 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesRAG: Probabilistic Mutual Evidence Corroboration for Multimodal Retrieval-Augmented Generation
Jan 12, 2026Retrieval-Augmented Generation (RAG) has become a pivotal paradigm for Large Language Models (LLMs), yet current approaches struggle with visually rich documents by treating text and images as isolated retrieval targets. Existing methods relying solely on cosine similarity often fail to capture the semantic reinforcement provided by cross-modal alignment and layout-induced coherence. To address these limitations, we propose BayesRAG, a novel multimodal retrieval framework grounded in Bayesian inference and Dempster-Shafer evidence theory. Unlike traditional approaches that rank candidates strictly by similarity, BayesRAG models the intrinsic consistency of retrieved candidates across modalities as probabilistic evidence to refine retrieval confidence. Specifically, our method computes the posterior association probability for combinations of multimodal retrieval results, prioritizing text-image pairs that mutually corroborate each other in terms of both semantics and layout. Extensive experiments demonstrate that BayesRAG significantly outperforms state-of-the-art (SOTA) methods on challenging multimodal benchmarks. This study establishes a new paradigm for multimodal retrieval fusion that effectively resolves the isolation of heterogeneous modalities through an evidence fusion mechanism and enhances the robustness of retrieval outcomes. Our code is available at https://github.com/TioeAre/BayesRAG.
A large-scale nanocrystal database with aligned synthesis and properties enabling generative inverse design
Jan 04, 2026The synthesis of nanocrystals has been highly dependent on trial-and-error, due to the complex correlation between synthesis parameters and physicochemical properties. Although deep learning offers a potential methodology to achieve generative inverse design, it is still hindered by the scarcity of high-quality datasets that align nanocrystal synthesis routes with their properties. Here, we present the construction of a large-scale, aligned Nanocrystal Synthesis-Property (NSP) database and demonstrate its capability for generative inverse design. To extract structured synthesis routes and their corresponding product properties from literature, we develop NanoExtractor, a large language model (LLM) enhanced by well-designed augmentation strategies. NanoExtractor is validated against human experts, achieving a weighted average score of 88% on the test set, significantly outperforming chemistry-specialized (3%) and general-purpose LLMs (38%). The resulting NSP database contains nearly 160,000 aligned entries and serves as training data for our NanoDesigner, an LLM for inverse synthesis design. The generative capability of NanoDesigner is validated through the successful design of viable synthesis routes for both well-established PbSe nanocrystals and rarely reported MgF2 nanocrystals. Notably, the model recommends a counter-intuitive, non-stoichiometric precursor ratio (1:1) for MgF2 nanocrystals, which is experimentally confirmed as critical for suppressing byproducts. Our work bridges the gap between unstructured literature and data-driven synthesis, and also establishes a powerful human-AI collaborative paradigm for accelerating nanocrystal discovery.
Degradation-Aware Metric Prompting for Hyperspectral Image Restoration
Dec 23, 2025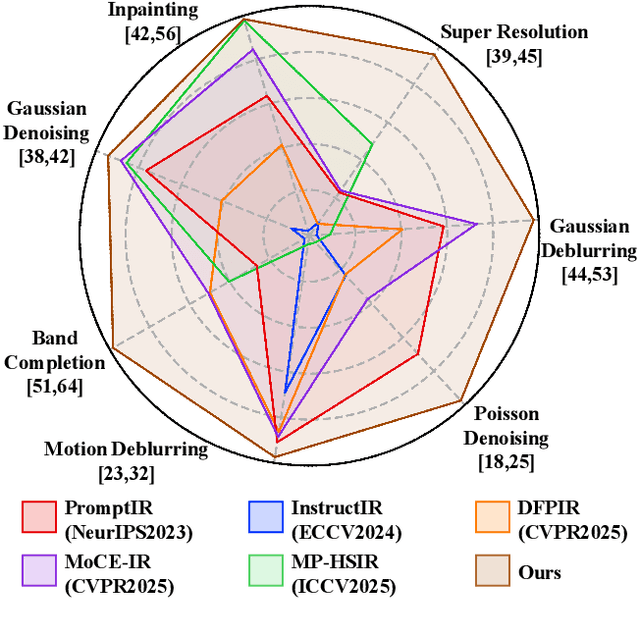

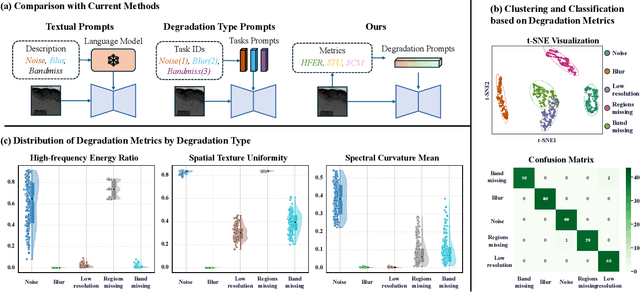
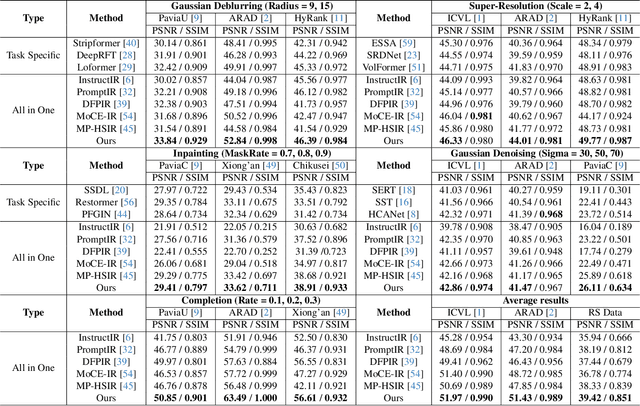
Unified hyperspectral image (HSI) restoration aims to recover various degraded HSIs using a single model, offering great practical value. However, existing methods often depend on explicit degradation priors (e.g., degradation labels) as prompts to guide restoration, which are difficult to obtain due to complex and mixed degradations in real-world scenarios. To address this challenge, we propose a Degradation-Aware Metric Prompting (DAMP) framework. Instead of relying on predefined degradation priors, we design spatial-spectral degradation metrics to continuously quantify multi-dimensional degradations, serving as Degradation Prompts (DP). These DP enable the model to capture cross-task similarities in degradation distributions and enhance shared feature learning. Furthermore, we introduce a Spatial-Spectral Adaptive Module (SSAM) that dynamically modulates spatial and spectral feature extraction through learnable parameters. By integrating SSAM as experts within a Mixture-of-Experts architecture, and using DP as the gating router, the framework enables adaptive, efficient, and robust restoration under diverse, mixed, or unseen degradations. Extensive experiments on natural and remote sensing HSI datasets show that DAMP achieves state-of-the-art performance and demonstrates exceptional generalization capability. Code is publicly available at https://github.com/MiliLab/DAMP.
ERIENet: An Efficient RAW Image Enhancement Network under Low-Light Environment
Dec 17, 2025RAW images have shown superior performance than sRGB images in many image processing tasks, especially for low-light image enhancement. However, most existing methods for RAW-based low-light enhancement usually sequentially process multi-scale information, which makes it difficult to achieve lightweight models and high processing speeds. Besides, they usually ignore the green channel superiority of RAW images, and fail to achieve better reconstruction performance with good use of green channel information. In this work, we propose an efficient RAW Image Enhancement Network (ERIENet), which parallelly processes multi-scale information with efficient convolution modules, and takes advantage of rich information in green channels to guide the reconstruction of images. Firstly, we introduce an efficient multi-scale fully-parallel architecture with a novel channel-aware residual dense block to extract feature maps, which reduces computational costs and achieves real-time processing speed. Secondly, we introduce a green channel guidance branch to exploit the rich information within the green channels of the input RAW image. It increases the quality of reconstruction results with few parameters and computations. Experiments on commonly used low-light image enhancement datasets show that ERIENet outperforms state-of-the-art methods in enhancing low-light RAW images with higher effiency. It also achieves an optimal speed of over 146 frame-per-second (FPS) for 4K-resolution images on a single NVIDIA GeForce RTX 3090 with 24G memory.
Frequency-Dynamic Attention Modulation for Dense Prediction
Jul 16, 2025Vision Transformers (ViTs) have significantly advanced computer vision, demonstrating strong performance across various tasks. However, the attention mechanism in ViTs makes each layer function as a low-pass filter, and the stacked-layer architecture in existing transformers suffers from frequency vanishing. This leads to the loss of critical details and textures. We propose a novel, circuit-theory-inspired strategy called Frequency-Dynamic Attention Modulation (FDAM), which can be easily plugged into ViTs. FDAM directly modulates the overall frequency response of ViTs and consists of two techniques: Attention Inversion (AttInv) and Frequency Dynamic Scaling (FreqScale). Since circuit theory uses low-pass filters as fundamental elements, we introduce AttInv, a method that generates complementary high-pass filtering by inverting the low-pass filter in the attention matrix, and dynamically combining the two. We further design FreqScale to weight different frequency components for fine-grained adjustments to the target response function. Through feature similarity analysis and effective rank evaluation, we demonstrate that our approach avoids representation collapse, leading to consistent performance improvements across various models, including SegFormer, DeiT, and MaskDINO. These improvements are evident in tasks such as semantic segmentation, object detection, and instance segmentation. Additionally, we apply our method to remote sensing detection, achieving state-of-the-art results in single-scale settings. The code is available at \href{https://github.com/Linwei-Chen/FDAM}{https://github.com/Linwei-Chen/FDAM}.
Spatial Frequency Modulation for Semantic Segmentation
Jul 16, 2025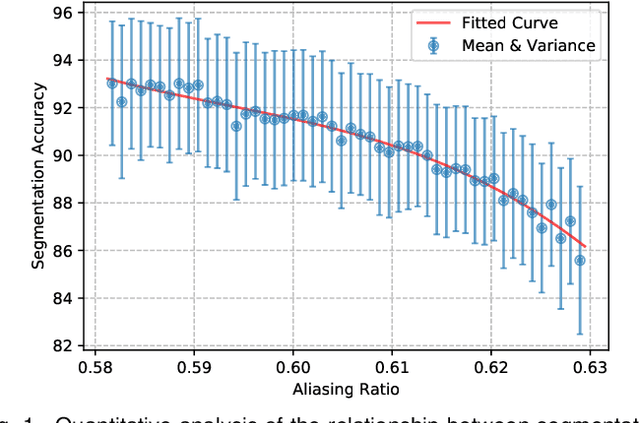
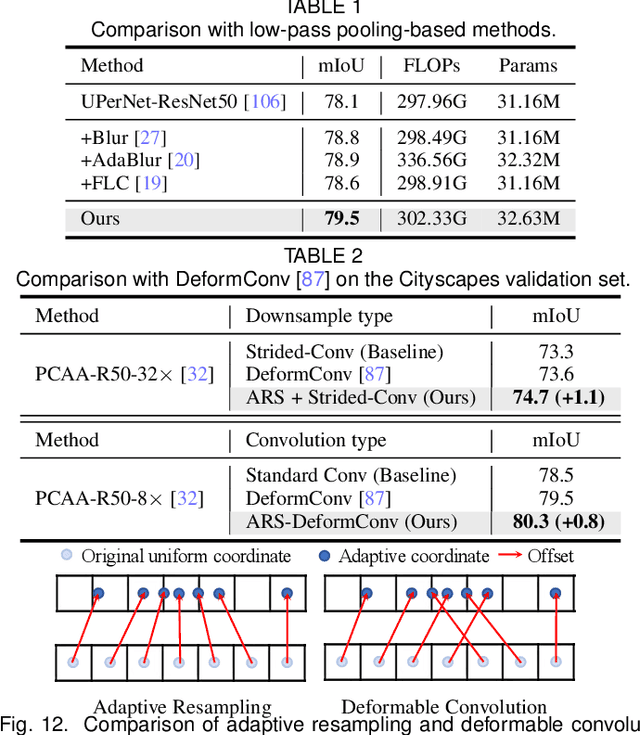
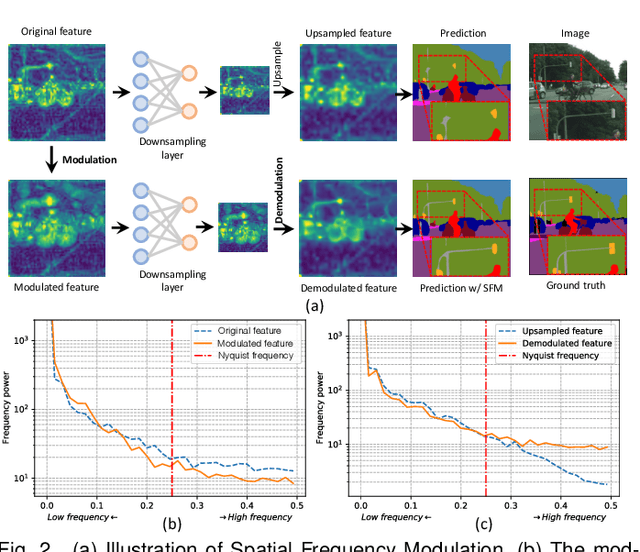
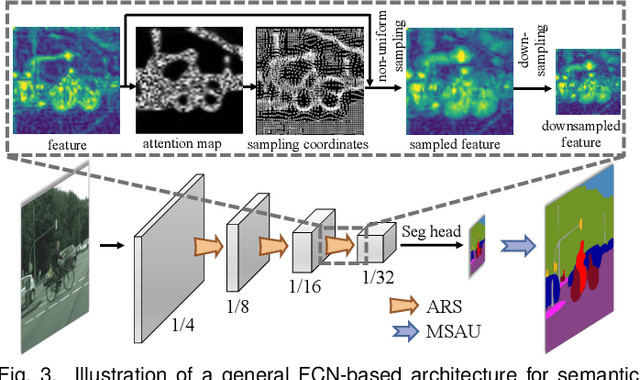
High spatial frequency information, including fine details like textures, significantly contributes to the accuracy of semantic segmentation. However, according to the Nyquist-Shannon Sampling Theorem, high-frequency components are vulnerable to aliasing or distortion when propagating through downsampling layers such as strided-convolution. Here, we propose a novel Spatial Frequency Modulation (SFM) that modulates high-frequency features to a lower frequency before downsampling and then demodulates them back during upsampling. Specifically, we implement modulation through adaptive resampling (ARS) and design a lightweight add-on that can densely sample the high-frequency areas to scale up the signal, thereby lowering its frequency in accordance with the Frequency Scaling Property. We also propose Multi-Scale Adaptive Upsampling (MSAU) to demodulate the modulated feature and recover high-frequency information through non-uniform upsampling This module further improves segmentation by explicitly exploiting information interaction between densely and sparsely resampled areas at multiple scales. Both modules can seamlessly integrate with various architectures, extending from convolutional neural networks to transformers. Feature visualization and analysis confirm that our method effectively alleviates aliasing while successfully retaining details after demodulation. Finally, we validate the broad applicability and effectiveness of SFM by extending it to image classification, adversarial robustness, instance segmentation, and panoptic segmentation tasks. The code is available at \href{https://github.com/Linwei-Chen/SFM}{https://github.com/Linwei-Chen/SFM}.
RobuSTereo: Robust Zero-Shot Stereo Matching under Adverse Weather
Jul 02, 2025Learning-based stereo matching models struggle in adverse weather conditions due to the scarcity of corresponding training data and the challenges in extracting discriminative features from degraded images. These limitations significantly hinder zero-shot generalization to out-of-distribution weather conditions. In this paper, we propose \textbf{RobuSTereo}, a novel framework that enhances the zero-shot generalization of stereo matching models under adverse weather by addressing both data scarcity and feature extraction challenges. First, we introduce a diffusion-based simulation pipeline with a stereo consistency module, which generates high-quality stereo data tailored for adverse conditions. By training stereo matching models on our synthetic datasets, we reduce the domain gap between clean and degraded images, significantly improving the models' robustness to unseen weather conditions. The stereo consistency module ensures structural alignment across synthesized image pairs, preserving geometric integrity and enhancing depth estimation accuracy. Second, we design a robust feature encoder that combines a specialized ConvNet with a denoising transformer to extract stable and reliable features from degraded images. The ConvNet captures fine-grained local structures, while the denoising transformer refines global representations, effectively mitigating the impact of noise, low visibility, and weather-induced distortions. This enables more accurate disparity estimation even under challenging visual conditions. Extensive experiments demonstrate that \textbf{RobuSTereo} significantly improves the robustness and generalization of stereo matching models across diverse adverse weather scenarios.
Flow-Anything: Learning Real-World Optical Flow Estimation from Large-Scale Single-view Images
Jun 09, 2025Optical flow estimation is a crucial subfield of computer vision, serving as a foundation for video tasks. However, the real-world robustness is limited by animated synthetic datasets for training. This introduces domain gaps when applied to real-world applications and limits the benefits of scaling up datasets. To address these challenges, we propose \textbf{Flow-Anything}, a large-scale data generation framework designed to learn optical flow estimation from any single-view images in the real world. We employ two effective steps to make data scaling-up promising. First, we convert a single-view image into a 3D representation using advanced monocular depth estimation networks. This allows us to render optical flow and novel view images under a virtual camera. Second, we develop an Object-Independent Volume Rendering module and a Depth-Aware Inpainting module to model the dynamic objects in the 3D representation. These two steps allow us to generate realistic datasets for training from large-scale single-view images, namely \textbf{FA-Flow Dataset}. For the first time, we demonstrate the benefits of generating optical flow training data from large-scale real-world images, outperforming the most advanced unsupervised methods and supervised methods on synthetic datasets. Moreover, our models serve as a foundation model and enhance the performance of various downstream video tasks.
MAFE R-CNN: Selecting More Samples to Learn Category-aware Features for Small Object Detection
May 22, 2025Small object detection in intricate environments has consistently represented a major challenge in the field of object detection. In this paper, we identify that this difficulty stems from the detectors' inability to effectively learn discriminative features for objects of small size, compounded by the complexity of selecting high-quality small object samples during training, which motivates the proposal of the Multi-Clue Assignment and Feature Enhancement R-CNN.Specifically, MAFE R-CNN integrates two pivotal components.The first is the Multi-Clue Sample Selection (MCSS) strategy, in which the Intersection over Union (IoU) distance, predicted category confidence, and ground truth region sizes are leveraged as informative clues in the sample selection process. This methodology facilitates the selection of diverse positive samples and ensures a balanced distribution of object sizes during training, thereby promoting effective model learning.The second is the Category-aware Feature Enhancement Mechanism (CFEM), where we propose a simple yet effective category-aware memory module to explore the relationships among object features. Subsequently, we enhance the object feature representation by facilitating the interaction between category-aware features and candidate box features.Comprehensive experiments conducted on the large-scale small object dataset SODA validate the effectiveness of the proposed method. The code will be made publicly available.
Boosting Zero-shot Stereo Matching using Large-scale Mixed Images Sources in the Real World
May 13, 2025Stereo matching methods rely on dense pixel-wise ground truth labels, which are laborious to obtain, especially for real-world datasets. The scarcity of labeled data and domain gaps between synthetic and real-world images also pose notable challenges. In this paper, we propose a novel framework, \textbf{BooSTer}, that leverages both vision foundation models and large-scale mixed image sources, including synthetic, real, and single-view images. First, to fully unleash the potential of large-scale single-view images, we design a data generation strategy combining monocular depth estimation and diffusion models to generate dense stereo matching data from single-view images. Second, to tackle sparse labels in real-world datasets, we transfer knowledge from monocular depth estimation models, using pseudo-mono depth labels and a dynamic scale- and shift-invariant loss for additional supervision. Furthermore, we incorporate vision foundation model as an encoder to extract robust and transferable features, boosting accuracy and generalization. Extensive experiments on benchmark datasets demonstrate the effectiveness of our approach, achieving significant improvements in accuracy over existing methods, particularly in scenarios with limited labeled data and domain shifts.