 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic High-frequency Convolution for Infrared Small Target Detection
Feb 03, 2026Infrared small targets are typically tiny and locally salient, which belong to high-frequency components (HFCs) in images. Single-frame infrared small target (SIRST) detection is challenging, since there are many HFCs along with targets, such as bright corners, broken clouds, and other clutters. Current learning-based methods rely on the powerful capabilities of deep networks, but neglect explicit modeling and discriminative representation learning of various HFCs, which is important to distinguish targets from other HFCs. To address the aforementioned issues, we propose a dynamic high-frequency convolution (DHiF) to translate the discriminative modeling process into the generation of a dynamic local filter bank. Especially, DHiF is sensitive to HFCs, owing to the dynamic parameters of its generated filters being symmetrically adjusted within a zero-centered range according to Fourier transformation properties. Combining with standard convolution operations, DHiF can adaptively and dynamically process different HFC regions and capture their distinctive grayscale variation characteristics for discriminative representation learning. DHiF functions as a drop-in replacement for standard convolution and can be used in arbitrary SIRST detection networks without significant decrease in computational efficiency. To validate the effectiveness of our DHiF, we conducted extensive experiments across different SIRST detection networks on real-scene datasets. Compared to other state-of-the-art convolution operations, DHiF exhibits superior detection performance with promising improvement. Codes are available at https://github.com/TinaLRJ/DHiF.
Probing Deep into Temporal Profile Makes the Infrared Small Target Detector Much Better
Jun 15, 2025Infrared small target (IRST) detection is challenging in simultaneously achieving precise, universal, robust and efficient performance due to extremely dim targets and strong interference. Current learning-based methods attempt to leverage ``more" information from both the spatial and the short-term temporal domains, but suffer from unreliable performance under complex conditions while incurring computational redundancy. In this paper, we explore the ``more essential" information from a more crucial domain for the detection. Through theoretical analysis, we reveal that the global temporal saliency and correlation information in the temporal profile demonstrate significant superiority in distinguishing target signals from other signals. To investigate whether such superiority is preferentially leveraged by well-trained networks, we built the first prediction attribution tool in this field and verified the importance of the temporal profile information. Inspired by the above conclusions, we remodel the IRST detection task as a one-dimensional signal anomaly detection task, and propose an efficient deep temporal probe network (DeepPro) that only performs calculations in the time dimension for IRST detection. We conducted extensive experiments to fully validate the effectiveness of our method. The experimental results are exciting, as our DeepPro outperforms existing state-of-the-art IRST detection methods on widely-used benchmarks with extremely high efficiency, and achieves a significant improvement on dim targets and in complex scenarios. We provide a new modeling domain, a new insight, a new method, and a new performance, which can promote the development of IRST detection. Codes are available at https://github.com/TinaLRJ/DeepPro.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Heterogeneous Graph Transformer for Multiple Tiny Object Tracking in RGB-T Videos
Dec 14, 2024



Tracking multiple tiny objects is highly challenging due to their weak appearance and limited features. Existing multi-object tracking algorithms generally focus on single-modality scenes, and overlook the complementary characteristics of tiny objects captured by multiple remote sensors. To enhance tracking performance by integrating complementary information from multiple sources, we propose a novel framework called {HGT-Track (Heterogeneous Graph Transformer based Multi-Tiny-Object Tracking)}. Specifically, we first employ a Transformer-based encoder to embed images from different modalities. Subsequently, we utilize Heterogeneous Graph Transformer to aggregate spatial and temporal information from multiple modalities to generate detection and tracking features. Additionally, we introduce a target re-detection module (ReDet) to ensure tracklet continuity by maintaining consistency across different modalities. Furthermore, this paper introduces the first benchmark VT-Tiny-MOT (Visible-Thermal Tiny Multi-Object Tracking) for RGB-T fused multiple tiny object tracking. Extensive experiments are conducted on VT-Tiny-MOT, and the results have demonstrated the effectiveness of our method. Compared to other state-of-the-art methods, our method achieves better performance in terms of MOTA (Multiple-Object Tracking Accuracy) and ID-F1 score. The code and dataset will be made available at https://github.com/xuqingyu26/HGTMT.
Fire-Flyer AI-HPC: A Cost-Effective Software-Hardware Co-Design for Deep Learning
Aug 26, 2024



The rapid progress in Deep Learning (DL) and Large Language Models (LLMs) has exponentially increased demands of computational power and bandwidth. This, combined with the high costs of faster computing chips and interconnects, has significantly inflated High Performance Computing (HPC) construction costs. To address these challenges, we introduce the Fire-Flyer AI-HPC architecture, a synergistic hardware-software co-design framework and its best practices. For DL training, we deployed the Fire-Flyer 2 with 10,000 PCIe A100 GPUs, achieved performance approximating the DGX-A100 while reducing costs by half and energy consumption by 40%. We specifically engineered HFReduce to accelerate allreduce communication and implemented numerous measures to keep our Computation-Storage Integrated Network congestion-free. Through our software stack, including HaiScale, 3FS, and HAI-Platform, we achieved substantial scalability by overlapping computation and communication. Our system-oriented experience from DL training provides valuable insights to drive future advancements in AI-HPC.
Visible-Thermal Tiny Object Detection: A Benchmark Dataset and Baselines
Jun 20, 2024



Small object detection (SOD) has been a longstanding yet challenging task for decades, with numerous datasets and algorithms being developed. However, they mainly focus on either visible or thermal modality, while visible-thermal (RGBT) bimodality is rarely explored. Although some RGBT datasets have been developed recently, the insufficient quantity, limited category, misaligned images and large target size cannot provide an impartial benchmark to evaluate multi-category visible-thermal small object detection (RGBT SOD) algorithms. In this paper, we build the first large-scale benchmark with high diversity for RGBT SOD (namely RGBT-Tiny), including 115 paired sequences, 93K frames and 1.2M manual annotations. RGBT-Tiny contains abundant targets (7 categories) and high-diversity scenes (8 types that cover different illumination and density variations). Note that, over 81% of targets are smaller than 16x16, and we provide paired bounding box annotations with tracking ID to offer an extremely challenging benchmark with wide-range applications, such as RGBT fusion, detection and tracking. In addition, we propose a scale adaptive fitness (SAFit) measure that exhibits high robustness on both small and large targets. The proposed SAFit can provide reasonable performance evaluation and promote detection performance. Based on the proposed RGBT-Tiny dataset and SAFit measure, extensive evaluations have been conducted, including 23 recent state-of-the-art algorithms that cover four different types (i.e., visible generic detection, visible SOD, thermal SOD and RGBT object detection). Project is available at https://github.com/XinyiYing24/RGBT-Tiny.
SpecDETR: A Transformer-based Hyperspectral Point Object Detection Network
May 16, 2024



Hyperspectral target detection (HTD) aims to identify specific materials based on spectral information in hyperspectral imagery and can detect point targets, some of which occupy a smaller than one-pixel area. However, existing HTD methods are developed based on per-pixel binary classification, which limits the feature representation capability for point targets. In this paper, we rethink the hyperspectral point target detection from the object detection perspective, and focus more on the object-level prediction capability rather than the pixel classification capability. Inspired by the token-based processing flow of Detection Transformer (DETR), we propose the first specialized network for hyperspectral multi-class point object detection, SpecDETR. Without the backbone part of the current object detection framework, SpecDETR treats the spectral features of each pixel in hyperspectral images as a token and utilizes a multi-layer Transformer encoder with local and global coordination attention modules to extract deep spatial-spectral joint features. SpecDETR regards point object detection as a one-to-many set prediction problem, thereby achieving a concise and efficient DETR decoder that surpasses the current state-of-the-art DETR decoder in terms of parameters and accuracy in point object detection. We develop a simulated hyperSpectral Point Object Detection benchmark termed SPOD, and for the first time, evaluate and compare the performance of current object detection networks and HTD methods on hyperspectral multi-class point object detection. SpecDETR demonstrates superior performance as compared to current object detection networks and HTD methods on the SPOD dataset. Additionally, we validate on a public HTD dataset that by using data simulation instead of manual annotation, SpecDETR can detect real-world single-spectral point objects directly.
Monte Carlo Linear Clustering with Single-Point Supervision is Enough for Infrared Small Target Detection
Apr 10, 2023



Single-frame infrared small target (SIRST) detection aims at separating small targets from clutter backgrounds on infrared images. Recently, deep learning based methods have achieved promising performance on SIRST detection, but at the cost of a large amount of training data with expensive pixel-level annotations. To reduce the annotation burden, we propose the first method to achieve SIRST detection with single-point supervision. The core idea of this work is to recover the per-pixel mask of each target from the given single point label by using clustering approaches, which looks simple but is indeed challenging since targets are always insalient and accompanied with background clutters. To handle this issue, we introduce randomness to the clustering process by adding noise to the input images, and then obtain much more reliable pseudo masks by averaging the clustered results. Thanks to this "Monte Carlo" clustering approach, our method can accurately recover pseudo masks and thus turn arbitrary fully supervised SIRST detection networks into weakly supervised ones with only single point annotation. Experiments on four datasets demonstrate that our method can be applied to existing SIRST detection networks to achieve comparable performance with their fully supervised counterparts, which reveals that single-point supervision is strong enough for SIRST detection. Our code will be available at: https://github.com/YeRen123455/SIRST-Single-Point-Supervision.
You Only Train Once: Learning a General Anomaly Enhancement Network with Random Masks for Hyperspectral Anomaly Detection
Mar 31, 2023



In this paper, we introduce a new approach to address the challenge of generalization in hyperspectral anomaly detection (AD). Our method eliminates the need for adjusting parameters or retraining on new test scenes as required by most existing methods. Employing an image-level training paradigm, we achieve a general anomaly enhancement network for hyperspectral AD that only needs to be trained once. Trained on a set of anomaly-free hyperspectral images with random masks, our network can learn the spatial context characteristics between anomalies and background in an unsupervised way. Additionally, a plug-and-play model selection module is proposed to search for a spatial-spectral transform domain that is more suitable for AD task than the original data. To establish a unified benchmark to comprehensively evaluate our method and existing methods, we develop a large-scale hyperspectral AD dataset (HAD100) that includes 100 real test scenes with diverse anomaly targets. In comparison experiments, we combine our network with a parameter-free detector and achieve the optimal balance between detection accuracy and inference speed among state-of-the-art AD methods. Experimental results also show that our method still achieves competitive performance when the training and test set are captured by different sensor devices. Our code is available at https://github.com/ZhaoxuLi123/AETNet.
MTU-Net: Multi-level TransUNet for Space-based Infrared Tiny Ship Detection
Sep 28, 2022
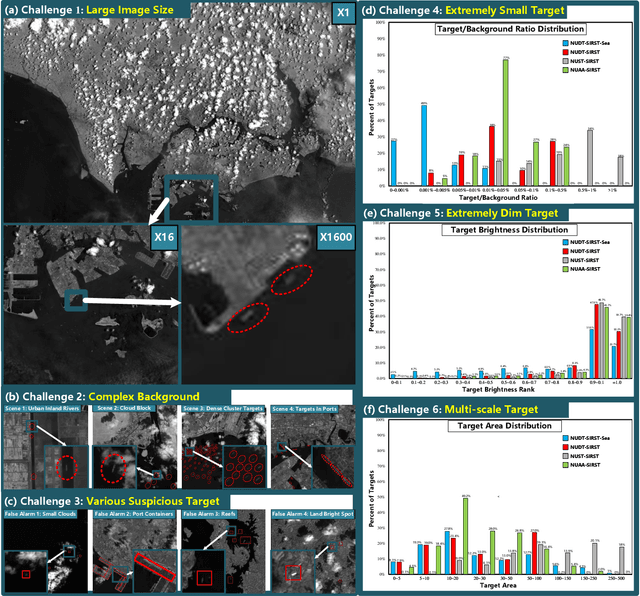
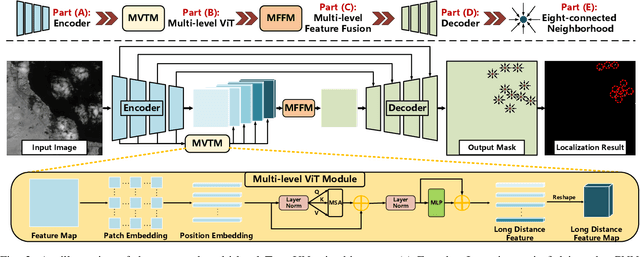
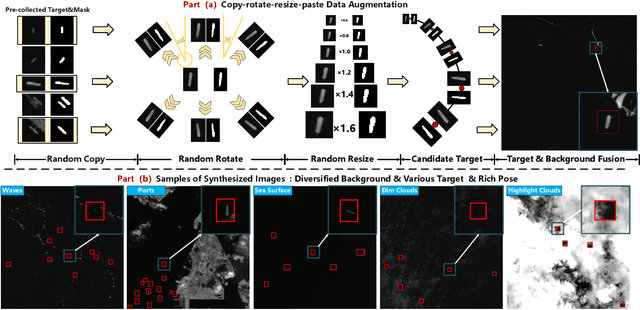
Space-based infrared tiny ship detection aims at separating tiny ships from the images captured by earth orbiting satellites. Due to the extremely large image coverage area (e.g., thousands square kilometers), candidate targets in these images are much smaller, dimer, more changeable than those targets observed by aerial-based and land-based imaging devices. Existing short imaging distance-based infrared datasets and target detection methods cannot be well adopted to the space-based surveillance task. To address these problems, we develop a space-based infrared tiny ship detection dataset (namely, NUDT-SIRST-Sea) with 48 space-based infrared images and 17598 pixel-level tiny ship annotations. Each image covers about 10000 square kilometers of area with 10000X10000 pixels. Considering the extreme characteristics (e.g., small, dim, changeable) of those tiny ships in such challenging scenes, we propose a multi-level TransUNet (MTU-Net) in this paper. Specifically, we design a Vision Transformer (ViT) Convolutional Neural Network (CNN) hybrid encoder to extract multi-level features. Local feature maps are first extracted by several convolution layers and then fed into the multi-level feature extraction module (MVTM) to capture long-distance dependency. We further propose a copy-rotate-resize-paste (CRRP) data augmentation approach to accelerate the training phase, which effectively alleviates the issue of sample imbalance between targets and background. Besides, we design a FocalIoU loss to achieve both target localization and shape description. Experimental results on the NUDT-SIRST-Sea dataset show that our MTU-Net outperforms traditional and existing deep learning based SIRST methods in terms of probability of detection, false alarm rate and intersection over union.