 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeights Shuffling for Improving DPSGD in Transformer-based Models
Jul 22, 2024Differential Privacy (DP) mechanisms, especially in high-dimensional settings, often face the challenge of maintaining privacy without compromising the data utility. This work introduces an innovative shuffling mechanism in Differentially-Private Stochastic Gradient Descent (DPSGD) to enhance the utility of large models at the same privacy guarantee of the unshuffled case. Specifically, we reveal that random shuffling brings additional randomness to the trajectory of gradient descent while not impacting the model accuracy by the permutation invariance property -- the model can be equivalently computed in both forward and backward propagations under permutation. We show that permutation indeed improves the privacy guarantee of DPSGD in theory, but tracking the exact privacy loss on shuffled model is particularly challenging. Hence we exploit the approximation on sum of lognormal distributions to derive the condition for the shuffled DPSGD to meet the DP guarantee. Auditing results show that our condition offers a DP guarantee quite close to the audited privacy level, demonstrating our approach an effective estimation in practice. Experimental results have verified our theoretical derivation and illustrate that our mechanism improves the accuracy of DPSGD over the state-of-the-art baselines on a variety of models and tasks.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024
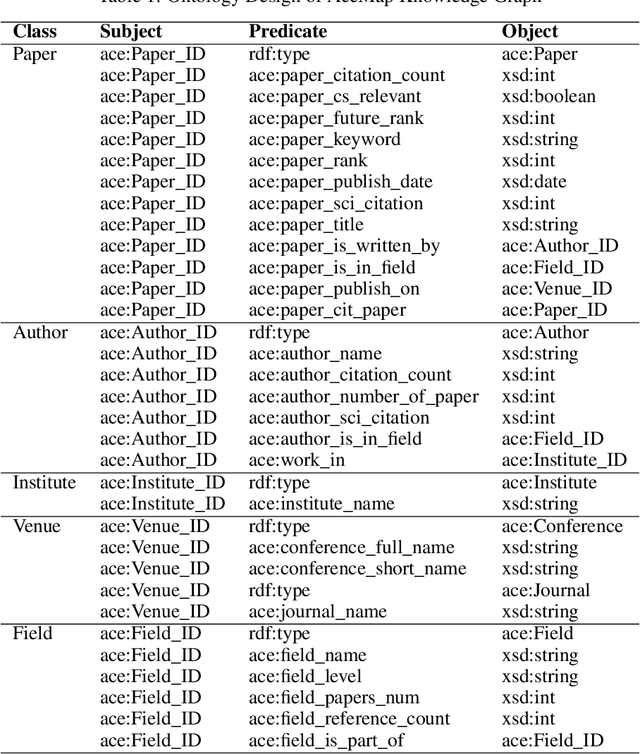
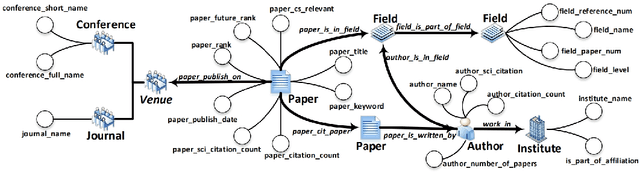
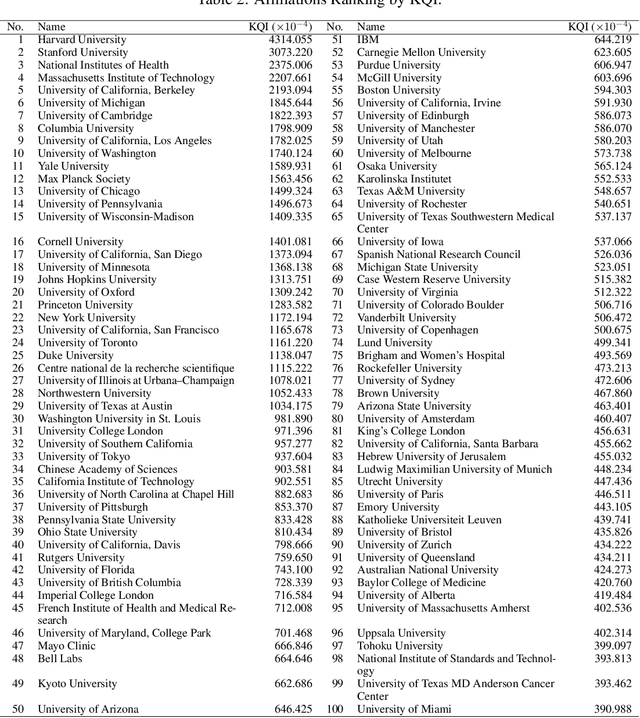
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
NTIRE 2023 Challenge on Light Field Image Super-Resolution: Dataset, Methods and Results
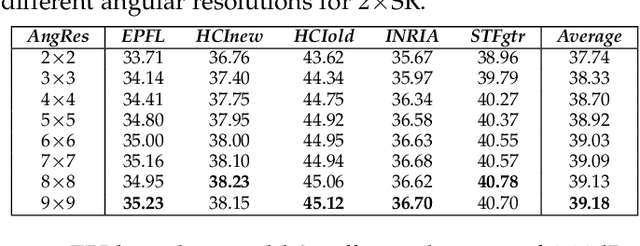
Apr 20, 2023In this report, we summarize the first NTIRE challenge on light field (LF) image super-resolution (SR), which aims at super-resolving LF images under the standard bicubic degradation with a magnification factor of 4. This challenge develops a new LF dataset called NTIRE-2023 for validation and test, and provides a toolbox called BasicLFSR to facilitate model development. Compared with single image SR, the major challenge of LF image SR lies in how to exploit complementary angular information from plenty of views with varying disparities. In total, 148 participants have registered the challenge, and 11 teams have successfully submitted results with PSNR scores higher than the baseline method LF-InterNet \cite{LF-InterNet}. These newly developed methods have set new state-of-the-art in LF image SR, e.g., the winning method achieves around 1 dB PSNR improvement over the existing state-of-the-art method DistgSSR \cite{DistgLF}. We report the solutions proposed by the participants, and summarize their common trends and useful tricks. We hope this challenge can stimulate future research and inspire new ideas in LF image SR.
Learning Non-Local Spatial-Angular Correlation for Light Field Image Super-Resolution
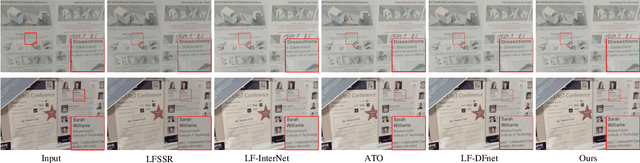
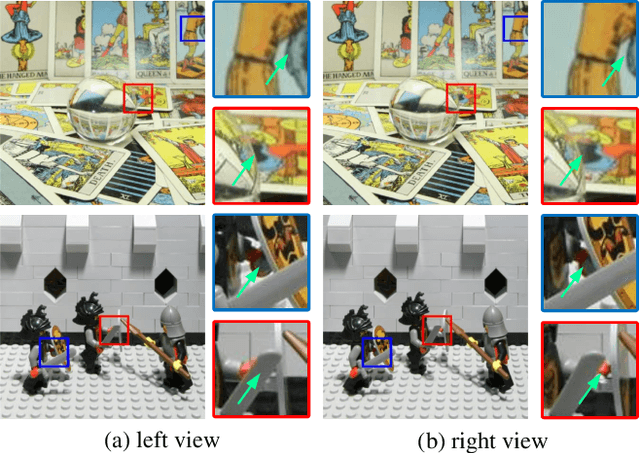
Feb 18, 2023Exploiting spatial-angular correlation is crucial to light field (LF) image super-resolution (SR), but is highly challenging due to its non-local property caused by the disparities among LF images. Although many deep neural networks (DNNs) have been developed for LF image SR and achieved continuously improved performance, existing methods cannot well leverage the long-range spatial-angular correlation and thus suffer a significant performance drop when handling scenes with large disparity variations. In this paper, we propose a simple yet effective method to learn the non-local spatial-angular correlation for LF image SR. In our method, we adopt the epipolar plane image (EPI) representation to project the 4D spatial-angular correlation onto multiple 2D EPI planes, and then develop a Transformer network with repetitive self-attention operations to learn the spatial-angular correlation by modeling the dependencies between each pair of EPI pixels. Our method can fully incorporate the information from all angular views while achieving a global receptive field along the epipolar line. We conduct extensive experiments with insightful visualizations to validate the effectiveness of our method. Comparative results on five public datasets show that our method not only achieves state-of-the-art SR performance, but also performs robust to disparity variations. Code is publicly available at https://github.com/ZhengyuLiang24/EPIT.
MTU-Net: Multi-level TransUNet for Space-based Infrared Tiny Ship Detection
Sep 28, 2022
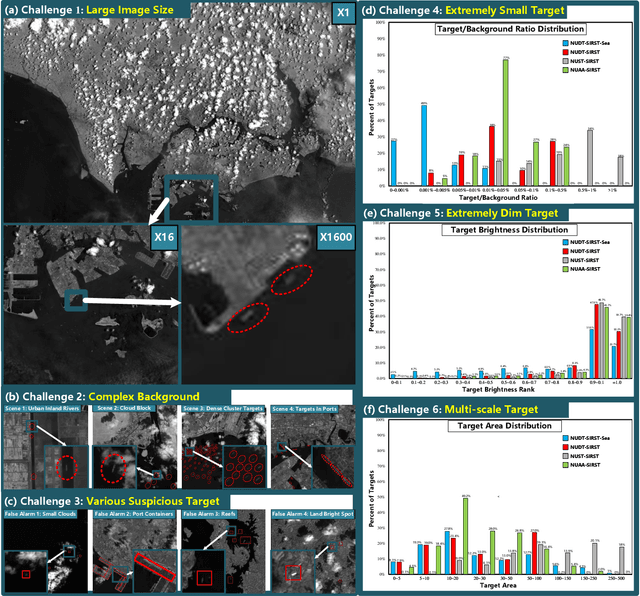
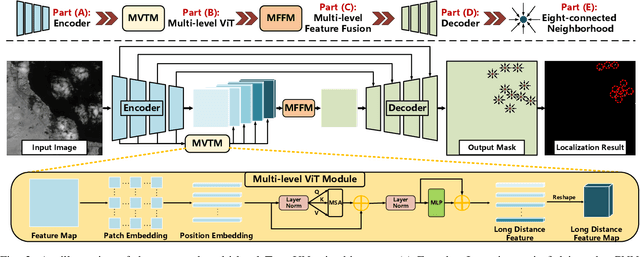
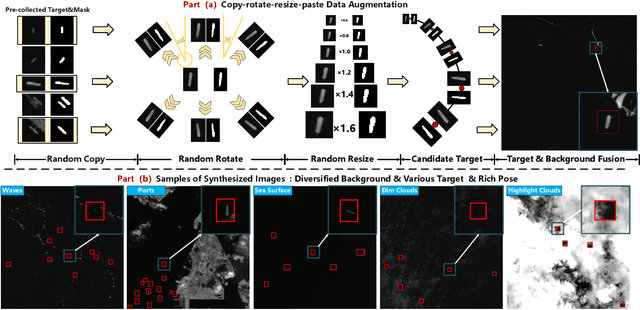
Space-based infrared tiny ship detection aims at separating tiny ships from the images captured by earth orbiting satellites. Due to the extremely large image coverage area (e.g., thousands square kilometers), candidate targets in these images are much smaller, dimer, more changeable than those targets observed by aerial-based and land-based imaging devices. Existing short imaging distance-based infrared datasets and target detection methods cannot be well adopted to the space-based surveillance task. To address these problems, we develop a space-based infrared tiny ship detection dataset (namely, NUDT-SIRST-Sea) with 48 space-based infrared images and 17598 pixel-level tiny ship annotations. Each image covers about 10000 square kilometers of area with 10000X10000 pixels. Considering the extreme characteristics (e.g., small, dim, changeable) of those tiny ships in such challenging scenes, we propose a multi-level TransUNet (MTU-Net) in this paper. Specifically, we design a Vision Transformer (ViT) Convolutional Neural Network (CNN) hybrid encoder to extract multi-level features. Local feature maps are first extracted by several convolution layers and then fed into the multi-level feature extraction module (MVTM) to capture long-distance dependency. We further propose a copy-rotate-resize-paste (CRRP) data augmentation approach to accelerate the training phase, which effectively alleviates the issue of sample imbalance between targets and background. Besides, we design a FocalIoU loss to achieve both target localization and shape description. Experimental results on the NUDT-SIRST-Sea dataset show that our MTU-Net outperforms traditional and existing deep learning based SIRST methods in terms of probability of detection, false alarm rate and intersection over union.
Learning a Degradation-Adaptive Network for Light Field Image Super-Resolution
Jun 13, 2022



Recent years have witnessed the great advances of deep neural networks (DNNs) in light field (LF) image super-resolution (SR). However, existing DNN-based LF image SR methods are developed on a single fixed degradation (e.g., bicubic downsampling), and thus cannot be applied to super-resolve real LF images with diverse degradations. In this paper, we propose the first method to handle LF image SR with multiple degradations. In our method, a practical LF degradation model that considers blur and noise is developed to approximate the degradation process of real LF images. Then, a degradation-adaptive network (LF-DAnet) is designed to incorporate the degradation prior into the SR process. By training on LF images with multiple synthetic degradations, our method can learn to adapt to different degradations while incorporating the spatial and angular information. Extensive experiments on both synthetically degraded and real-world LFs demonstrate the effectiveness of our method. Compared with existing state-of-the-art single and LF image SR methods, our method achieves superior SR performance under a wide range of degradations, and generalizes better to real LF images. Codes and models are available at https://github.com/YingqianWang/LF-DAnet.
Occlusion-Aware Cost Constructor for Light Field Depth Estimation
Mar 03, 2022

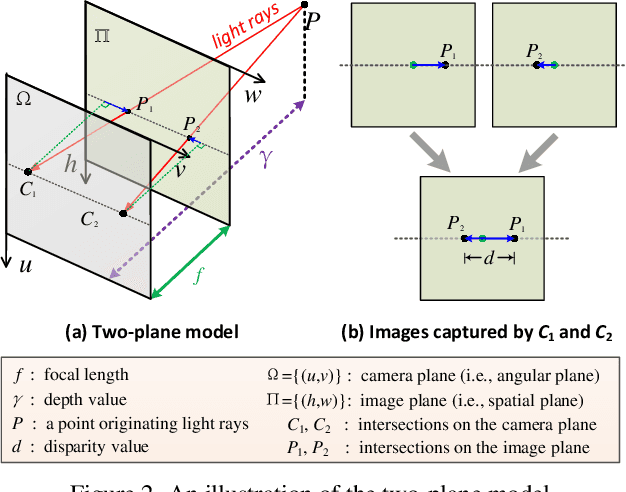
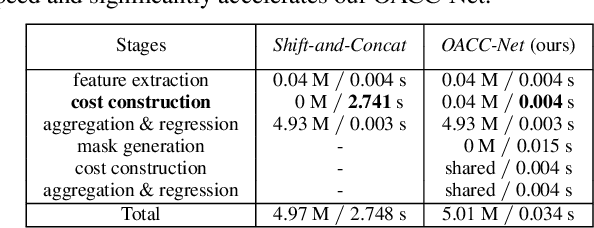
Matching cost construction is a key step in light field (LF) depth estimation, but was rarely studied in the deep learning era. Recent deep learning-based LF depth estimation methods construct matching cost by sequentially shifting each sub-aperture image (SAI) with a series of predefined offsets, which is complex and time-consuming. In this paper, we propose a simple and fast cost constructor to construct matching cost for LF depth estimation. Our cost constructor is composed by a series of convolutions with specifically designed dilation rates. By applying our cost constructor to SAI arrays, pixels under predefined disparities can be integrated and matching cost can be constructed without using any shifting operation. More importantly, the proposed cost constructor is occlusion-aware and can handle occlusions by dynamically modulating pixels from different views. Based on the proposed cost constructor, we develop a deep network for LF depth estimation. Our network ranks first on the commonly used 4D LF benchmark in terms of the mean square error (MSE), and achieves a faster running time than other state-of-the-art methods.
Disentangling Light Fields for Super-Resolution and Disparity Estimation
Feb 22, 2022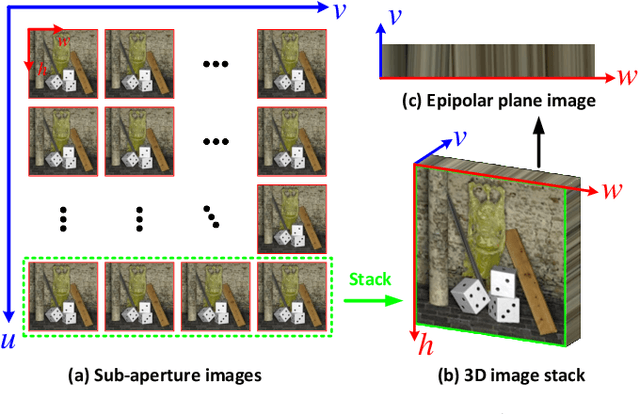
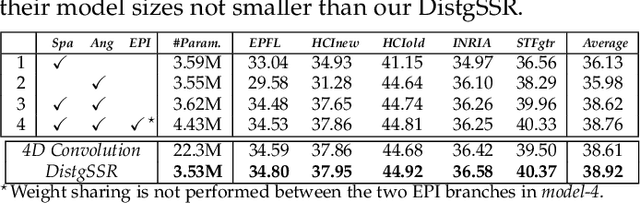
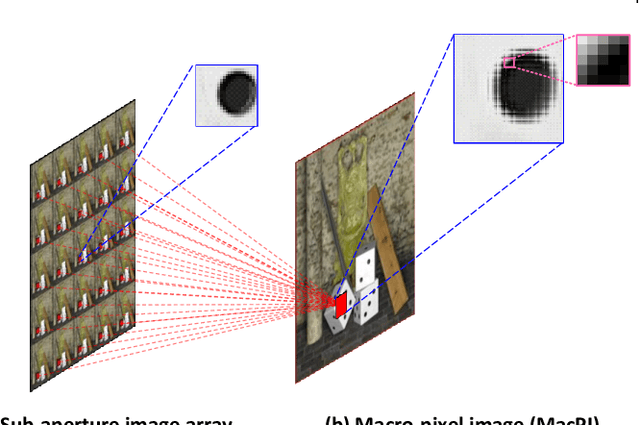
Light field (LF) cameras record both intensity and directions of light rays, and encode 3D scenes into 4D LF images. Recently, many convolutional neural networks (CNNs) have been proposed for various LF image processing tasks. However, it is challenging for CNNs to effectively process LF images since the spatial and angular information are highly inter-twined with varying disparities. In this paper, we propose a generic mechanism to disentangle these coupled information for LF image processing. Specifically, we first design a class of domain-specific convolutions to disentangle LFs from different dimensions, and then leverage these disentangled features by designing task-specific modules. Our disentangling mechanism can well incorporate the LF structure prior and effectively handle 4D LF data. Based on the proposed mechanism, we develop three networks (i.e., DistgSSR, DistgASR and DistgDisp) for spatial super-resolution, angular super-resolution and disparity estimation. Experimental results show that our networks achieve state-of-the-art performance on all these three tasks, which demonstrates the effectiveness, efficiency, and generality of our disentangling mechanism. Project page: https://yingqianwang.github.io/DistgLF/.
Dense Dual-Attention Network for Light Field Image Super-Resolution
Oct 23, 2021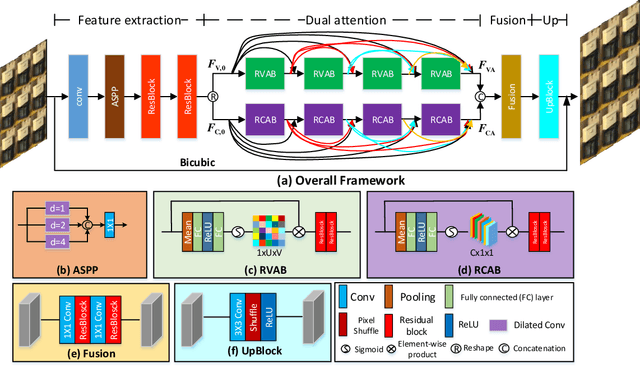

Light field (LF) images can be used to improve the performance of image super-resolution (SR) because both angular and spatial information is available. It is challenging to incorporate distinctive information from different views for LF image SR. Moreover, the long-term information from the previous layers can be weakened as the depth of network increases. In this paper, we propose a dense dual-attention network for LF image SR. Specifically, we design a view attention module to adaptively capture discriminative features across different views and a channel attention module to selectively focus on informative information across all channels. These two modules are fed to two branches and stacked separately in a chain structure for adaptive fusion of hierarchical features and distillation of valid information. Meanwhile, a dense connection is used to fully exploit multi-level information. Extensive experiments demonstrate that our dense dual-attention mechanism can capture informative information across views and channels to improve SR performance. Comparative results show the advantage of our method over state-of-the-art methods on public datasets.
Light Field Image Super-Resolution with Transformers
Aug 17, 2021


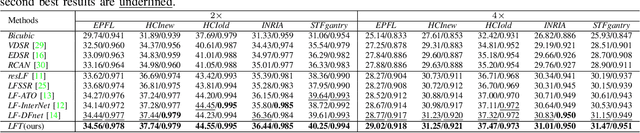
Light field (LF) image super-resolution (SR) aims at reconstructing high-resolution LF images from their low-resolution counterparts. Although CNN-based methods have achieved remarkable performance in LF image SR, these methods cannot fully model the non-local properties of the 4D LF data. In this paper, we propose a simple but effective Transformer-based method for LF image SR. In our method, an angular Transformer is designed to incorporate complementary information among different views, and a spatial Transformer is developed to capture both local and long-range dependencies within each sub-aperture image. With the proposed angular and spatial Transformers, the beneficial information in an LF can be fully exploited and the SR performance is boosted. We validate the effectiveness of our angular and spatial Transformers through extensive ablation studies, and compare our method to recent state-of-the-art methods on five public LF datasets. Our method achieves superior SR performance with a small model size and low computational cost.