 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAID: Retrieval-Augmented Anomaly Detection
Feb 23, 2026Unsupervised Anomaly Detection (UAD) aims to identify abnormal regions by establishing correspondences between test images and normal templates. Existing methods primarily rely on image reconstruction or template retrieval but face a fundamental challenge: matching between test images and normal templates inevitably introduces noise due to intra-class variations, imperfect correspondences, and limited templates. Observing that Retrieval-Augmented Generation (RAG) leverages retrieved samples directly in the generation process, we reinterpret UAD through this lens and introduce \textbf{RAID}, a retrieval-augmented UAD framework designed for noise-resilient anomaly detection and localization. Unlike standard RAG that enriches context or knowledge, we focus on using retrieved normal samples to guide noise suppression in anomaly map generation. RAID retrieves class-, semantic-, and instance-level representations from a hierarchical vector database, forming a coarse-to-fine pipeline. A matching cost volume correlates the input with retrieved exemplars, followed by a guided Mixture-of-Experts (MoE) network that leverages the retrieved samples to adaptively suppress matching noise and produce fine-grained anomaly maps. RAID achieves state-of-the-art performance across full-shot, few-shot, and multi-dataset settings on MVTec, VisA, MPDD, and BTAD benchmarks. \href{https://github.com/Mingxiu-Cai/RAID}{https://github.com/Mingxiu-Cai/RAID}.
CostFilter-AD: Enhancing Anomaly Detection through Matching Cost Filtering
May 02, 2025



Unsupervised anomaly detection (UAD) seeks to localize the anomaly mask of an input image with respect to normal samples. Either by reconstructing normal counterparts (reconstruction-based) or by learning an image feature embedding space (embedding-based), existing approaches fundamentally rely on image-level or feature-level matching to derive anomaly scores. Often, such a matching process is inaccurate yet overlooked, leading to sub-optimal detection. To address this issue, we introduce the concept of cost filtering, borrowed from classical matching tasks, such as depth and flow estimation, into the UAD problem. We call this approach {\em CostFilter-AD}. Specifically, we first construct a matching cost volume between the input and normal samples, comprising two spatial dimensions and one matching dimension that encodes potential matches. To refine this, we propose a cost volume filtering network, guided by the input observation as an attention query across multiple feature layers, which effectively suppresses matching noise while preserving edge structures and capturing subtle anomalies. Designed as a generic post-processing plug-in, CostFilter-AD can be integrated with either reconstruction-based or embedding-based methods. Extensive experiments on MVTec-AD and VisA benchmarks validate the generic benefits of CostFilter-AD for both single- and multi-class UAD tasks. Code and models will be released at https://github.com/ZHE-SAPI/CostFilter-AD.
Cross-Modal Learning for Anomaly Detection in Fused Magnesium Smelting Process: Methodology and Benchmark
Jun 13, 2024Fused Magnesium Furnace (FMF) is a crucial industrial equipment in the production of magnesia, and anomaly detection plays a pivotal role in ensuring its efficient, stable, and secure operation. Existing anomaly detection methods primarily focus on analyzing dominant anomalies using the process variables (such as arc current) or constructing neural networks based on abnormal visual features, while overlooking the intrinsic correlation of cross-modal information. This paper proposes a cross-modal Transformer (dubbed FmFormer), designed to facilitate anomaly detection in fused magnesium smelting processes by exploring the correlation between visual features (video) and process variables (current). Our approach introduces a novel tokenization paradigm to effectively bridge the substantial dimensionality gap between the 3D video modality and the 1D current modality in a multiscale manner, enabling a hierarchical reconstruction of pixel-level anomaly detection. Subsequently, the FmFormer leverages self-attention to learn internal features within each modality and bidirectional cross-attention to capture correlations across modalities. To validate the effectiveness of the proposed method, we also present a pioneering cross-modal benchmark of the fused magnesium smelting process, featuring synchronously acquired video and current data for over 2.2 million samples. Leveraging cross-modal learning, the proposed FmFormer achieves state-of-the-art performance in detecting anomalies, particularly under extreme interferences such as current fluctuations and visual occlusion caused by heavy water mist. The presented methodology and benchmark may be applicable to other industrial applications with some amendments. The benchmark will be released at https://github.com/GaochangWu/FMF-Benchmark.
DA-STC: Domain Adaptive Video Semantic Segmentation via Spatio-Temporal Consistency
Nov 22, 2023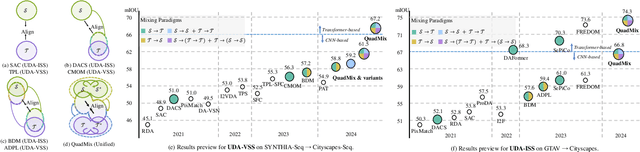
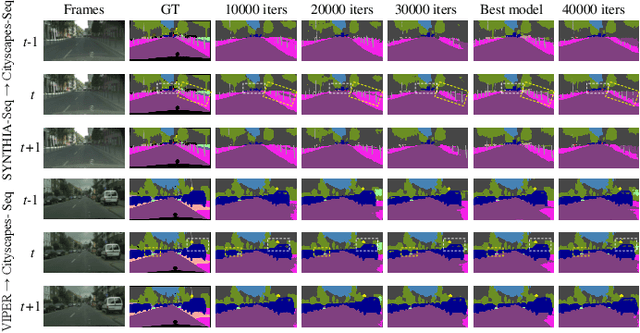
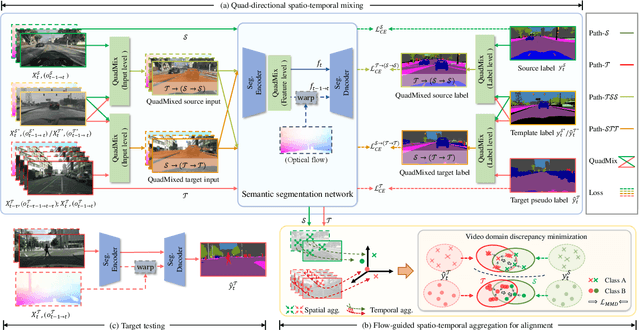
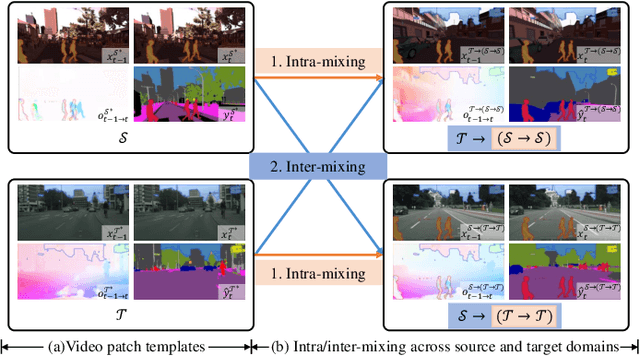
Video semantic segmentation is a pivotal aspect of video representation learning. However, significant domain shifts present a challenge in effectively learning invariant spatio-temporal features across the labeled source domain and unlabeled target domain for video semantic segmentation. To solve the challenge, we propose a novel DA-STC method for domain adaptive video semantic segmentation, which incorporates a bidirectional multi-level spatio-temporal fusion module and a category-aware spatio-temporal feature alignment module to facilitate consistent learning for domain-invariant features. Firstly, we perform bidirectional spatio-temporal fusion at the image sequence level and shallow feature level, leading to the construction of two fused intermediate video domains. This prompts the video semantic segmentation model to consistently learn spatio-temporal features of shared patch sequences which are influenced by domain-specific contexts, thereby mitigating the feature gap between the source and target domain. Secondly, we propose a category-aware feature alignment module to promote the consistency of spatio-temporal features, facilitating adaptation to the target domain. Specifically, we adaptively aggregate the domain-specific deep features of each category along spatio-temporal dimensions, which are further constrained to achieve cross-domain intra-class feature alignment and inter-class feature separation. Extensive experiments demonstrate the effectiveness of our method, which achieves state-of-the-art mIOUs on multiple challenging benchmarks. Furthermore, we extend the proposed DA-STC to the image domain, where it also exhibits superior performance for domain adaptive semantic segmentation. The source code and models will be made available at \url{https://github.com/ZHE-SAPI/DA-STC}.
Geo-NI: Geometry-aware Neural Interpolation for Light Field Rendering
Jun 20, 2022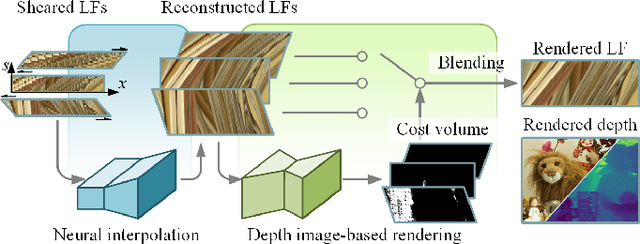
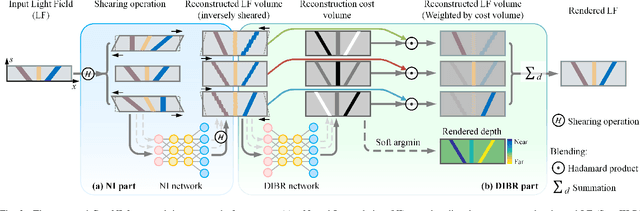


In this paper, we present a Geometry-aware Neural Interpolation (Geo-NI) framework for light field rendering. Previous learning-based approaches either rely on the capability of neural networks to perform direct interpolation, which we dubbed Neural Interpolation (NI), or explore scene geometry for novel view synthesis, also known as Depth Image-Based Rendering (DIBR). Instead, we incorporate the ideas behind these two kinds of approaches by launching the NI with a novel DIBR pipeline. Specifically, the proposed Geo-NI first performs NI using input light field sheared by a set of depth hypotheses. Then the DIBR is implemented by assigning the sheared light fields with a novel reconstruction cost volume according to the reconstruction quality under different depth hypotheses. The reconstruction cost is interpreted as a blending weight to render the final output light field by blending the reconstructed light fields along the dimension of depth hypothesis. By combining the superiorities of NI and DIBR, the proposed Geo-NI is able to render views with large disparity with the help of scene geometry while also reconstruct non-Lambertian effect when depth is prone to be ambiguous. Extensive experiments on various datasets demonstrate the superior performance of the proposed geometry-aware light field rendering framework.
Disentangling Light Fields for Super-Resolution and Disparity Estimation
Feb 22, 2022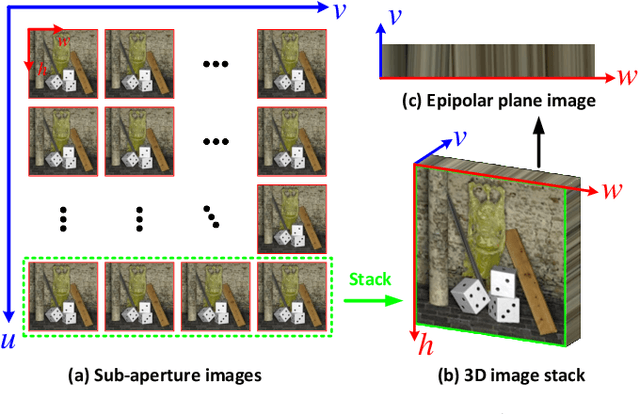
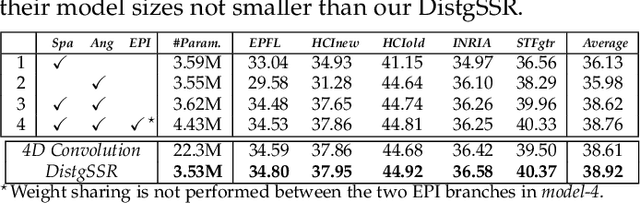
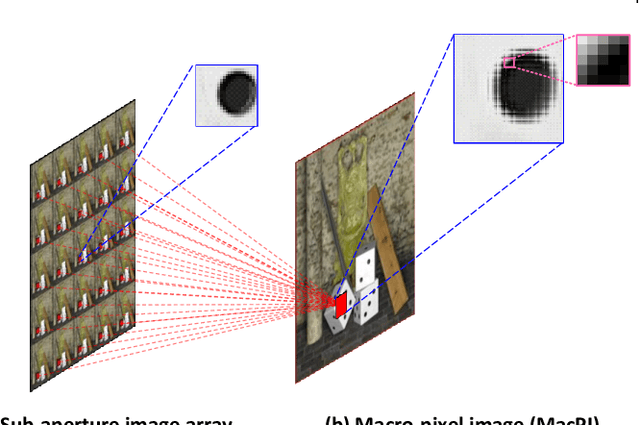
Light field (LF) cameras record both intensity and directions of light rays, and encode 3D scenes into 4D LF images. Recently, many convolutional neural networks (CNNs) have been proposed for various LF image processing tasks. However, it is challenging for CNNs to effectively process LF images since the spatial and angular information are highly inter-twined with varying disparities. In this paper, we propose a generic mechanism to disentangle these coupled information for LF image processing. Specifically, we first design a class of domain-specific convolutions to disentangle LFs from different dimensions, and then leverage these disentangled features by designing task-specific modules. Our disentangling mechanism can well incorporate the LF structure prior and effectively handle 4D LF data. Based on the proposed mechanism, we develop three networks (i.e., DistgSSR, DistgASR and DistgDisp) for spatial super-resolution, angular super-resolution and disparity estimation. Experimental results show that our networks achieve state-of-the-art performance on all these three tasks, which demonstrates the effectiveness, efficiency, and generality of our disentangling mechanism. Project page: https://yingqianwang.github.io/DistgLF/.
LocalTrans: A Multiscale Local Transformer Network for Cross-Resolution Homography Estimation
Jun 13, 2021
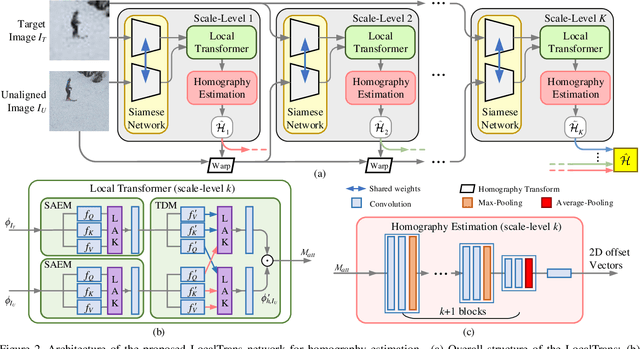
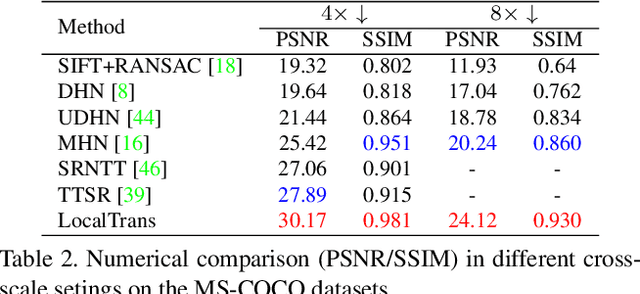
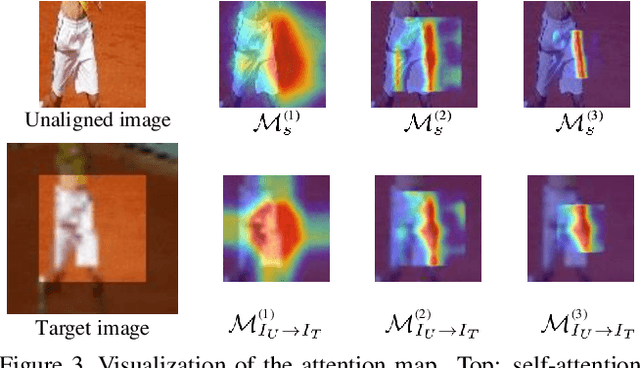
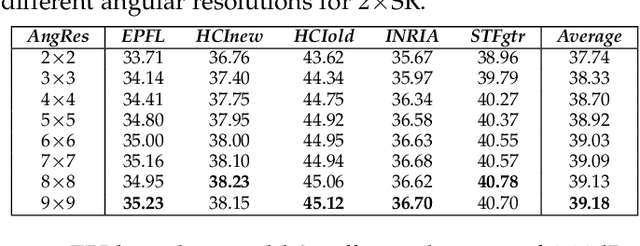
Cross-resolution image alignment is a key problem in multiscale gigapixel photography, which requires to estimate homography matrix using images with large resolution gap. Existing deep homography methods concatenate the input images or features, neglecting the explicit formulation of correspondences between them, which leads to degraded accuracy in cross-resolution challenges. In this paper, we consider the cross-resolution homography estimation as a multimodal problem, and propose a local transformer network embedded within a multiscale structure to explicitly learn correspondences between the multimodal inputs, namely, input images with different resolutions. The proposed local transformer adopts a local attention map specifically for each position in the feature. By combining the local transformer with the multiscale structure, the network is able to capture long-short range correspondences efficiently and accurately. Experiments on both the MS-COCO dataset and the real-captured cross-resolution dataset show that the proposed network outperforms existing state-of-the-art feature-based and deep-learning-based homography estimation methods, and is able to accurately align images under $10\times$ resolution gap.
Revisiting Light Field Rendering with Deep Anti-Aliasing Neural Network
Apr 28, 2021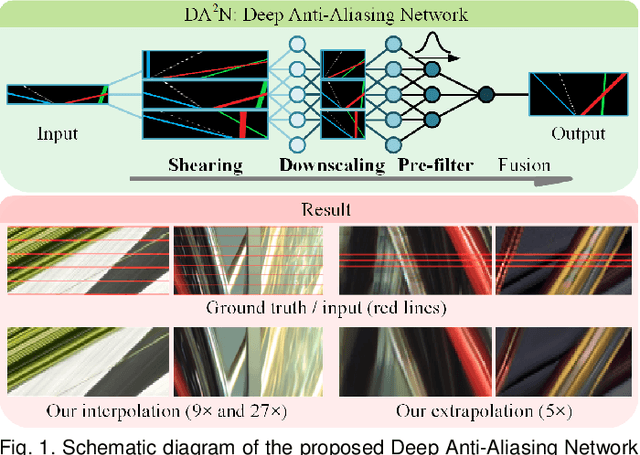

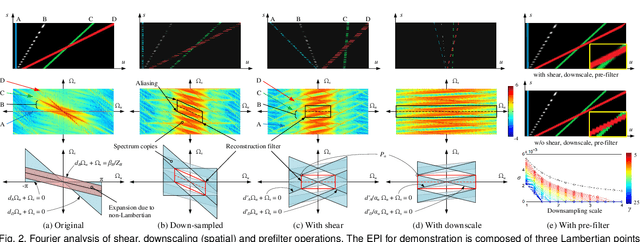
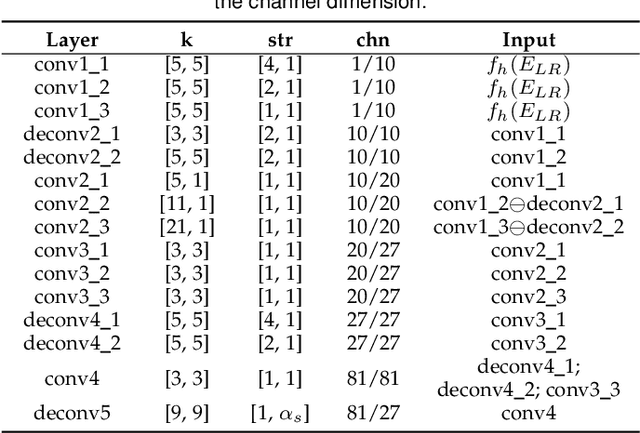
The light field (LF) reconstruction is mainly confronted with two challenges, large disparity and the non-Lambertian effect. Typical approaches either address the large disparity challenge using depth estimation followed by view synthesis or eschew explicit depth information to enable non-Lambertian rendering, but rarely solve both challenges in a unified framework. In this paper, we revisit the classic LF rendering framework to address both challenges by incorporating it with advanced deep learning techniques. First, we analytically show that the essential issue behind the large disparity and non-Lambertian challenges is the aliasing problem. Classic LF rendering approaches typically mitigate the aliasing with a reconstruction filter in the Fourier domain, which is, however, intractable to implement within a deep learning pipeline. Instead, we introduce an alternative framework to perform anti-aliasing reconstruction in the image domain and analytically show comparable efficacy on the aliasing issue. To explore the full potential, we then embed the anti-aliasing framework into a deep neural network through the design of an integrated architecture and trainable parameters. The network is trained through end-to-end optimization using a peculiar training set, including regular LFs and unstructured LFs. The proposed deep learning pipeline shows a substantial superiority in solving both the large disparity and the non-Lambertian challenges compared with other state-of-the-art approaches. In addition to the view interpolation for an LF, we also show that the proposed pipeline also benefits light field view extrapolation.
* 15 pages, 12 figures. Accepted by IEEE TPAMI
Light Field Reconstruction Using Convolutional Network on EPI and Extended Applications
Mar 24, 2021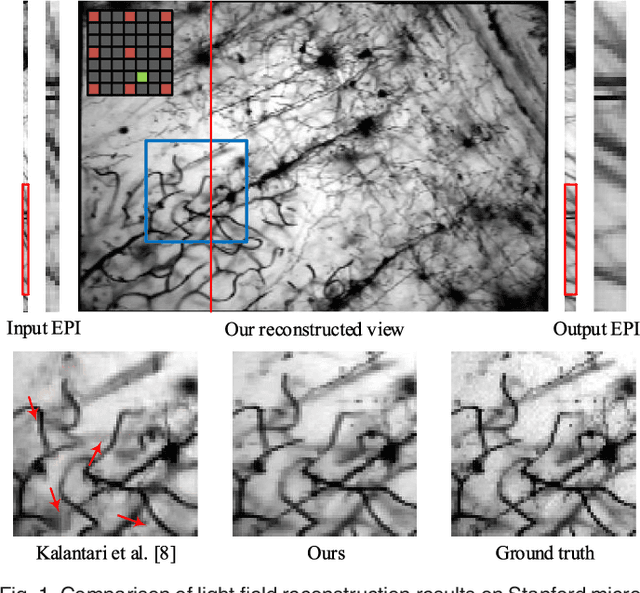
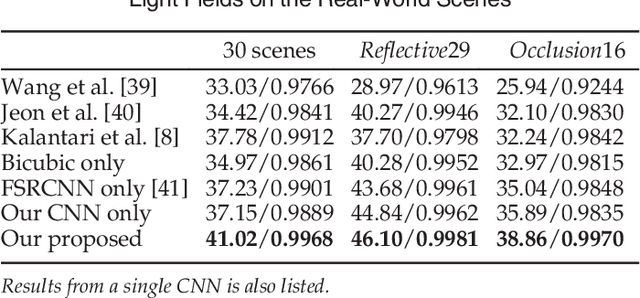


In this paper, a novel convolutional neural network (CNN)-based framework is developed for light field reconstruction from a sparse set of views. We indicate that the reconstruction can be efficiently modeled as angular restoration on an epipolar plane image (EPI). The main problem in direct reconstruction on the EPI involves an information asymmetry between the spatial and angular dimensions, where the detailed portion in the angular dimensions is damaged by undersampling. Directly upsampling or super-resolving the light field in the angular dimensions causes ghosting effects. To suppress these ghosting effects, we contribute a novel "blur-restoration-deblur" framework. First, the "blur" step is applied to extract the low-frequency components of the light field in the spatial dimensions by convolving each EPI slice with a selected blur kernel. Then, the "restoration" step is implemented by a CNN, which is trained to restore the angular details of the EPI. Finally, we use a non-blind "deblur" operation to recover the spatial high frequencies suppressed by the EPI blur. We evaluate our approach on several datasets, including synthetic scenes, real-world scenes and challenging microscope light field data. We demonstrate the high performance and robustness of the proposed framework compared with state-of-the-art algorithms. We further show extended applications, including depth enhancement and interpolation for unstructured input. More importantly, a novel rendering approach is presented by combining the proposed framework and depth information to handle large disparities.
* Published in IEEE TPAMI, 2019
Cross-MPI: Cross-scale Stereo for Image Super-Resolution using Multiplane Images
Nov 30, 2020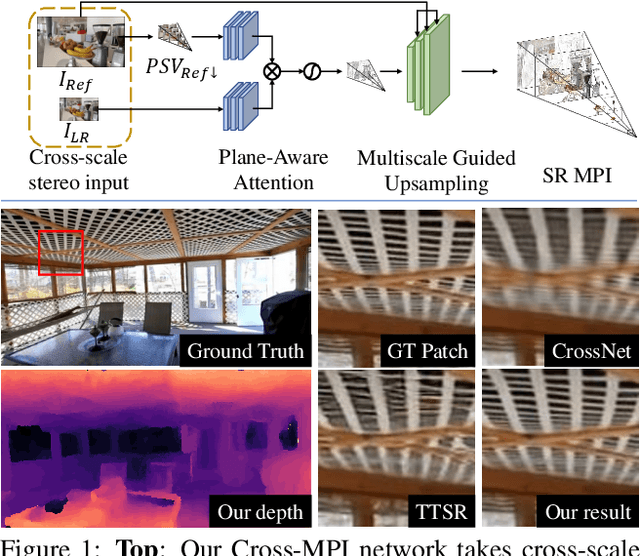
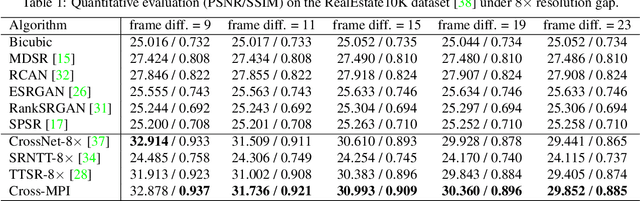
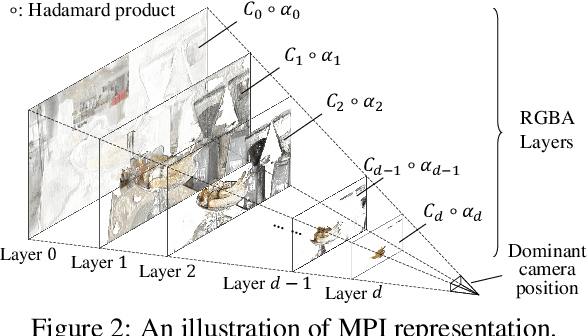

The combination of various cameras is enriching the way of computational photography, among which referencebased super-resolution (RefSR) plays a critical role in multiscale imaging systems. However, existing RefSR approaches fail to accomplish high-fidelity super-resolution under a large resolution gap, e.g., 8x upscaling, due to the less consideration of underneath scene structure. In this paper, we aim to solve the RefSR problem (in actual multiscale camera systems) inspired by multiplane images (MPI) representation. Specifically, we propose Cross-MPI, an end-to-end RefSR network composed of a novel planeaware attention-based MPI mechanism, a multiscale guided upsampling module as well as a super-resolution (SR) synthesis and fusion module. Instead of using a direct and exhaustive matching between the cross-scale stereo, the proposed plane-aware attention mechanism fully utilizes the concealed scene structure for efficient attention-based correspondence searching. Further combined with a gentle coarse-to-fine guided upsampling strategy, the proposed Cross-MPI is able to achieve a robust and accurate detail transmission. Experimental results on both digital synthesized and optical zoomed cross-scale data show the Cross- MPI framework can achieve superior performance against the existing RefSR methods, and is a real fit for actual multiscale camera systems even with large scale differences.