 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyMod-LLVE: Low-Light Video Enhancement with Modality-Agnostic Inference
Jun 09, 2026Low-light video enhancement (LLVE) remains a challenging task due to severe information degradation under low-illumination conditions. Recent multimodal approaches have significantly improved enhancement performance by incorporating auxiliary modalities, such as event streams and infrared images. However, these methods typically assume the availability of these modalities at inference, which is often not feasible in real-world scenarios. To solve this problem, in this work, we propose AMNet, a unified multimodal framework for LLVE, to support flexible modality-agnostic inference, where auxiliary modalities may be unavailable. To address the issue of modality absence, we introduce a Spatial-Spectral Dual-Gated Translator that learns the correspondence between auxiliary modalities and RGB inputs, producing implicit auxiliary representations to support the robust enhancement. Additionally, to fully facilitate the learning of cross-modal correspondence, we conduct large-scale multimodal pretraining based on the RGB-only dataset with synthetic auxiliary modalities. Extensive experiments demonstrate that AMNet could handle arbitrary inference-time modality combinations and exhibits superior performance for LLVE under modality absence conditions. Code and models are available on the project page.
Impostor: An Agent-Curated Benchmark for Realistic AIGC Manipulation Localization
Jun 03, 2026Recent advances in generative image editing have improved the realism and controllability of localized image manipulation, raising new challenges for image manipulation detection and localization (IMDL). However, existing IMDL benchmarks still have limitations in visual realism, manipulation diversity, and generator coverage, making it difficult to reflect recent trends in image manipulation. To address these limitations, we introduce Impostor, a high-quality AI-edited image manipulation localization dataset containing 100K manipulated images. Impostor is constructed by CraftAgent, a closed-loop agent framework that integrates scene perception, editing planning, manipulation execution, quality validation, and iterative reflection to automatically generate diverse and visually realistic manipulated images. Moreover, Impostor contains images generated by seven recent AIGC models across three manipulation types and includes multiple manipulated regions, providing a more comprehensive benchmark for AIGC-based IMDL. Furthermore, we propose PhaseAware-Net (PANet), a semantic-forensic framework that introduces local phase modeling and semantic-forensic consistency learning to better localize semantically plausible yet forensically disrupted manipulated regions. Extensive experiments show that Impostor poses significant challenges to existing large vision-language models (LVLMs) and specialized IMDL methods, while PANet achieves superior performance on Impostor and multiple public benchmarks.
Let's Simplify Step by Step: Guiding LLM Towards Multilingual Unsupervised Proficiency-Controlled Sentence Simplification
Feb 07, 2026Large language models demonstrate limited capability in proficiency-controlled sentence simplification, particularly when simplifying across large readability levels. We propose a framework that decomposes complex simplifications into manageable steps through dynamic path planning, semantic-aware exemplar selection, and chain-of-thought generation with conversation history for coherent reasoning. Evaluation on five languages across two benchmarks shows our approach improves simplification effectiveness while reducing computational steps by 22-42%. Human evaluation confirms the fundamental trade-off between simplification effectiveness and meaning preservation. Notably, even human annotators struggle to agree on semantic preservation judgments, highlighting the inherent complexity of this task. Our work shows that while step-by-step simplification improves control, preserving semantic fidelity during extensive simplification remains an open challenge.
Rethinking the Detail-Preserved Completion of Complex Tubular Structures based on Point Cloud: a Dataset and a Benchmark
Aug 25, 2025



Complex tubular structures are essential in medical imaging and computer-assisted diagnosis, where their integrity enhances anatomical visualization and lesion detection. However, existing segmentation algorithms struggle with structural discontinuities, particularly in severe clinical cases such as coronary artery stenosis and vessel occlusions, which leads to undesired discontinuity and compromising downstream diagnostic accuracy. Therefore, it is imperative to reconnect discontinuous structures to ensure their completeness. In this study, we explore the tubular structure completion based on point cloud for the first time and establish a Point Cloud-based Coronary Artery Completion (PC-CAC) dataset, which is derived from real clinical data. This dataset provides a novel benchmark for tubular structure completion. Additionally, we propose TSRNet, a Tubular Structure Reconnection Network that integrates a detail-preservated feature extractor, a multiple dense refinement strategy, and a global-to-local loss function to ensure accurate reconnection while maintaining structural integrity. Comprehensive experiments on our PC-CAC and two additional public datasets (PC-ImageCAS and PC-PTR) demonstrate that our method consistently outperforms state-of-the-art approaches across multiple evaluation metrics, setting a new benchmark for point cloud-based tubular structure reconstruction. Our benchmark is available at https://github.com/YaoleiQi/PCCAC.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025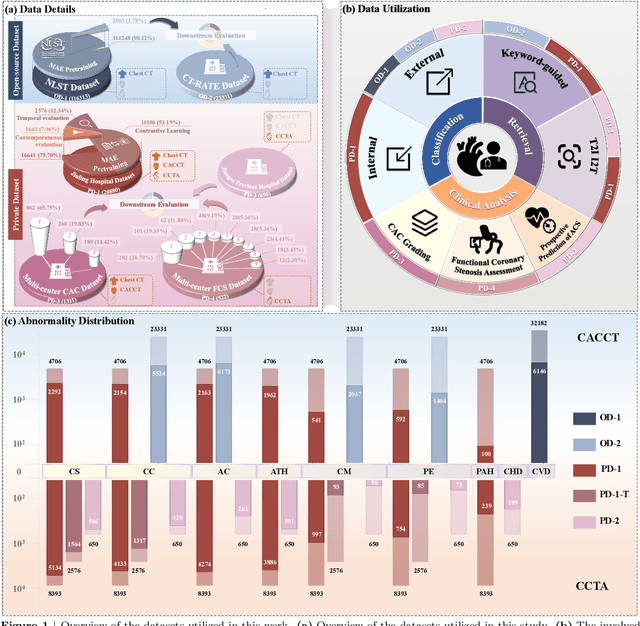
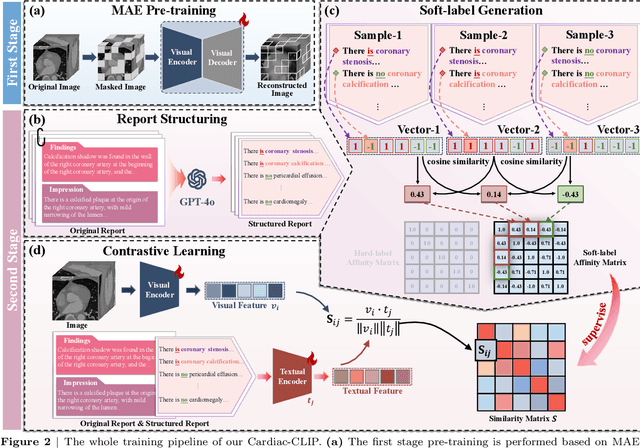
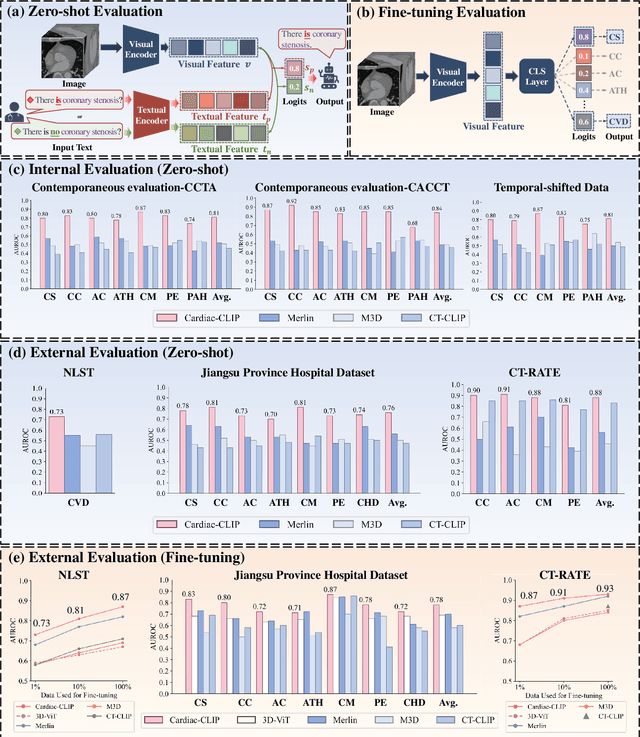
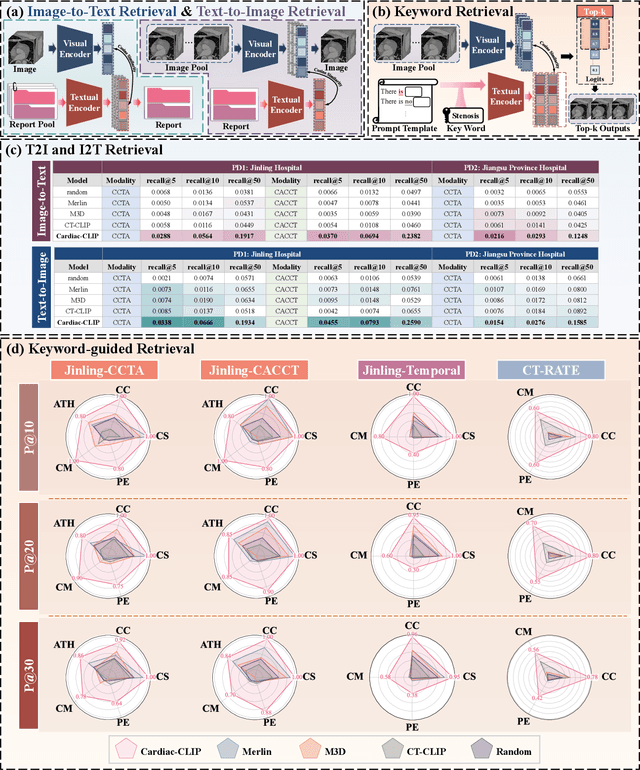
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
RobuSTereo: Robust Zero-Shot Stereo Matching under Adverse Weather
Jul 02, 2025Learning-based stereo matching models struggle in adverse weather conditions due to the scarcity of corresponding training data and the challenges in extracting discriminative features from degraded images. These limitations significantly hinder zero-shot generalization to out-of-distribution weather conditions. In this paper, we propose \textbf{RobuSTereo}, a novel framework that enhances the zero-shot generalization of stereo matching models under adverse weather by addressing both data scarcity and feature extraction challenges. First, we introduce a diffusion-based simulation pipeline with a stereo consistency module, which generates high-quality stereo data tailored for adverse conditions. By training stereo matching models on our synthetic datasets, we reduce the domain gap between clean and degraded images, significantly improving the models' robustness to unseen weather conditions. The stereo consistency module ensures structural alignment across synthesized image pairs, preserving geometric integrity and enhancing depth estimation accuracy. Second, we design a robust feature encoder that combines a specialized ConvNet with a denoising transformer to extract stable and reliable features from degraded images. The ConvNet captures fine-grained local structures, while the denoising transformer refines global representations, effectively mitigating the impact of noise, low visibility, and weather-induced distortions. This enables more accurate disparity estimation even under challenging visual conditions. Extensive experiments demonstrate that \textbf{RobuSTereo} significantly improves the robustness and generalization of stereo matching models across diverse adverse weather scenarios.
Flow-Anything: Learning Real-World Optical Flow Estimation from Large-Scale Single-view Images
Jun 09, 2025Optical flow estimation is a crucial subfield of computer vision, serving as a foundation for video tasks. However, the real-world robustness is limited by animated synthetic datasets for training. This introduces domain gaps when applied to real-world applications and limits the benefits of scaling up datasets. To address these challenges, we propose \textbf{Flow-Anything}, a large-scale data generation framework designed to learn optical flow estimation from any single-view images in the real world. We employ two effective steps to make data scaling-up promising. First, we convert a single-view image into a 3D representation using advanced monocular depth estimation networks. This allows us to render optical flow and novel view images under a virtual camera. Second, we develop an Object-Independent Volume Rendering module and a Depth-Aware Inpainting module to model the dynamic objects in the 3D representation. These two steps allow us to generate realistic datasets for training from large-scale single-view images, namely \textbf{FA-Flow Dataset}. For the first time, we demonstrate the benefits of generating optical flow training data from large-scale real-world images, outperforming the most advanced unsupervised methods and supervised methods on synthetic datasets. Moreover, our models serve as a foundation model and enhance the performance of various downstream video tasks.
Car-1000: A New Large Scale Fine-Grained Visual Categorization Dataset
Mar 16, 2025



Fine-grained visual categorization (FGVC) is a challenging but significant task in computer vision, which aims to recognize different sub-categories of birds, cars, airplanes, etc. Among them, recognizing models of different cars has significant application value in autonomous driving, traffic surveillance and scene understanding, which has received considerable attention in the past few years. However, Stanford-Car, the most widely used fine-grained dataset for car recognition, only has 196 different categories and only includes vehicle models produced earlier than 2013. Due to the rapid advancements in the automotive industry during recent years, the appearances of various car models have become increasingly intricate and sophisticated. Consequently, the previous Stanford-Car dataset fails to capture this evolving landscape and cannot satisfy the requirements of automotive industry. To address these challenges, in our paper, we introduce Car-1000, a large-scale dataset designed specifically for fine-grained visual categorization of diverse car models. Car-1000 encompasses vehicles from 165 different automakers, spanning a wide range of 1000 distinct car models. Additionally, we have reproduced several state-of-the-art FGVC methods on the Car-1000 dataset, establishing a new benchmark for research in this field. We hope that our work will offer a fresh perspective for future FGVC researchers. Our dataset is available at https://github.com/toggle1995/Car-1000.
FCaS: Fine-grained Cardiac Image Synthesis based on 3D Template Conditional Diffusion Model
Mar 12, 2025Solving medical imaging data scarcity through semantic image generation has attracted significant attention in recent years. However, existing methods primarily focus on generating whole-organ or large-tissue structures, showing limited effectiveness for organs with fine-grained structure. Due to stringent topological consistency, fragile coronary features, and complex 3D morphological heterogeneity in cardiac imaging, accurately reconstructing fine-grained anatomical details of the heart remains a great challenge. To address this problem, in this paper, we propose the Fine-grained Cardiac image Synthesis(FCaS) framework, established on 3D template conditional diffusion model. FCaS achieves precise cardiac structure generation using Template-guided Conditional Diffusion Model (TCDM) through bidirectional mechanisms, which provides the fine-grained topological structure information of target image through the guidance of template. Meanwhile, we design a deformable Mask Generation Module (MGM) to mitigate the scarcity of high-quality and diverse reference mask in the generation process. Furthermore, to alleviate the confusion caused by imprecise synthetic images, we propose a Confidence-aware Adaptive Learning (CAL) strategy to facilitate the pre-training of downstream segmentation tasks. Specifically, we introduce the Skip-Sampling Variance (SSV) estimation to obtain confidence maps, which are subsequently employed to rectify the pre-training on downstream tasks. Experimental results demonstrate that images generated from FCaS achieves state-of-the-art performance in topological consistency and visual quality, which significantly facilitates the downstream tasks as well. Code will be released in the future.
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM
Feb 14, 2024



Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in various multimodal tasks. However, their potential in the medical domain remains largely unexplored. A significant challenge arises from the scarcity of diverse medical images spanning various modalities and anatomical regions, which is essential in real-world medical applications. To solve this problem, in this paper, we introduce OmniMedVQA, a novel comprehensive medical Visual Question Answering (VQA) benchmark. This benchmark is collected from 75 different medical datasets, including 12 different modalities and covering more than 20 distinct anatomical regions. Importantly, all images in this benchmark are sourced from authentic medical scenarios, ensuring alignment with the requirements of the medical field and suitability for evaluating LVLMs. Through our extensive experiments, we have found that existing LVLMs struggle to address these medical VQA problems effectively. Moreover, what surprises us is that medical-specialized LVLMs even exhibit inferior performance to those general-domain models, calling for a more versatile and robust LVLM in the biomedical field. The evaluation results not only reveal the current limitations of LVLM in understanding real medical images but also highlight our dataset's significance. Our dataset will be made publicly available.