 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRescue: A UAV-Based Dataset and Enhanced YOLO Model for Object Detection in Fire Rescue Scenes
Dec 31, 2025Object detection in fire rescue scenarios is importance for command and decision-making in firefighting operations. However, existing research still suffers from two main limitations. First, current work predominantly focuses on environments such as mountainous or forest areas, while paying insufficient attention to urban rescue scenes, which are more frequent and structurally complex. Second, existing detection systems include a limited number of classes, such as flames and smoke, and lack a comprehensive system covering key targets crucial for command decisions, such as fire trucks and firefighters. To address the above issues, this paper first constructs a new dataset named "FireRescue" for rescue command, which covers multiple rescue scenarios, including urban, mountainous, forest, and water areas, and contains eight key categories such as fire trucks and firefighters, with a total of 15,980 images and 32,000 bounding boxes. Secondly, to tackle the problems of inter-class confusion and missed detection of small targets caused by chaotic scenes, diverse targets, and long-distance shooting, this paper proposes an improved model named FRS-YOLO. On the one hand, the model introduces a plug-and-play multidi-mensional collaborative enhancement attention module, which enhances the discriminative representation of easily confused categories (e.g., fire trucks vs. ordinary trucks) through cross-dimensional feature interaction. On the other hand, it integrates a dynamic feature sampler to strengthen high-response foreground features, thereby mitigating the effects of smoke occlusion and background interference. Experimental results demonstrate that object detection in fire rescue scenarios is highly challenging, and the proposed method effectively improves the detection performance of YOLO series models in this context.
Heterogeneous Graph Transformer for Multiple Tiny Object Tracking in RGB-T Videos
Dec 14, 2024



Tracking multiple tiny objects is highly challenging due to their weak appearance and limited features. Existing multi-object tracking algorithms generally focus on single-modality scenes, and overlook the complementary characteristics of tiny objects captured by multiple remote sensors. To enhance tracking performance by integrating complementary information from multiple sources, we propose a novel framework called {HGT-Track (Heterogeneous Graph Transformer based Multi-Tiny-Object Tracking)}. Specifically, we first employ a Transformer-based encoder to embed images from different modalities. Subsequently, we utilize Heterogeneous Graph Transformer to aggregate spatial and temporal information from multiple modalities to generate detection and tracking features. Additionally, we introduce a target re-detection module (ReDet) to ensure tracklet continuity by maintaining consistency across different modalities. Furthermore, this paper introduces the first benchmark VT-Tiny-MOT (Visible-Thermal Tiny Multi-Object Tracking) for RGB-T fused multiple tiny object tracking. Extensive experiments are conducted on VT-Tiny-MOT, and the results have demonstrated the effectiveness of our method. Compared to other state-of-the-art methods, our method achieves better performance in terms of MOTA (Multiple-Object Tracking Accuracy) and ID-F1 score. The code and dataset will be made available at https://github.com/xuqingyu26/HGTMT.
Visible-Thermal Tiny Object Detection: A Benchmark Dataset and Baselines
Jun 20, 2024



Small object detection (SOD) has been a longstanding yet challenging task for decades, with numerous datasets and algorithms being developed. However, they mainly focus on either visible or thermal modality, while visible-thermal (RGBT) bimodality is rarely explored. Although some RGBT datasets have been developed recently, the insufficient quantity, limited category, misaligned images and large target size cannot provide an impartial benchmark to evaluate multi-category visible-thermal small object detection (RGBT SOD) algorithms. In this paper, we build the first large-scale benchmark with high diversity for RGBT SOD (namely RGBT-Tiny), including 115 paired sequences, 93K frames and 1.2M manual annotations. RGBT-Tiny contains abundant targets (7 categories) and high-diversity scenes (8 types that cover different illumination and density variations). Note that, over 81% of targets are smaller than 16x16, and we provide paired bounding box annotations with tracking ID to offer an extremely challenging benchmark with wide-range applications, such as RGBT fusion, detection and tracking. In addition, we propose a scale adaptive fitness (SAFit) measure that exhibits high robustness on both small and large targets. The proposed SAFit can provide reasonable performance evaluation and promote detection performance. Based on the proposed RGBT-Tiny dataset and SAFit measure, extensive evaluations have been conducted, including 23 recent state-of-the-art algorithms that cover four different types (i.e., visible generic detection, visible SOD, thermal SOD and RGBT object detection). Project is available at https://github.com/XinyiYing24/RGBT-Tiny.
Unsupervised Degradation Representation Learning for Blind Super-Resolution
Apr 01, 2021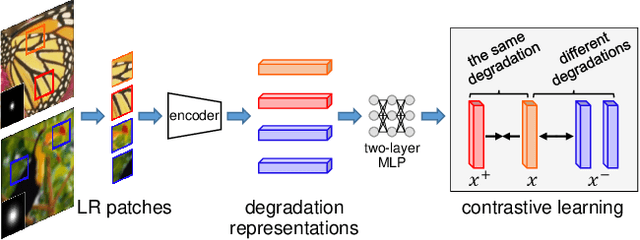

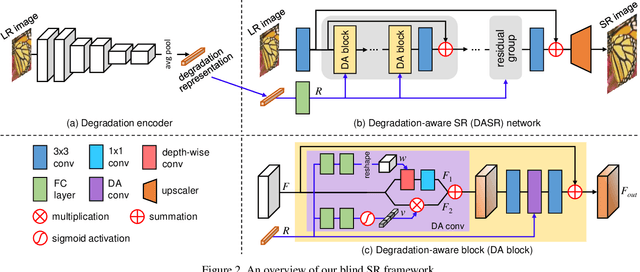
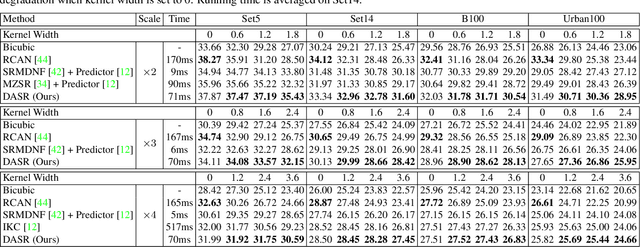
Most existing CNN-based super-resolution (SR) methods are developed based on an assumption that the degradation is fixed and known (e.g., bicubic downsampling). However, these methods suffer a severe performance drop when the real degradation is different from their assumption. To handle various unknown degradations in real-world applications, previous methods rely on degradation estimation to reconstruct the SR image. Nevertheless, degradation estimation methods are usually time-consuming and may lead to SR failure due to large estimation errors. In this paper, we propose an unsupervised degradation representation learning scheme for blind SR without explicit degradation estimation. Specifically, we learn abstract representations to distinguish various degradations in the representation space rather than explicit estimation in the pixel space. Moreover, we introduce a Degradation-Aware SR (DASR) network with flexible adaption to various degradations based on the learned representations. It is demonstrated that our degradation representation learning scheme can extract discriminative representations to obtain accurate degradation information. Experiments on both synthetic and real images show that our network achieves state-of-the-art performance for the blind SR task. Code is available at: https://github.com/LongguangWang/DASR.