different types (i.e., visible generic detection, visible SOD, thermal SOD and RGBT object detection). Project is available at https://github.com/XinyiYing24/RGBT-Tiny.
You Only Train Once: Learning a General Anomaly Enhancement Network with Random Masks for Hyperspectral Anomaly Detection
Mar 31, 2023



In this paper, we introduce a new approach to address the challenge of generalization in hyperspectral anomaly detection (AD). Our method eliminates the need for adjusting parameters or retraining on new test scenes as required by most existing methods. Employing an image-level training paradigm, we achieve a general anomaly enhancement network for hyperspectral AD that only needs to be trained once. Trained on a set of anomaly-free hyperspectral images with random masks, our network can learn the spatial context characteristics between anomalies and background in an unsupervised way. Additionally, a plug-and-play model selection module is proposed to search for a spatial-spectral transform domain that is more suitable for AD task than the original data. To establish a unified benchmark to comprehensively evaluate our method and existing methods, we develop a large-scale hyperspectral AD dataset (HAD100) that includes 100 real test scenes with diverse anomaly targets. In comparison experiments, we combine our network with a parameter-free detector and achieve the optimal balance between detection accuracy and inference speed among state-of-the-art AD methods. Experimental results also show that our method still achieves competitive performance when the training and test set are captured by different sensor devices. Our code is available at https://github.com/ZhaoxuLi123/AETNet.
MTU-Net: Multi-level TransUNet for Space-based Infrared Tiny Ship Detection
Sep 28, 2022
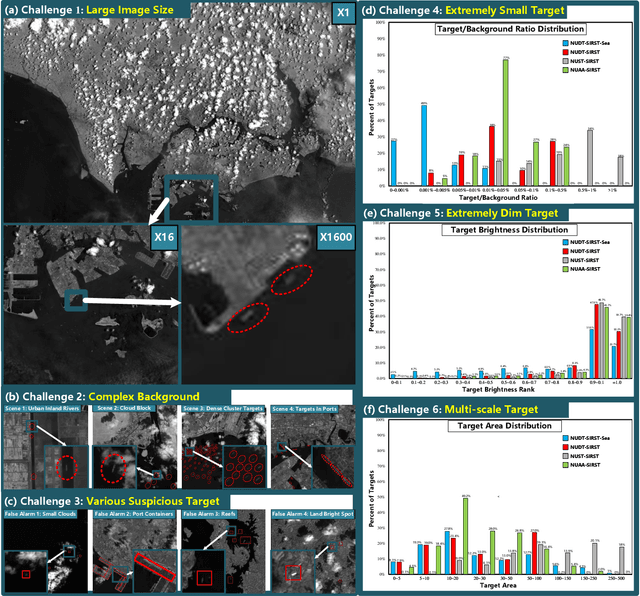
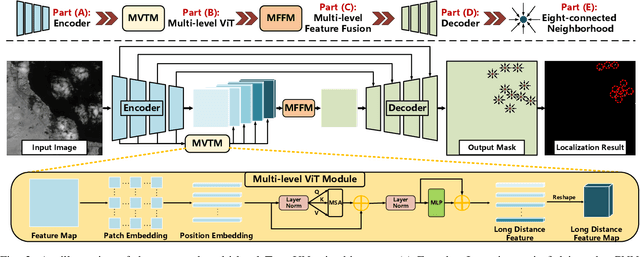
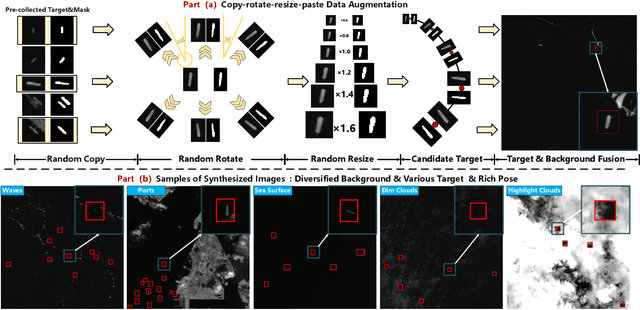
Space-based infrared tiny ship detection aims at separating tiny ships from the images captured by earth orbiting satellites. Due to the extremely large image coverage area (e.g., thousands square kilometers), candidate targets in these images are much smaller, dimer, more changeable than those targets observed by aerial-based and land-based imaging devices. Existing short imaging distance-based infrared datasets and target detection methods cannot be well adopted to the space-based surveillance task. To address these problems, we develop a space-based infrared tiny ship detection dataset (namely, NUDT-SIRST-Sea) with 48 space-based infrared images and 17598 pixel-level tiny ship annotations. Each image covers about 10000 square kilometers of area with 10000X10000 pixels. Considering the extreme characteristics (e.g., small, dim, changeable) of those tiny ships in such challenging scenes, we propose a multi-level TransUNet (MTU-Net) in this paper. Specifically, we design a Vision Transformer (ViT) Convolutional Neural Network (CNN) hybrid encoder to extract multi-level features. Local feature maps are first extracted by several convolution layers and then fed into the multi-level feature extraction module (MVTM) to capture long-distance dependency. We further propose a copy-rotate-resize-paste (CRRP) data augmentation approach to accelerate the training phase, which effectively alleviates the issue of sample imbalance between targets and background. Besides, we design a FocalIoU loss to achieve both target localization and shape description. Experimental results on the NUDT-SIRST-Sea dataset show that our MTU-Net outperforms traditional and existing deep learning based SIRST methods in terms of probability of detection, false alarm rate and intersection over union.
Dense Dual-Attention Network for Light Field Image Super-Resolution
Oct 23, 2021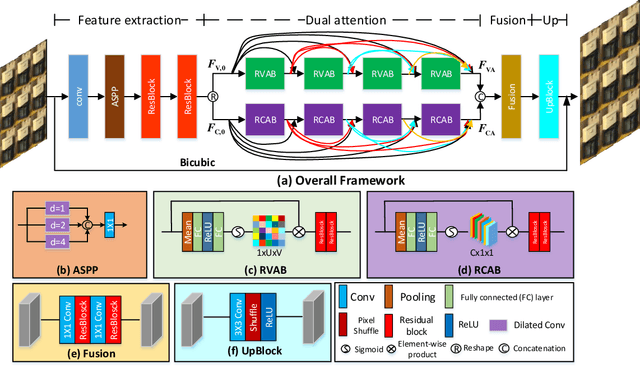
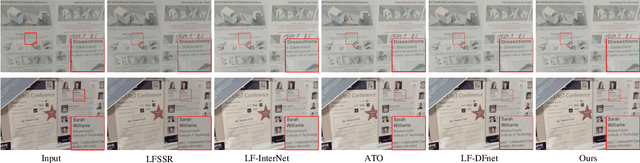

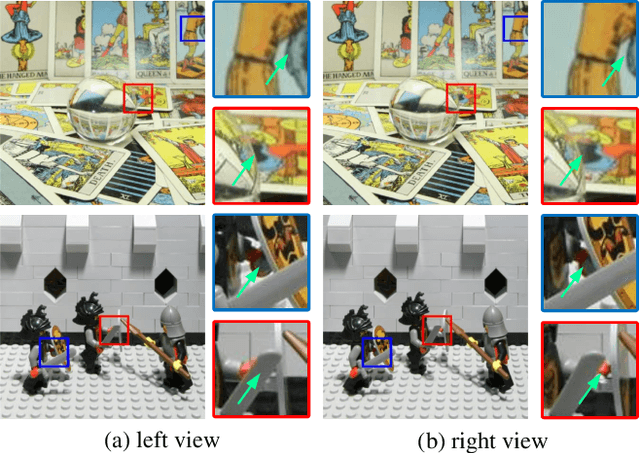
Light field (LF) images can be used to improve the performance of image super-resolution (SR) because both angular and spatial information is available. It is challenging to incorporate distinctive information from different views for LF image SR. Moreover, the long-term information from the previous layers can be weakened as the depth of network increases. In this paper, we propose a dense dual-attention network for LF image SR. Specifically, we design a view attention module to adaptively capture discriminative features across different views and a channel attention module to selectively focus on informative information across all channels. These two modules are fed to two branches and stacked separately in a chain structure for adaptive fusion of hierarchical features and distillation of valid information. Meanwhile, a dense connection is used to fully exploit multi-level information. Extensive experiments demonstrate that our dense dual-attention mechanism can capture informative information across views and channels to improve SR performance. Comparative results show the advantage of our method over state-of-the-art methods on public datasets.